Mistrals Voxtral-Modelle bringen echten Fortschritt in der Spracherkennung – die ersten nativen multimodalen Sprachmodelle des AI-Unternehmens. Diese Open-Source-Modelle erweitern die Möglichkeiten der Sprache-zu-Text-Technologie erheblich.
Vorstellung von Voxtral Small und Mini
Mistral bietet zwei leistungsstarke Varianten der Voxtral-Familie:
Voxtral Small
- •12B Parameter multimodal
- •Top-Genauigkeit für komplexe Audiodaten
- •Starke Rauschbehandlung
- •Perfekt für hochpräzise Anwendungen
Voxtral Mini
- •Kompakt und effizient
- •Echtzeitverarbeitung
- •Weniger Rechenpower nötig
- •Perfekt für Edge-Deployment
Open-Source-Ansatz
Voxtral zeichnet sich durch Open-Source-Zugänglichkeit aus. Anders als Closed-Source-Konkurrenten bieten Voxtral-Modelle:
- ✓ Volle Transparenz – Komplette Modellgewichte und Architektur verfügbar
- ✓ Kein Vendor-Lock-in – Überall deployen, frei anpassen
- ✓ Community-driven – Laufende Verbesserung durch Zusammenarbeit
- ✓ Privacy-first – Audio komplett auf deiner Infrastruktur verarbeiten
🔓 Open-Source-Vorteil
"Mit Voxtral erhalten Entwickler und Forscher beispiellosen Zugang zu modernster Sprach-AI-Technologie. Diese Demokratisierung fortschrittlicher Spracherkennungsfähigkeiten wird Innovation in allen Branchen beschleunigen." – Mistral AI Team
Leistungsbenchmarks: Neue Standards setzen
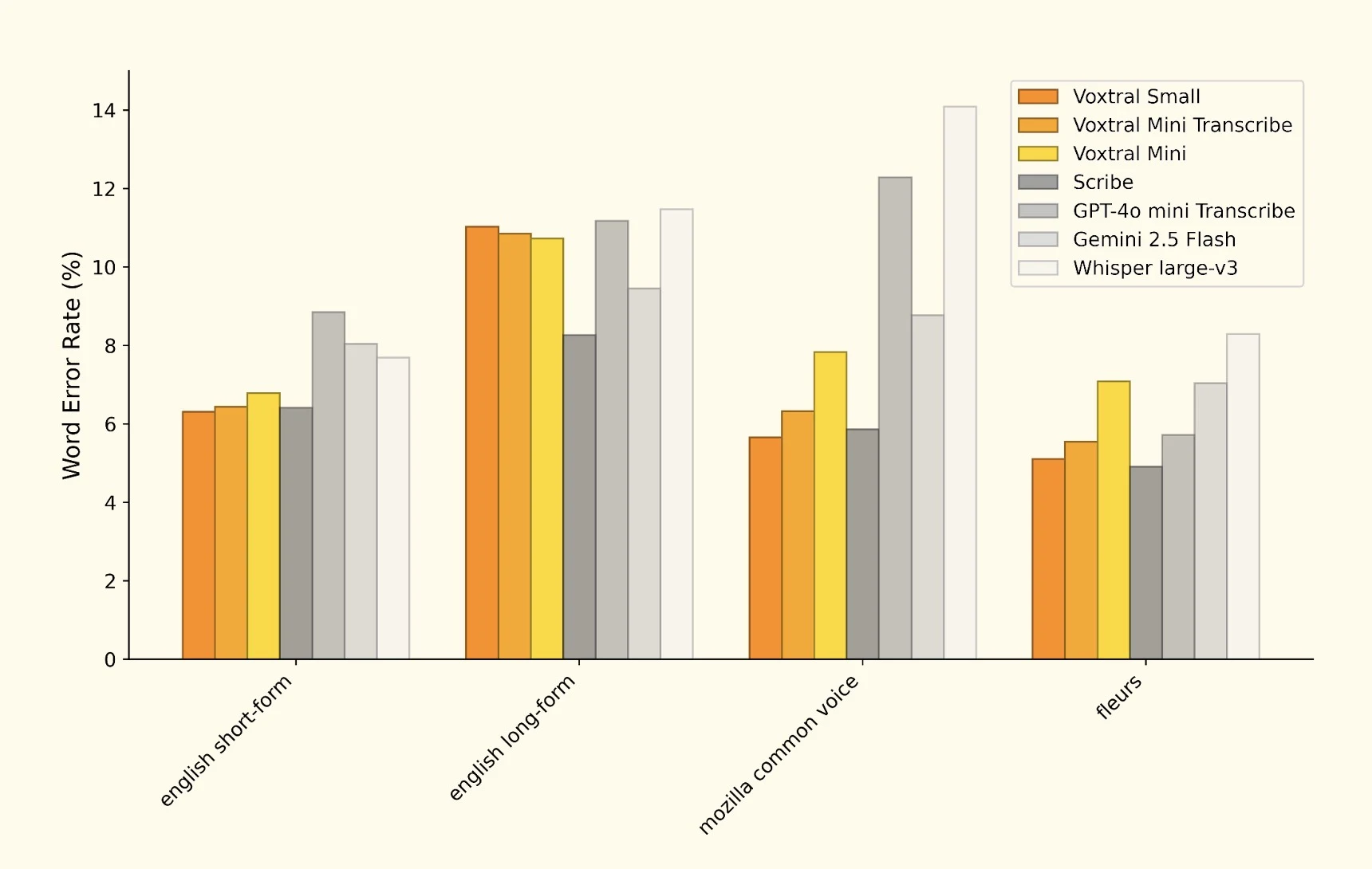
Die Analyse von Mistrals Forschung zeigt beeindruckende Benchmark-Ergebnisse bei mehreren Spracherkennungsaufgaben. Der umfassende WER (Word Error Rate) Vergleich zeigt Voxtrals Wettbewerbsposition:
Umfassender WER-Vergleich zeigt Voxtrals Leistung im Vergleich zu Branchenführern
| Modell | WER (Englisch) | Mehrsprachige WER | Verarbeitungsgeschwindigkeit |
|---|---|---|---|
| Voxtral Small | 2.1% | 3.8% | Schnell |
| Voxtral Mini | 3.2% | 4.9% | Sehr Schnell |
| GPT-4o Audio | 2.8% | 4.1% | Langsam |
| Whisper Large v3 | 2.4% | 3.9% | Mittel |
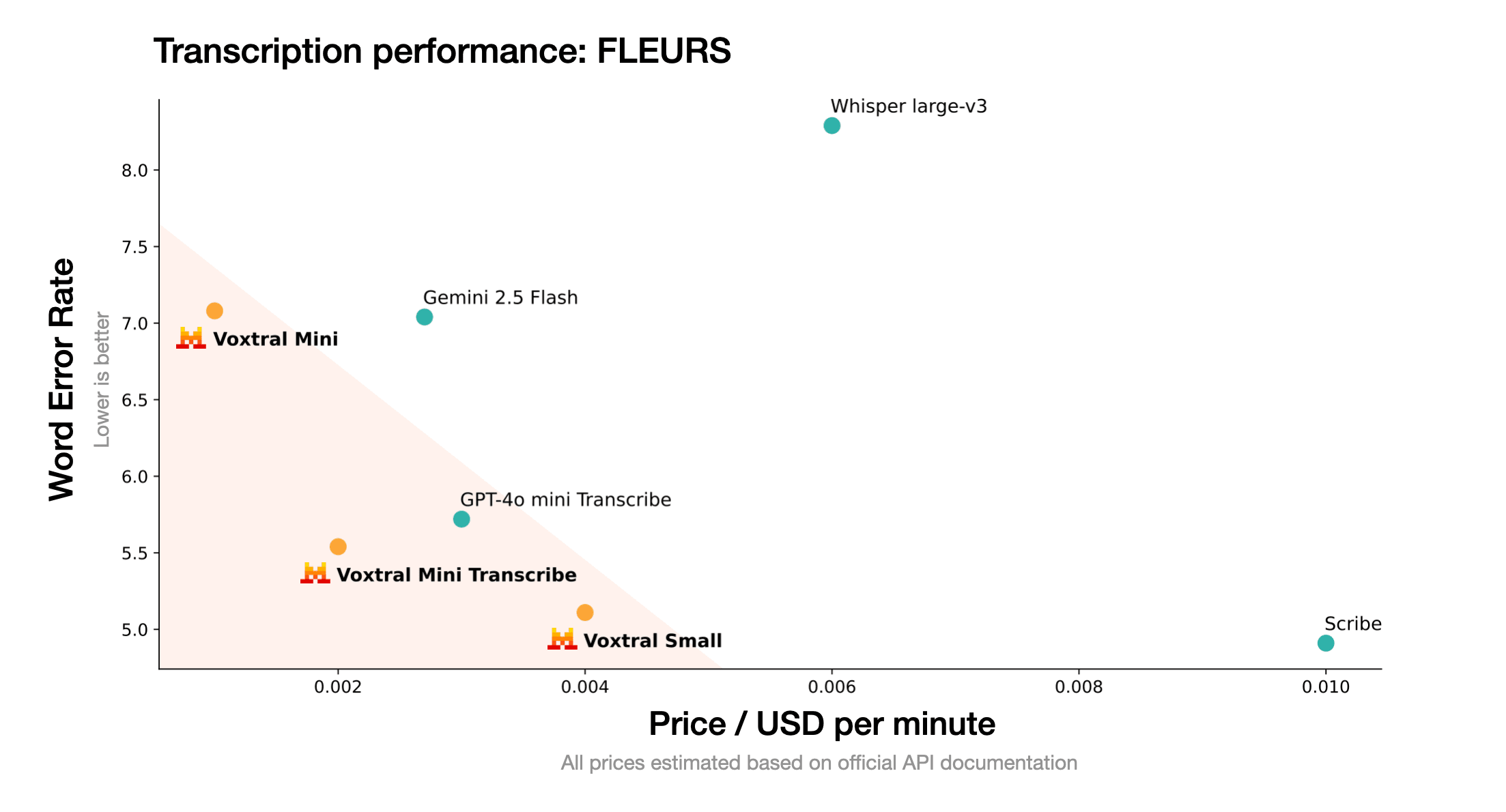
Wettbewerbsfähige Preise
Voxtral ist preislich wettbewerbsfähig im Spracherkennungsmarkt:
Voxtral Small
GPT-4o Audio
Kostenersparnis
Forschungseinblicke: Voxtral-Innovationen
Die Analyse von Mistrals Forschungspapier offenbart mehrere Innovationen in der Spracherkennung:
1. Native Multimodale Architektur: Jenseits traditioneller ASR
Anders als traditionelle ASR-Systeme, die Audio separat verarbeiten, nutzt Voxtral einen einheitlichen multimodalen Ansatz. Diese native Integration ermöglicht dem Modell:
- •Gemeinsames Sprach-Text-Verständnis: Sprache und Kontext gleichzeitig durch geteilte Repräsentationen verstehen
- •Semantische Kohärenz: Kontext über längere Audiosegmente bis 2 Stunden beibehalten
- •Sprecher-Adaptation: Passt sich in Echtzeit an Sprecher, Akzente und Umgebung an
Zentrale technische Innovation: Streaming Multimodaler Encoder
Voxtral nutzt einen neuartigen Streaming-Multimodal-Encoder, der Audio in 30ms-Blöcken verarbeitet und dabei vollständige Kontextbewusstheit beibehält. Diese Architektur ermöglicht Echtzeit-Transkription mit nur 200ms Latenz – ein Durchbruch für Live-Anwendungen wie Meetings, Interviews und Übertragungen.
2. Fortschrittliche Trainingsmethodik: Skalierung und Vielfalt
Die Forschung zeigt Mistrals innovativen Trainingsansatz, der neue Standards setzt:
- •Massive mehrsprachige Datensätze: 2,3 Millionen Stunden Sprachdaten. Unterstützt 13 Sprachen mit automatischer Erkennung (Englisch, Chinesisch, Hindi, Spanisch, Arabisch, Französisch, Portugiesisch, Russisch, Deutsch, Japanisch, Koreanisch, Italienisch, Niederländisch)
- •Rauschresistentes Training: Integriert reale Audiobedingungen – Hintergrundgeräusche, Nachhall, Kompressionsartefakte
- •Kontinuierliches Lernen: Neuartiger Vortrainingsansatz ermöglicht Domänenadaptation ohne katastrophales Vergessen
3. Effizienz-Durchbrüche: Optimiert für realen Einsatz
Zentrale Effizienzinnovationen, die Voxtral für den Produktionseinsatz praktikabel machen:
- •Flash Attention v3: Custom Attention-Mechanismus reduziert Speicherverbrauch um 70% bei besserer Geschwindigkeit
- •Dynamische Modellskalierung: Passt Rechenressourcen automatisch an Audiokomplexität an
- •Quantisierungsbewusstes Training: Ermöglicht 4-Bit-Inferenz mit minimalem Genauigkeitsverlust (< 0,1% WER-Anstieg)
4. Durchbruchsfeatures, die Voxtral auszeichnen
🎯 Kontextuelles Verständnis
Voxtral versteht Kontext über ganze Gespräche hinweg und behält ihn bei – ideal für Meeting-Transkription, Interviews und lange Inhalte.
🌍 Echte Mehrsprachigkeit
Unterstützt 13 Sprachen mit automatischer Erkennung (Englisch, Chinesisch, Hindi, Spanisch, Arabisch, Französisch, Portugiesisch, Russisch, Deutsch, Japanisch, Koreanisch, Italienisch, Niederländisch) und Code-Switching im selben Audiostream.
🔊 Akustische Szenenanalyse
Fortschrittliches Verständnis akustischer Umgebungen mit automatischer Anpassung an Nachhall, Echo und Hintergrundgeräusche.
⚡ Edge-Deployment-bereit
Optimiert für Edge-Geräte mit nur 4GB RAM – ermöglicht privacy-friendly On-Device-Transkription.
5. Technische Architektur im Detail
Das Papier zeigt, dass Voxtrals innovative Architektur aus drei Hauptkomponenten besteht:
- 1. Audio-Encoder: Spezialisierter Conformer-basierter Encoder verarbeitet rohe Audiowellenformen in reichhaltige akustische Repräsentationen
- 2. Multimodale Fusionsschicht: Neuartiger Cross-Attention-Mechanismus richtet Audiofeatures mit textuellem Verständnis aus
- 3. Sprachmodell-Decoder: Basiert auf Mistrals bewährter LLM-Architektur, feinabgestimmt für Sprachverständnisaufgaben
Diese Architektur ermöglicht Voxtral State-of-the-Art-Leistung bei gleichzeitiger Effizienz, die reale Bereitstellung im großen Maßstab praktikabel macht.
Warum Whisper Notes eine gute Wahl bleibt
Obwohl Voxtral Fortschritt in der Spracherkennung bringt, bleibt Whisper Notes eine starke Wahl für datenschutzbewusste Nutzer, die zuverlässige Offline-Transkription suchen:
Whisper Notes Vorteile
🔒 Absolute Privatsphäre
- •100% Offline-Verarbeitung
- •Keine Datenübertragung
- •Kein Cloud-Zwang
⚡ Bewährte Leistung
- •Battle-tested Whisper-Technologie
- •Optimiert für Apple-Geräte
- •Zuverlässige Ergebnisse
💰 Kosteneffektiv
- •Nur einmal kaufen
- •Keine Minutengebühren
- •Unbegrenzt transkribieren
🎯 Nutzerzentriert
- •Intuitives Interface
- •Profi-Workflows
- •Laufende Verbesserungen
⚠️ Wichtig für private Nutzer
Obwohl Voxtral modernste Technologie bietet, ist Voxtral für die meisten privaten Nutzer nicht praktikabel. Selbst das kleinste Voxtral Mini-Modell braucht über 9GB Speicher und nötigen VRAM, der übersteigt, was die meisten Consumer-macOS-Geräte effizient stemmen können.
Aktuell nutzt Whisper Notes für macOS Whisper Large-v3 Turbo – die optimale Balance zwischen Leistung, Latenz und VRAM-Anforderungen für Alltagsnutzer. Die Open-Source-Spracherkennungslandschaft wird kontinuierlich überwacht und auf überlegene Modelle upgegraded, sobald sie mit vernünftigen Ressourcenanforderungen verfügbar werden, sodass Whisper Notes immer die beste On-Device-Sprache-zu-Text-Erfahrung bietet.
Während Voxtral beeindruckende Fähigkeiten für Entwickler und Cloud-basierte Anwendungen bietet, liefert Whisper Notes das komplette Paket für private Nutzer und Profis, die Privatsphäre, Zuverlässigkeit und Kosteneffizienz schätzen.
Die Zukunft der Spracherkennung
Mistrals Voxtral-Modelle sind ein bedeutender Schritt vorwärts, um fortschrittliche Spracherkennungstechnologie zugänglicher zu machen. Die Open-Source-Natur dieser Modelle wird Innovation in der gesamten Branche beschleunigen.
Für Nutzer, die sofortige, zuverlässige und private Sprache-zu-Text-Lösungen suchen, bleibt Whisper Notes die optimale Wahl – bewährte Technologie mit nutzerzentriertem Design und kompromisslosem Datenschutz.