Pertuturan ke teks luar talian kini praktikal pada perkakasan Apple harian: audio kekal pada peranti anda, rakaman panjang siap dalam beberapa saat atau minit, dan tiada bil per minit.

Model transkripsi lokal yang berjalan pada Apple Silicon
Jawapan Ringkas: Pertuturan ke Teks Luar Talian Terbaik Mengikut Platform
Jika anda cuma mahukan jawapannya: pada Mac dan iPhone, gunakan Whisper Notes — tiga enjin AI lokal dengan pembelian sekali bayar $6.99 setiap platform; versi Mac disertakan percubaan 10,000 perkataan. Pada Windows, gunakan Buzz atau faster-whisper (percuma, sumber terbuka). Pada Android, pilihan masih terhad — lihat bahagian platform di bawah. Setiap alat dalam jadual ini berjalan 100% luar talian:
| Alat | Platform | Harga | Persediaan | Model |
|---|---|---|---|---|
| Whisper Notes | Mac (M-series), iPhone | $6.99 setiap platform; percubaan 10,000 perkataan pada Mac | Tiada — aplikasi natif | Parakeet V3, SenseVoice, Whisper Turbo |
| MacWhisper | Mac sahaja | Ada peringkat percuma; Pro €64 sekali bayar | Tiada — aplikasi natif | Keluarga Whisper |
| Buzz | Windows, Mac, Linux | Percuma (sumber terbuka) | Pemasang; UI asas | Keluarga Whisper |
| faster-whisper / whisper.cpp | Windows, Mac, Linux | Percuma (sumber terbuka) | Baris arahan | Keluarga Whisper |
| Apple Dictation | Terbina dalam iPhone/Mac | Percuma | Tiada | Model pada peranti Apple; untuk dikte pendek sahaja |
Selebihnya panduan ini menerangkan mengapa transkripsi lokal menang dari segi latensi, kos dan privasi — dengan angka penanda aras sebenar — dan menunjukkan cara transkripsi audio ke teks secara luar talian, langkah demi langkah.
Masalah Latensi
Saluran transkripsi awan: anda bercakap, audio dimuat naik ke pelayan, API memprosesnya, hasilnya dihantar semula. Perkhidmatan "masa nyata" sekalipun menambah 2-3 saat perjalanan pergi-balik rangkaian untuk rakaman 10 saat.
Transkripsi lokal: semua latensi itu lenyap. Audio tidak pernah meninggalkan peranti anda, pemprosesan berlaku terus pada cip, dan hasilnya muncul serta-merta. Tiada muat naik, tiada menunggu, tiada penunjuk "memproses" yang berpusing.
iPhone terkini dan Mac Apple Silicon dilengkapi perkakasan Neural Engine khusus untuk pembelajaran mesin pada peranti. Transkripsi lokal menggunakan perkakasan yang sudah anda miliki, bukannya menunggu muat naik dan respons daripada pelayan jauh.
Pada 2019, transkripsi awan masuk akal. Telefon anda tidak mampu menjalankan rangkaian neural berbilion parameter. Kekangan itu sudah tiada. iPhone 15 Pro menjalankan model Whisper lebih pantas daripada kebanyakan perkhidmatan awan memulangkan hasil. MacBook M3 memproses 60 minit audio dalam 5 minit — secara lokal, luar talian, tanpa muat naik.
Transkripsi awan masih masuk akal untuk kolaborasi langsung dan aliran kerja berpusat. Untuk rakaman peribadi yang hanya anda perlukan, muat naik selalunya tidak perlu.
Anda Sudah Membayar Cip Itu
Ada satu perkara yang sepatutnya mengganggu anda.
Apple mengenakan harga premium untuk cip M3. Anda sudah membayarnya. Neural Engine itu? Milik anda. 18 bilion transistor yang dioptimumkan untuk pembelajaran mesin? Kepunyaan anda.
Kemudian anda membayar $10/bulan kepada Otter.ai untuk transkripsi audio di pelayan mereka.
Anda menyewa perkakasan orang lain sedangkan anda sudah memiliki perkakasan yang lebih pantas. Ini seperti membeli kereta sport tetapi masih membayar tambang teksi setiap hari.
Ekonomi transkripsi awan masuk akal ketika inferens lokal mustahil. Kini ia sekadar cukai atas inersia. Dalam tempoh tiga tahun, langganan $10/bulan menelan $360. Whisper Notes berharga $6.99 sekali sahaja. Ketepatan sama. Pemprosesan lebih pantas. Cip anda melakukan kerja yang memang direka untuknya.
| Perkhidmatan | Tahun 1 | Tahun 3 | Tahun 5 |
|---|---|---|---|
| Langganan awan ($10/bulan) | $120 | $360 | $600 |
| Whisper Notes (sekali bayar) | $6.99 | $6.99 | $6.99 |
Kami tidak mengenakan langganan kerana kami tidak mengendalikan pelayan. Audio anda tidak pernah menyentuh infrastruktur kami. Tiada apa-apa untuk dicaj setiap bulan.
Kebocoran Data Ialah Hal Seni Bina
Mari berterus terang tentang privasi.
Apabila anda menggunakan perkhidmatan transkripsi awan, audio anda berada di pelayan orang lain. Pelayan itu ada kakitangan yang boleh mengaksesnya. Pelayan itu bersambung ke rangkaian. Rangkaian itu berdepan serangan. Kebocoran data bukan kemalangan — ia kepastian seni bina apabila data sensitif disimpan di infrastruktur pihak ketiga.
Data suara membawa risiko yang unik. Tidak seperti kata laluan, anda tidak boleh menetapkan semula suara anda. Corak vokal anda ialah pengecam biometrik yang kekal. Sekali bocor, ia terjejas selama-lamanya. Penyerang boleh menggunakan cap suara untuk memintas pengesahan, melakukan penipuan identiti atau menjana deepfake.
Satu-satunya cara menghapuskan risiko ini ialah menghapuskan muat naik itu sendiri. Audio yang tidak pernah meninggalkan peranti anda tidak mungkin menjadi sebahagian daripada kebocoran di pihak pelayan. Ini bukan ciri — ini fizik.
Fikirkan siapa yang merakam audio sensitif:
- Peguam yang merakam perundingan klien
- Ahli terapi yang mendokumentasikan sesi pesakit
- Wartawan yang melindungi sumber
- Eksekutif yang merakam perbincangan strategik
- Doktor yang mencatat sejarah pesakit
Bagi golongan profesional ini, storan awan bukan sekadar menyusahkan — ia liabiliti. Transkripsi lokal bukan pilihan citarasa. Ia satu keperluan.
Ketepatan dan Tolak Ansurnya
Kami perlu jujur tentang apa yang transkripsi lokal lakukan dengan baik dan di mana ia masih kurang.
Apa yang Whisper lokal buat lebih baik: Transkripsi verbatim. Jika anda perlukan rekod tepat apa yang diucapkan — setiap perkataan, setiap jeda, setiap "um" — model Whisper lokal sangat cemerlang. Kadar ralat perkataan 5-8% pada audio bersih setanding dengan penyalin manusia. Transkripnya setia kepada apa yang benar-benar dituturkan.
Apa yang AI awan buat lebih baik: Rumusan dan pengekstrakan. GPT-4o boleh mendengar mesyuarat lalu menghasilkan senarai tindakan, ringkasan dan tugasan susulan. Ia memahami konteks melangkaui perkataan literal. Jika yang anda mahu ialah "beritahu saya keputusan apa yang telah dibuat", AI awan memang lebih baik.
Tolak ansur ini nyata. Jika aliran kerja anda ialah "transkripsi → rumus dengan Claude/GPT", anda mendapat yang terbaik daripada kedua-duanya: transkrip lokal yang tepat, ringkasan pintar daripada awan. Audio mentah anda kekal peribadi. Hanya teks yang anda pilih untuk dikongsi meninggalkan peranti anda.
AI lokal tidak menyelesaikan setiap bahagian aliran kerja. Model pertuturan mahir dalam transkripsi; model bahasa lebih baik dalam merumus dan menaakul hasilnya. Simpan audio secara lokal, kemudian pilih model bahasa lokal atau awan mengikut tahap sensitiviti teks berkenaan.
| Tugas | Alat Terbaik | Sebab |
|---|---|---|
| Transkrip verbatim | Whisper lokal | Privasi, kelajuan, ketepatan |
| Ringkasan mesyuarat | LLM awan (atas transkrip) | Pemahaman kontekstual |
| Pengekstrakan senarai tindakan | LLM awan (atas transkrip) | Penaakulan semantik |
| Kolaborasi masa nyata | Perkhidmatan awan (Otter dll.) | Penyelarasan berbilang pengguna |
Angka Kelajuan Sebenar
Pilihan model mengubah hasil lebih daripada yang dibayangkan oleh perkataan "lokal". Parakeet ialah lalai yang pantas untuk bahasa Inggeris dan bahasa Eropah, SenseVoice dioptimumkan untuk bahasa Cina, Jepun, Korea dan Kantonis, manakala Whisper Large-v3 Turbo menyediakan liputan bahasa paling luas, lebih 100 bahasa, termasuk bahasa Melayu.
| Peranti dan model | Audio ujian | Masa pemprosesan | Paling sesuai untuk |
|---|---|---|---|
| M4 Pro — Parakeet V3 | 35 minit | ~20 saat | Bahasa Inggeris dan bahasa Eropah |
| M4 Pro — SenseVoice | Podcast Cina 27 minit | 13.83 saat | Cina, Jepun, Korea, Kantonis |
| M4 Pro — Whisper Turbo | Podcast Cina 27 minit | 2 minit 4 saat | Liputan bahasa paling luas |
Kaedah: Whisper Notes pada Apple M4 Pro dengan RAM 32 GB, masa sebenar dari mula transkripsi hingga teks akhir. Parakeet menggunakan rakaman 35 minit; SenseVoice dan Whisper menggunakan podcast Cina 27 minit yang sama. Ini ujian produk, bukan penanda aras merentas vendor awan.
Penyenaraian App Store semasa turut melaporkan kira-kira 18 saat untuk 5 minit audio dengan Parakeet pada iPhone 15, berbanding kira-kira satu minit dengan Whisper. Peranti yang lebih lama memang lebih perlahan. Dalam setiap kes, kerja terus berjalan dalam mod pesawat kerana tiada langkah muat naik.
Cara Transkripsi Audio ke Teks Secara Luar Talian (Langkah demi Langkah)
Pada Mac:
- Muat turun Whisper Notes untuk Mac (percubaan percuma, tanpa akaun).
- Pilih model dalam Tetapan: Parakeet V3 untuk kelajuan bahasa Inggeris, SenseVoice untuk bahasa Cina, Jepun, Korea atau Kantonis, Whisper Large V3 Turbo untuk lebih 100 bahasa, termasuk bahasa Melayu. Model dimuat turun sekali, kemudian berfungsi luar talian.
- Rakam terus, atau masukkan sebarang fail audio atau video (MP3, WAV, M4A, MP4).
- Untuk mesyuarat dalam talian, aktifkan pengesanan mesyuarat. Zoom, Teams dan Google Meet dikesan secara automatik; audio sistem dan mikrofon anda dirakam bersama, dan transkripsi kekal pada Mac anda.
- Teks muncul sedikit demi sedikit semasa diproses. Eksport sebagai TXT atau SRT, atau salin ke mana-mana sahaja.
Pada iPhone: pasang Whisper Notes dari App Store, rakam atau import dari Memo Suara dan aplikasi Fail, dan transkripsi berjalan pada cip A-series. Hidupkan mod pesawat terlebih dahulu jika anda mahukan bukti bahawa tiada apa-apa dimuat naik.
Bagaimana Kami Membinanya
Whisper Notes ialah pelaksanaan kami terhadap prinsip-prinsip ini. Beberapa keputusan khusus yang wajar disebut:
Widget Skrin Kunci
Idea terbaik sering tiba pada saat yang tidak sesuai. Kami membina widget skrin kunci supaya anda boleh mula merakam dengan satu ketukan — tanpa membuka aplikasi, tanpa pengesahan, tanpa menyemak sambungan. Pemprosesan lokal bermakna sedia serta-merta.
Satu ketukan untuk merakam. Sifar kebergantungan rangkaian.
Model Adaptif Perkakasan
Mac ada ruang haba dan kuasa yang mencukupi. iPhone pula berada dalam poket anda. Kedua-duanya kini menjalankan barisan model yang sama — Parakeet V3 (lalai), Whisper Large-v3 Turbo (809 juta parameter) dan SenseVoice — setiap satu ditala untuk perkakasannya. Jaminan privasi yang sama, penggunaan sumber yang bersesuaian.
Data Anda, Fail Anda
Transkrip ialah fail pada peranti anda. Format standard, lokasi standard. Tiada pangkalan data proprietari, tiada kunci masuk vendor. Jika Whisper Notes hilang esok, rakaman anda tetap boleh diakses. Eksport pukal bukan ciri premium — ia keadaan semula jadi data yang anda miliki.
Data anda. Format anda. Destinasi anda.
Perbendaharaan Kata Tersuai
Jargon teknikal, nama luar biasa, istilah khusus bidang — perbendaharaan kata yang paling memerlukan transkripsi tepat selalunya yang paling anda tidak mahu muat naik. Prompt awal membolehkan anda menambah konteks secara lokal. Model menyesuaikan diri tanpa terminologi anda menjadi data latihan sesiapa.
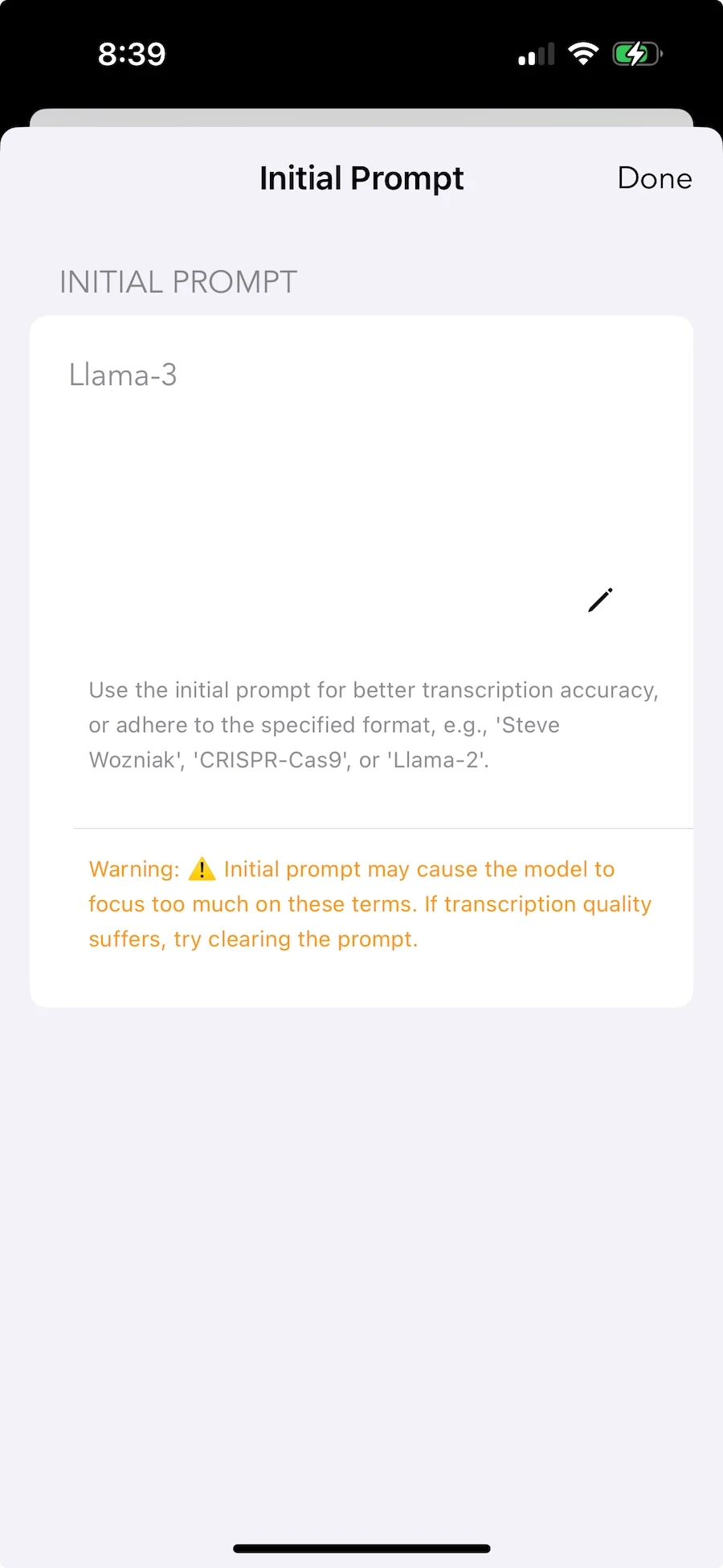
Pemperibadian lokal. Perbendaharaan kata anda kekal peribadi.
Bila Awan Lebih Baik
Kami tidak berpura-pura transkripsi lokal lebih baik dalam semua keadaan. Awan ada kelebihan sebenar:
Kolaborasi pasukan masa nyata. Lima orang menyunting satu transkrip serentak semasa mesyuarat memerlukan penyelarasan pelayan. Alat lokal secara semula jadi untuk pengguna tunggal.
Pengecaman penutur pada skala besar. "Siapa cakap apa" dalam rakaman berbilang penutur mendapat manfaat daripada data latihan skala awan. Diarisasi pada peranti wujud tetapi dengan ketepatan lebih rendah untuk kumpulan besar.
Automasi aliran kerja. Perkhidmatan awan bersambung ke CRM, mengekstrak senarai tindakan, menghantar ringkasan ke Slack. Alat lokal menghasilkan fail teks — apa yang anda buat dengannya adalah manual.
Perkakasan lama. iPhone sebelum A14, Mac Intel — sesetengah peranti tidak mampu menjalankan inferens lokal secara praktikal. Awan kekal satu-satunya pilihan.
Jika keperluan utama anda ialah kolaborasi pasukan semasa mesyuarat langsung, alat awan mungkin lebih baik. Jika anda kebanyakannya transkripsi rakaman sendiri dan privasi penting bagi anda, pemprosesan lokal lebih sesuai.
Hala Tuju
Setiap generasi cip membawa prestasi Neural Engine yang lebih tinggi. Setiap lelaran model membawa kecekapan yang lebih baik. Jurang antara lokal dan awan semakin sempit manakala kelebihan privasi dan latensi kekal.
Transkripsi awan masuk akal ketika telefon anda tidak mampu melakukan kerja itu. Era itu berakhir sekitar 2022. Yang tinggal ialah inersia — langganan pada autobayar, aliran kerja yang dibina atas andaian pelayan, dan kepercayaan samar bahawa awan mesti lebih baik.
Persoalannya bukan sama ada transkripsi lokal berfungsi. Ia berfungsi. Persoalannya ialah sama ada anda mahu terus membayar sewa ke atas perkakasan yang sudah anda miliki.
Butiran Teknikal
Keperluan peranti: iOS 18 atau lebih baharu (iPhone 12 atau lebih baharu disyorkan) atau Mac dengan Apple Silicon.
Model: Parakeet V3 untuk 25 bahasa Eropah, SenseVoice Small untuk bahasa Cina, Jepun, Korea dan Kantonis, dan Whisper Large V3 Turbo untuk lebih 100 bahasa, termasuk bahasa Melayu. Ketiga-tiga keluarga enjin ini berjalan secara lokal pada Mac dan iPhone.
Kelajuan: Parakeet V3: audio 35 minit dalam 20 saat pada M4 Pro. SenseVoice: podcast Cina 27 minit dalam 14 saat. Whisper Turbo: 35 minit dalam ~3 minit.
AI lokal pada Mac: Versi DMG boleh memuat turun Gemma 4 untuk merumuskan rakaman, menjana tajuk dan menjawab soalan tentang transkrip tanpa API awan.
Harga: $6.99 sekali bayar setiap platform. Mac disertakan percubaan 10,000 perkataan; iOS dan Mac ialah pembelian berasingan.
Pertuturan ke Teks Luar Talian pada Windows dan Android
Whisper Notes dibina untuk Apple Silicon, jadi ia berjalan pada Mac dan iPhone sahaja. Pada platform lain, pilihan semasa ialah:
Windows: pilihan percuma terbaik ialah Buzz (GUI ringkas untuk Whisper) dan faster-whisper (baris arahan, beberapa kali lebih pantas daripada pelaksanaan rujukan pada perkakasan yang sama). Kedua-duanya berjalan sepenuhnya luar talian selepas model dimuat turun. Jangkakan persediaan yang lebih menyusahkan daripada aplikasi natif — persekitaran Python, fail model, pemacu GPU jika anda mahukan kelajuan.
Android: whisper.cpp ada port Android dan beberapa aplikasi pembungkus, tetapi kualiti dan penyelenggaraannya tidak menentu. Belum ada aplikasi transkripsi luar talian arus perdana yang benar-benar kemas di Android — lihat status Whisper Notes untuk Android untuk kedudukan terkini.
Ramai yang mencari "Whisper Notes Windows"mahu model luar talian, Satu kali pembelian yang sama pada PC. Kami mendengar anda-tetapi kami lebih suka mengatakan — belum" daripada menghantar sesuatu yang perlahan (penjelasan penuh mengenai Whisper Notes untuk Windows halaman). Enjin Neural Apple adalah apa yang membuat 100x- transkripsi tempatan masa nyata mungkin hari ini.
Terjemahan Pertuturan Luar Talian: Apa yang AI Lokal Boleh dan Tidak Boleh Buat
Ada soalan berkaitan yang sering timbul: bolehkah AI lokal menterjemah pertuturan, bukan sekadar transkripsi? Sebahagiannya. Model Whisper Large V3 asal dilatih untuk dua tugas — transkripsi dan terjemahan daripada mana-mana bahasa ke bahasa Inggeris. Dijalankan secara lokal, ia boleh menerima audio bahasa Perancis, Jepun atau Arab dan mengeluarkan teks bahasa Inggeris, sepenuhnya luar talian. Dua peringatan: ia hanya menterjemah ke bahasa Inggeris (bukan arah sebaliknya), dan keupayaan ini ada pada model Large V3 penuh — varian yang lebih pantas, Large-v3 Turbo, menggugurkan tugas terjemahan untuk mengkhusus dalam transkripsi.
Terjemahan pertuturan luar talian masih di peringkat awal. Belum ada aplikasi pengguna yang diguna pakai secara meluas yang menyamai terjemahan suara-ke-suara masa nyata gaya awan sambil kekal sepenuhnya luar talian. Aliran kerja praktikal hari ini ialah dua langkah: transkripsi secara lokal, kemudian terjemahkan teks yang terhasil dengan alat yang anda percayai. Audio mentah tidak pernah perlu meninggalkan peranti anda.
Soalan Lazim
Bolehkah transkripsi dibuat tanpa sambungan internet?
Boleh. Whisper Notes ialah perisian transkripsi luar talian yang berjalan sepenuhnya pada peranti anda. Ketiga-tiga model AI — Parakeet V3, SenseVoice dan Whisper — memproses audio secara lokal menggunakan Neural Engine Mac anda atau cip A-series iPhone anda. Tiada data dimuat naik, tiada pelayan dihubungi. Anda boleh mengujinya sendiri dengan mengaktifkan mod pesawat.
Adakah OpenAI Whisper berfungsi luar talian?
Ya. OpenAI mengeluarkan Whisper sebagai model sumber terbuka, bermakna ia boleh berjalan secara lokal pada perkakasan anda. Whisper Notes membungkus Whisper Large V3 Turbo untuk berjalan pada Apple Silicon melalui CoreML/Metal — tanpa Python, tanpa baris arahan, tanpa internet. Menyokong pengecaman pertuturan luar talian dalam lebih 100 bahasa, termasuk bahasa Melayu. Untuk huraian mendalam tentang keluarga model ini, lihat panduan transkripsi Whisper kami.
Adakah Whisper Notes tersedia untuk Windows atau Android?
Belum lagi. Whisper Notes kini menyokong Mac (M-series) dan iPhone (12+). Untuk Windows, alternatif termasuk faster-whisper (baris arahan) atau Buzz (GUI). Kami mungkin menyokong platform lain pada masa hadapan, tetapi Neural Engine Apple Silicon memberikan pengalaman pertuturan ke teks lokal terbaik untuk pengguna Mac buat masa ini.
Adakah aplikasi transkripsi luar talian percuma?
Whisper Notes menawarkan percubaan percuma 10,000 perkataan pada Mac. Selepas itu, aplikasi Mac berharga $6.99 sekali bayar; aplikasi iPhone ialah pembelian berasingan $6.99. Kedua-dua platform tiada langganan.
Bagaimana Whisper Notes berbanding dengan MacWhisper atau faster-whisper?
MacWhisper ialah antara muka Whisper untuk Mac sahaja. faster-whisper ialah alat baris arahan. Whisper Notes menyertakan Parakeet V3, SenseVoice dan Whisper pada Mac dan iPhone, serta dikte kekunci Fn pada Mac dan rakaman dari skrin kunci pada iPhone. Setiap platform ialah pembelian sekali bayar $6.99 yang berasingan.
Apakah perisian pertuturan ke teks luar talian terbaik?
Bergantung pada platform anda. Pada Mac dan iPhone, Whisper Notes menawarkan tiga enjin lokal pada harga $6.99 setiap platform, dengan percubaan 10,000 perkataan pada Mac. Pada Windows atau Linux, Buzz (GUI) atau faster-whisper (baris arahan) adalah percuma dan sumber terbuka. Dikte terbina dalam memadai untuk nota pendek, tetapi ia tidak direka untuk rakaman panjang.
Bolehkah saya menukar audio kepada teks secara luar talian dengan percuma?
Boleh. Whisper Notes untuk Mac ada percubaan percuma, dan alat sumber terbuka seperti whisper.cpp, faster-whisper dan Buzz percuma sepenuhnya pada setiap platform desktop. Perkhidmatan awan percuma juga wujud, tetapi ia memuat naik audio anda — yang mengalahkan tujuannya jika privasi ialah sebab anda mencari perkataan "luar talian".
Bolehkah saya menjalankan Whisper sebagai API lokal dengan LocalAI?
Boleh. LocalAI ialah pelayan API sumber terbuka yang serasi dengan OpenAI dan boleh menyajikan model whisper.cpp, jadi anda boleh mengehos sendiri pengganti terus untuk titik akhir transkripsi awan pada perkakasan anda. Ia sesuai untuk pembangun yang membina saluran luar talian. Jika anda mahu model yang sama tanpa sebarang persediaan pelayan, Whisper Notes menjalankannya sebagai aplikasi natif pada Mac dan iPhone.