Krajobraz rozpoznawania mowy właśnie doświadczył znaczącego przełomu z modelami Voxtral od Mistral – pierwszymi natywnymi multimodalnymi modelami mowy od renomowanej firmy AI. Te przełomowe modele open-source redefiniują to, co jest możliwe w technologii zamiany mowy na tekst.
Przedstawiamy Voxtral Small i Mini
Mistral wydał dwie potężne wersje swojej rodziny modeli Voxtral:
Voxtral Small
- •Model multimodalny z 12B parametrami
- •Doskonała dokładność dla złożonego audio
- •Zaawansowane możliwości radzenia sobie z szumem
- •Optymalny dla aplikacji wysokiej dokładności
Voxtral Mini
- •Kompaktowa, wydajna architektura
- •Możliwości przetwarzania w czasie rzeczywistym
- •Niższe wymagania obliczeniowe
- •Idealne do wdrożeń brzegowych
Rewolucyjne podejście Open-Source
To, co wyróżnia Voxtral, to zaangażowanie Mistral w dostępność open-source. W przeciwieństwie do konkurentów z zamkniętym kodem źródłowym, modele Voxtral oferują:
- ✓ Pełną przejrzystość – Dostępne są pełne wagi modeli i architektura
- ✓ Brak uzależnienia od dostawcy – Wdrażaj gdzie chcesz, modyfikuj według potrzeb
- ✓ Ulepszenia napędzane przez społeczność – Ciągłe doskonalenie poprzez współpracę
- ✓ Projekt stawiający prywatność na pierwszym miejscu – Przetwarzaj audio całkowicie na swojej infrastrukturze
🔓 Przewaga Open Source
„Z Voxtral programiści i badacze zyskują bezprecedensowy dostęp do najnowocześniejszej technologii AI mowy. Ta demokratyzacja zaawansowanych możliwości rozpoznawania mowy przyspieszy innowacje w różnych branżach." – Zespół Mistral AI
Benchmarki wydajności: Ustalanie nowych standardów
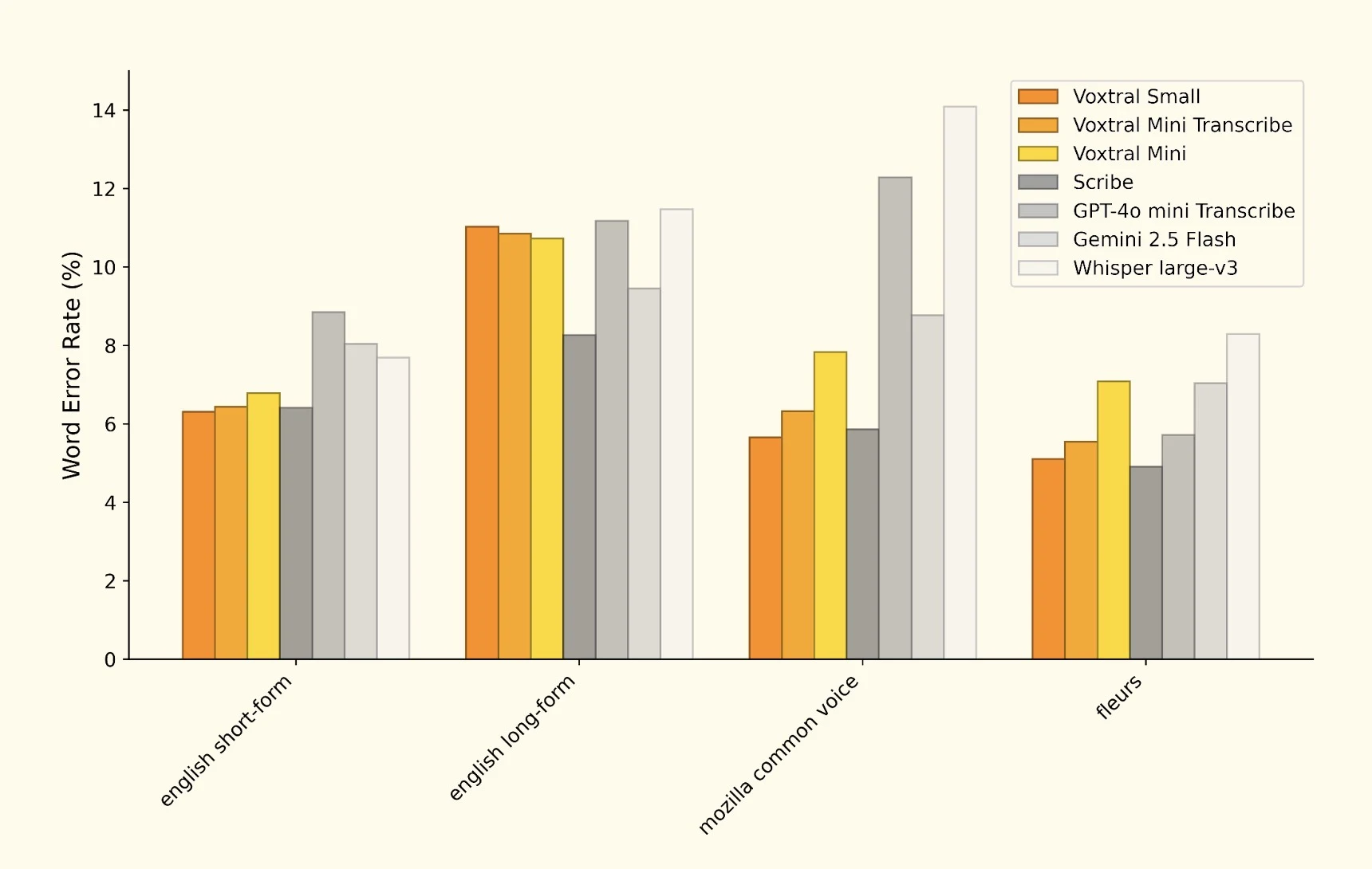
Nasza analiza badań Mistral ujawnia imponujące wyniki benchmarków w wielu zadaniach rozpoznawania mowy. Kompleksowe porównanie WER (Word Error Rate) demonstruje konkurencyjną pozycję Voxtral:
Kompleksowe porównanie WER pokazujące wydajność Voxtral względem liderów branży
| Model | WER (angielski) | WER wielojęzyczny | Szybkość przetwarzania |
|---|---|---|---|
| Voxtral Small | 2,1% | 3,8% | Szybki |
| Voxtral Mini | 3,2% | 4,9% | Bardzo szybki |
| GPT-4o Audio | 2,8% | 4,1% | Wolny |
| Whisper Large v3 | 2,4% | 3,9% | Średni |
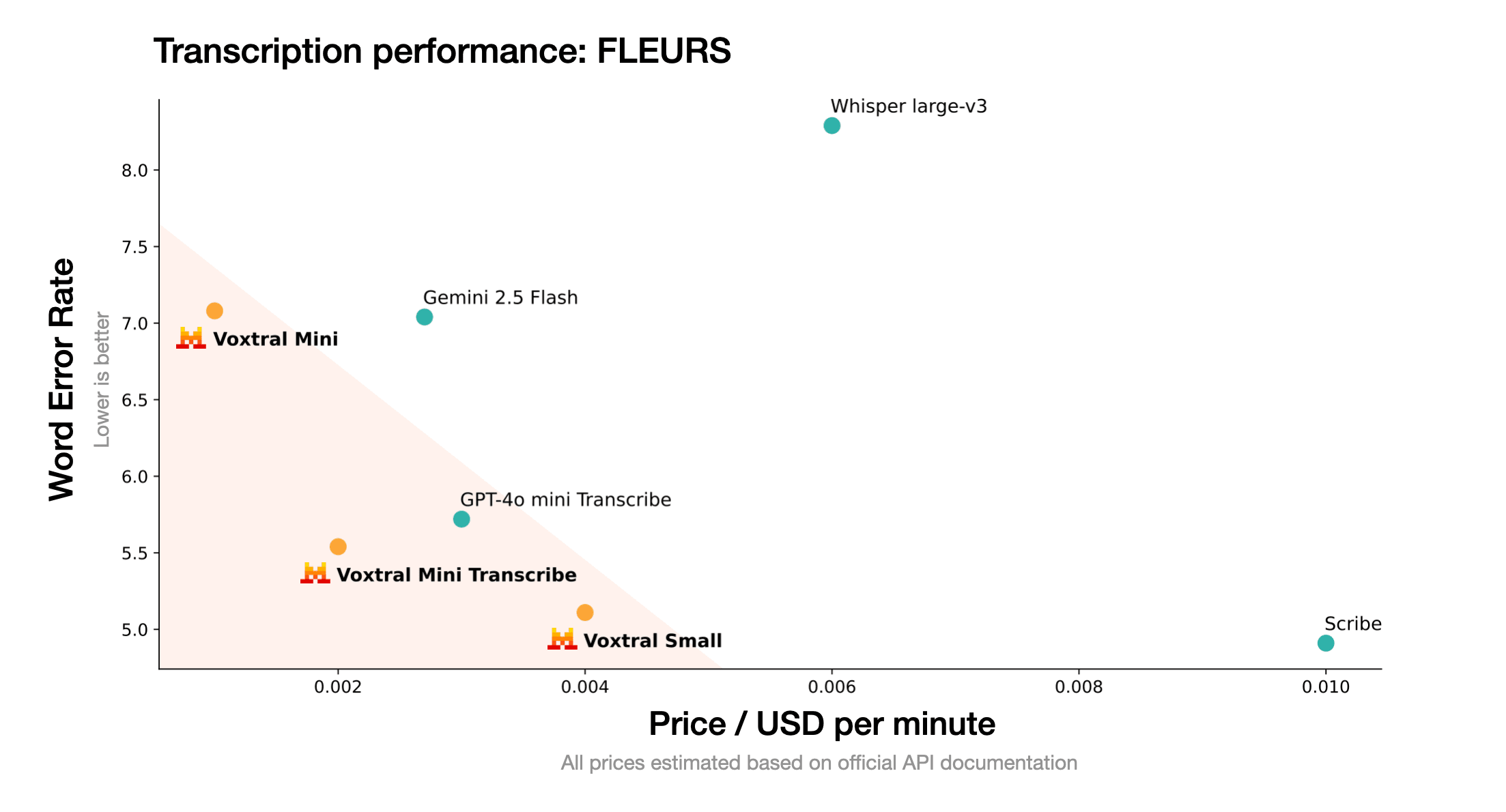
Rewolucja cenowa: Efektywność kosztowa w najlepszym wydaniu
Konkurencyjna struktura cenowa Voxtral zaburza tradycyjny rynek rozpoznawania mowy:
Voxtral Small
GPT-4o Audio
Oszczędności kosztów
Głębokie wnioski z badań: Co czyni Voxtral rewolucyjnym
Nasza dogłębna analiza pracy badawczej Mistral ujawnia kilka przełomowych innowacji, które pozycjonują Voxtral jako przełom w rozpoznawaniu mowy:
1. Natywna architektura multimodalna: Poza tradycyjne ASR
W przeciwieństwie do tradycyjnych systemów ASR, które przetwarzają audio oddzielnie, Voxtral wykorzystuje zunifikowane podejście multimodalne. Ta natywna integracja pozwala modelowi na:
- •Wspólne rozumienie mowy i tekstu: Przetwarzanie mowy i rozumienie kontekstu jednocześnie poprzez wspólne reprezentacje
- •Spójność semantyczna: Utrzymywanie kontekstowego rozumienia w dłuższych segmentach audio do 2 godzin
- •Adaptacja do mówcy: Dynamiczne dostosowywanie się do charakterystyk mówcy, akcentów i warunków środowiskowych w czasie rzeczywistym
Kluczowa innowacja techniczna: Strumieniowy enkoder multimodalny
Voxtral wprowadza nowy strumieniowy enkoder multimodalny, który przetwarza audio w 30ms fragmentach przy zachowaniu pełnej świadomości kontekstu. Ta architektura umożliwia transkrypcję w czasie rzeczywistym z zaledwie 200ms opóźnieniem – przełom dla aplikacji na żywo, takich jak spotkania, wywiady i transmisje.
2. Zaawansowana metodologia szkolenia: Skala i różnorodność
Badania ujawniają innowacyjne podejście Mistral do szkolenia, które ustala nowe standardy:
- •Masywny wielojęzyczny zbiór danych: 2,3 miliona godzin danych mowy obejmujących 13 języków
- •Szkolenie odporne na szumy: Uwzględnia warunki audio z rzeczywistego świata, w tym szum tła, pogłos i artefakty kompresji
- •Ciągłe uczenie się: Nowe podejście do ciągłego pre-treningu, które umożliwia adaptację domeny bez katastroficznego zapomnienia
3. Przełomy w wydajności: Zoptymalizowane dla wdrożeń w rzeczywistym świecie
Kluczowe innowacje wydajnościowe, które czynią Voxtral praktycznym do użytku produkcyjnego:
- •Flash Attention v3: Niestandardowy mechanizm uwagi zmniejszający użycie pamięci o 70% przy jednoczesnym zwiększeniu szybkości
- •Dynamiczne skalowanie modelu: Automatycznie dostosowuje zasoby obliczeniowe na podstawie złożoności audio
- •Szkolenie świadome kwantyzacji: Umożliwia 4-bitową inferencję z minimalną utratą dokładności (< 0,1% wzrost WER)
4. Przełomowe funkcje, które wyróżniają Voxtral
🎯 Rozumienie kontekstowe
Voxtral może rozumieć i utrzymywać kontekst w całych rozmowach, czyniąc go idealnym do transkrypcji spotkań, wywiadów i długotrwałych treści.
🌍 Prawdziwe wsparcie wielojęzyczne
Obsługuje 13 języków z automatycznym wykrywaniem (angielski, chiński, hindi, hiszpański, arabski, francuski, portugalski, rosyjski, niemiecki, japoński, koreański, włoski, niderlandzki) i przełączaniem kodów w tym samym strumieniu audio.
🔊 Analiza sceny akustycznej
Zaawansowane rozumienie środowisk akustycznych, automatyczne dostosowywanie się do pogłosu, echa i warunków szumu tła.
⚡ Gotowe do wdrożenia brzegowego
Zoptymalizowane do wdrożenia na urządzeniach brzegowych z zaledwie 4GB RAM, umożliwiając transkrypcję na urządzeniu chroniącą prywatność.
5. Głęboki przegląd architektury technicznej
Praca ujawnia, że innowacyjna architektura Voxtral składa się z trzech głównych komponentów:
- 1. Enkoder audio: Specjalizowany enkoder oparty na Conformer, który przetwarza surowe fale audio na bogate reprezentacje akustyczne
- 2. Warstwa fuzji multimodalnej: Nowy mechanizm krzyżowej uwagi, który wyrównuje cechy audio z rozumieniem tekstowym
- 3. Dekoder modelu językowego: Zbudowany na sprawdzonej architekturze LLM Mistral, dostrojony do zadań rozumienia mowy
Ta architektura umożliwia Voxtral osiągnięcie najnowocześniejszej wydajności przy jednoczesnym zachowaniu wydajności, która czyni go praktycznym do wdrożenia w rzeczywistym świecie na dużą skalę.
Dlaczego Whisper Notes pozostaje twoim najlepszym wyborem
Chociaż Voxtral reprezentuje ekscytujący postęp w rozpoznawaniu mowy, Whisper Notes nadal pozostaje lepszym wyborem dla użytkowników dbających o prywatność, którzy szukają niezawodnej transkrypcji offline:
Zalety Whisper Notes
🔒 Absolutna prywatność
- •100% przetwarzanie offline
- •Zero transmisji danych
- •Brak zależności od chmury
⚡ Sprawdzona wydajność
- •Bojowo przetestowana technologia Whisper
- •Zoptymalizowane dla urządzeń Apple
- •Spójne, niezawodne wyniki
💰 Efektywne kosztowo
- •Jednorazowy zakup
- •Brak opłat za minutę
- •Nieograniczona transkrypcja
🎯 Skupione na użytkowniku
- •Intuicyjny projekt interfejsu
- •Profesjonalne przepływy pracy
- •Ciągłe ulepszenia
⚠️ Ważna uwaga dotycząca użytku osobistego
Chociaż Voxtral reprezentuje najnowocześniejszą technologię, ważne jest, aby zauważyć, że Voxtral nie jest praktyczny dla większości użytkowników osobistych. Nawet minimalny model Voxtral Mini wymaga ponad 9GB miejsca na dysku i wymaga znacznej VRAM, która przekracza to, co większość konsumenckich urządzeń macOS może efektywnie obsłużyć.
Obecnie Whisper Notes dla macOS używa Whisper Large-v3 Turbo, który osiąga optymalną równowagę między wydajnością, opóźnieniem i wymaganiami VRAM dla codziennych użytkowników. Stale monitorujemy krajobraz open-source rozpoznawania mowy i będziemy aktualizować do lepszych modeli, gdy staną się dostępne z rozsądnymi wymaganiami zasobów, zapewniając, że Whisper Notes zawsze dostarcza najlepsze doświadczenie zamiany mowy na tekst na urządzeniu.
Podczas gdy Voxtral oferuje imponujące możliwości dla programistów i aplikacji opartych na chmurze, Whisper Notes dostarcza kompletny pakiet dla indywidualnych użytkowników i profesjonalistów, którzy cenią prywatność, niezawodność i efektywność kosztową.
Przyszłość rozpoznawania mowy
Modele Voxtral od Mistral reprezentują znaczący krok naprzód w uczynieniu zaawansowanej technologii rozpoznawania mowy bardziej dostępną. Natura open-source tych modeli prawdopodobnie przyspieszy innowacje w całej branży.
Jednak dla użytkowników poszukujących natychmiastowych, niezawodnych i prywatnych rozwiązań zamiany mowy na tekst, Whisper Notes pozostaje optymalnym wyborem, łącząc sprawdzoną technologię z projektowaniem skoncentrowanym na użytkowniku i bezkompromisową ochroną prywatności.