RESUMEN — Tres modelos Mac comparados
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min inglés | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 min chino | 10,10s (161×) | 13,83s (118×) | 2 min 4s (13,1×) |
| Idiomas | 25 (europeos) | 5 (zh, en, ja, ko, yue) | 99+ |
| Descarga | 465 MB | 827 MB | 1,5 GB |
| Memoria | ~800 MB | ~700 MB | ~1,6 GB |
| Ideal para | Inglés & europeo | Chino, japonés, coreano, cantonés | Todo lo demás (99+ idiomas) |
* Benchmarks de velocidad en Apple M4 Pro, 32 GB. Podcast en inglés de 5 minutos y podcast en chino de 27 minutos. Factor de tiempo real = duración del audio ÷ tiempo de procesamiento (mayor = más rápido). SenseVoice es solo para macOS. iOS usa Parakeet (vía ANE) y Whisper.
A partir de la versión 1.4.8, Whisper Notes para Mac incluye SenseVoice Small como motor dedicado para la transcripción de chino, japonés, coreano y cantonés. Reemplaza a Qwen3-ASR y se ejecuta en la GPU de Apple mediante MLX en lugar de la CPU — procesando un podcast en chino de 27 minutos en 13,83 segundos en vez de 3 minutos y 44 segundos.
Por qué reemplazamos Qwen3-ASR
Qwen3-ASR era un modelo sólido. Soportaba 30 idiomas más 22 dialectos chinos, y su precisión en chino estaba cerca del estado del arte. Pero tenía un problema que empeoraba con la duración del audio: la velocidad.
Qwen3 usaba una arquitectura autorregresiva — el mismo enfoque que Whisper, procesando el audio fotograma a fotograma, sin saltar nunca hacia adelante. En un podcast en chino de 27 minutos, tardaba 73 segundos. Utilizable, pero no la experiencia de resultado instantáneo que Parakeet V3 ofrece para inglés.
El problema más profundo era nuestra infraestructura. Nuestra integración de Qwen3 usaba sherpa-onnx, una biblioteca C con un wrapper Swift de 2.249 líneas que enrutaba todo a través de los núcleos de la CPU. La GPU permanecía inactiva mientras la CPU de tu Mac hacía todo el trabajo.
SenseVoice solucionó ambos problemas. Arquitectura no autorregresiva para la velocidad. Apple MLX para aceleración GPU. El resultado: una mejora de velocidad de 16,2× en el mismo hardware, con un código reducido de 2.249 a 288 líneas.
El benchmark
Los tres modelos ejecutándose en el mismo Apple M4 Pro, mismos archivos de audio, mismas condiciones. Sin nube. Sin internet. Solo silicio.
| Modelo | 5 min inglés | 27 min chino | Velocidad (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103–161× |
| SenseVoice Small | 5,8s | 13,83s | 52–118× |
| Whisper Large V3 Turbo | 20,92s | 2 min 4s | 13–14× |
| Qwen3-ASR (eliminado) | — | 73s | 4,7× |
SenseVoice es aproximadamente la mitad de rápido que Parakeet V3 — pero sigue siendo extraordinariamente rápido. Un podcast de 27 minutos se completa en menos de 14 segundos. Pulsas transcribir, esperas un instante, y el texto está ahí.
Compáralo con Whisper a 2 minutos y 4 segundos, o el antiguo Qwen3 a 73 segundos. La arquitectura importa más que la cantidad de parámetros.
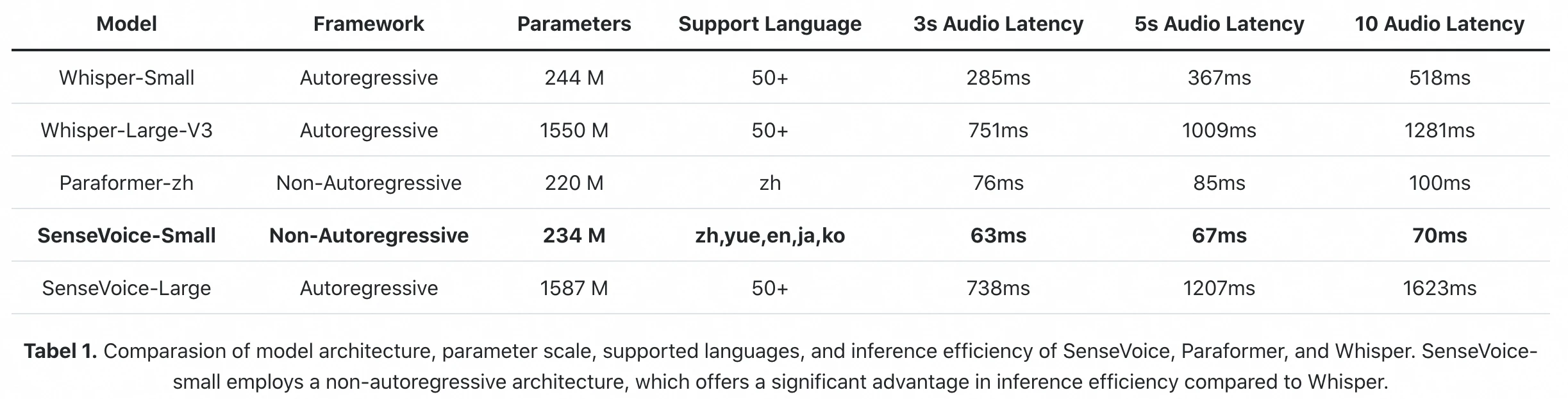
Benchmark oficial de inferencia del paper FunAudioLLM: SenseVoice-Small procesa 10s de audio en 70ms (GPU A800). Whisper-Large-V3 tarda 1.281ms. Eso es una diferencia de 18× en latencia de inferencia pura.
| Modelo | Tiempo de carga | Memoria | Tamaño de descarga |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81s | ~700 MB | 827 MB |
| Whisper Small | 1,03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18s | ~1,6 GB | 3 GB |
* Tiempo de carga y memoria medidos en Apple M4 Pro, 32 GB.
SenseVoice se carga en menos de un segundo y usa menos memoria que Parakeet. En un Mac de 8 GB, funciona cómodamente junto a tus otras aplicaciones.
Por qué SenseVoice es más rápido: arquitectura + entorno de ejecución
La diferencia de velocidad entre Qwen3-ASR y SenseVoice proviene de dos factores independientes.
Factor 1: Arquitectura del modelo. Qwen3-ASR es autorregresivo — genera texto token a token, cada uno dependiendo del anterior. SenseVoice usa un codificador no autorregresivo (NAR) que procesa todo el audio en paralelo. Esta diferencia arquitectónica por sí sola hace que SenseVoice sea fundamentalmente más rápido, independientemente del hardware que uses.
Factor 2: Entorno de ejecución. Nuestra integración de Qwen3-ASR usaba sherpa-onnx, que se ejecutaba en CPU. SenseVoice funciona a través de Apple MLX, enviando los cálculos a la GPU. ¿Podría Qwen3 también ejecutarse en MLX? Sí — pero seguiría siendo más lento que SenseVoice porque el cuello de botella autorregresivo está en la arquitectura, no en el entorno de ejecución.
| Qwen3-ASR (anterior) | SenseVoice (nuevo) | |
|---|---|---|
| Arquitectura | Autorregresiva (token a token) | No autorregresiva (paralela) |
| Entorno de ejecución | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min chino | 224 segundos | 13,83 segundos |
| Aceleración combinada | línea base | 16,2× más rápido |
| Código fuente | Framework C de 168 MB + 2.249 líneas Swift | 288 líneas Swift Actor |
* Mismo podcast chino de 27 minutos, Apple M4 Pro. La aceleración de 16,2× combina mejoras tanto arquitectónicas (NAR vs AR) como de entorno de ejecución (GPU vs CPU).
El código también se simplificó. La nueva implementación de SenseVoice es un único Swift Actor de 288 líneas que se comunica directamente con MLX, reemplazando un framework C de 168 MB. Menos código, menos errores, aplicación más pequeña.
Cinco idiomas, bien hechos
SenseVoice no intenta hacerlo todo. Maneja cinco idiomas:
| Idioma | SenseVoice-Small | Whisper-Large-V3 | Ganador |
|---|---|---|---|
| Chino (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Cantonés (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japonés (ja) | 11,96% CER | 10,34% CER | Whisper (ligeramente) |
| Coreano (ko) | 8,28% CER | 5,59% CER | Whisper |
| Inglés (en) | 14,71% WER | 9,39% WER | Whisper (usa Parakeet) |
* Benchmark CommonVoice, CER = tasa de error por carácter, WER = tasa de error por palabra. Menor es mejor. Fuente: paper FunAudioLLM (2024). Latencia de inferencia de SenseVoice-Small: 70ms por 10s de audio (GPU A800), más de 15× más rápido que Whisper-Large-V3.
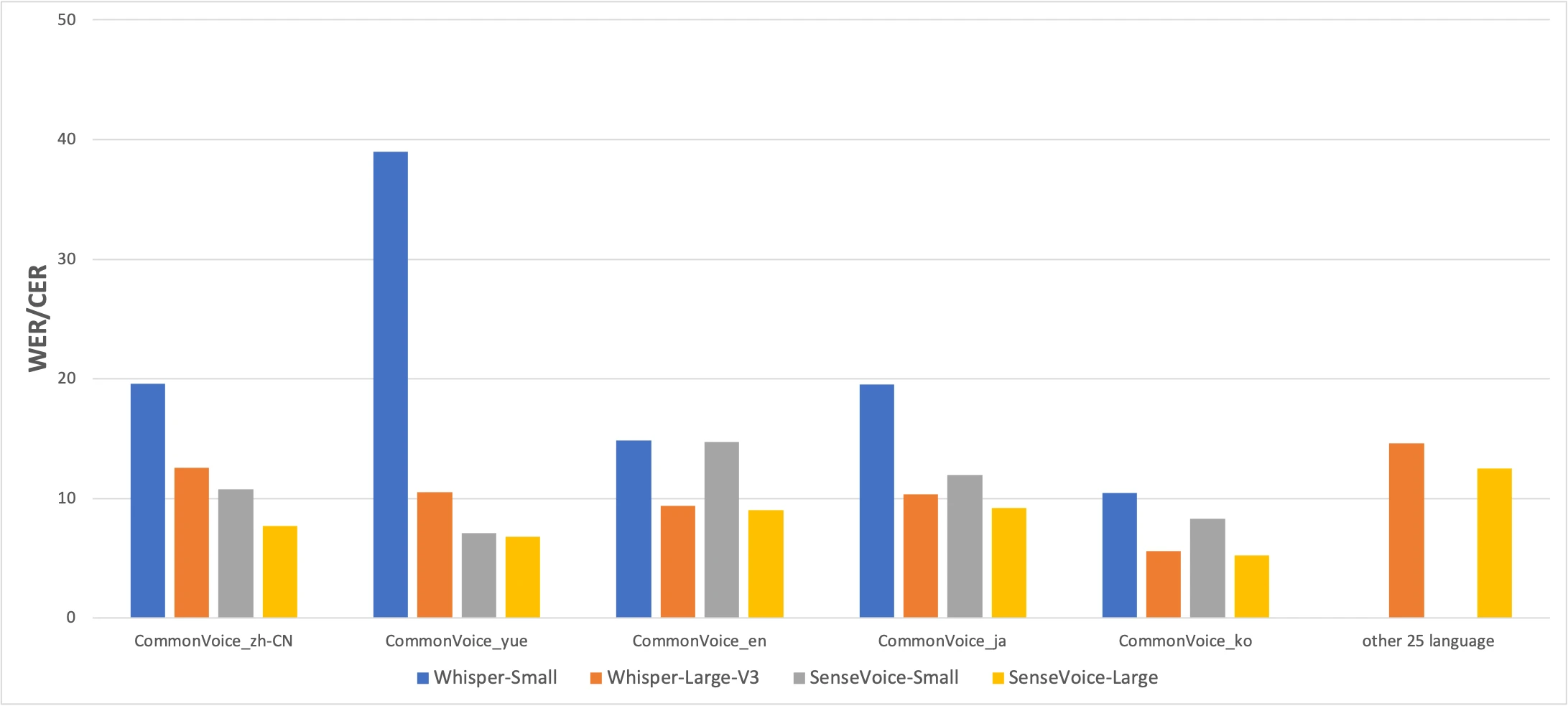
Benchmark CommonVoice: SenseVoice-Small (amarillo) vs Whisper-Small (azul) vs Whisper-Large-V3 (naranja). Menor es mejor. Fuente: paper FunAudioLLM
Los números cuentan una historia honesta. SenseVoice supera a Whisper en precisión para chino y cantonés por un margen significativo, mientras que Whisper es más preciso para japonés, coreano e inglés. Pero SenseVoice es más de 15× más rápido que Whisper-Large-V3. Para la mayoría de los usos reales, la diferencia de velocidad importa más que unos pocos puntos porcentuales de precisión.
El resultado del cantonés merece destacarse por separado. Whisper-Small obtiene 38,97% de CER en cantonés — prácticamente inutilizable. Incluso Whisper-Large-V3 solo logra 10,41%. SenseVoice alcanza 7,09%. Antes de SenseVoice, no existía una buena forma de transcribir cantonés localmente en un Mac. Si hablas cantonés, este modelo existe para ti.
Transcripción coreana con SenseVoice: importación de vídeo con subtítulos con marca de tiempo
Prueba en el mundo real: podcast chino de 27 minutos
Transcribimos un episodio de 27 minutos de Thirteen Invitations (十三邀), un podcast de entrevistas en chino, con SenseVoice y Whisper Large V3 Turbo en el mismo M4 Pro. ElevenLabs Scribe (nube) sirvió como referencia. Ambos modelos en el dispositivo cometen aproximadamente el mismo número de errores, pero de tipos diferentes:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Tiempo | 13,83s | 2 min 4s |
| Errores (muestra de 5 min) | ~15–20 | ~12–15 |
| Peor error | 时差→食堂 (huso horario→cafetería) | 西昌→西藏 (ciudad de Xichang→Tíbet, 4.000 km de diferencia) |
| Patrón de errores | Intercambios de homófonos | Errores geográficos/factuales |
* Comparación manual con ElevenLabs Scribe (referencia en la nube, también imperfecta). Ambos modelos en el dispositivo escribieron correctamente «根深蒂固» donde Scribe se equivocó.
Precisión comparable. 9× más rápido. Para transcripción de chino en el mundo real, SenseVoice te entrega un transcript utilizable antes de que Whisper termine de cargar.
Cuándo usar cada modelo
Whisper Notes para Mac ahora incluye cuatro modelos de voz. Cada uno está optimizado para diferentes escenarios:
| Necesitas... | Usa este modelo | Por qué |
|---|---|---|
| Inglés o idiomas europeos, máxima velocidad | Parakeet V3 | 103× tiempo real, menor tasa de error. El predeterminado. |
| Chino, japonés, coreano o cantonés | SenseVoice Small | 52–118× tiempo real. Único modelo con soporte para cantonés. |
| Cualquiera de 99+ idiomas (árabe, tailandés, ruso, etc.) | Whisper Large V3 Turbo | Mayor soporte de idiomas. Más lento pero universal. |
| Menor uso de memoria (Mac antiguos) | Whisper Small | 487 MB de memoria. Bueno para Mac de 8 GB con otras apps abiertas. |
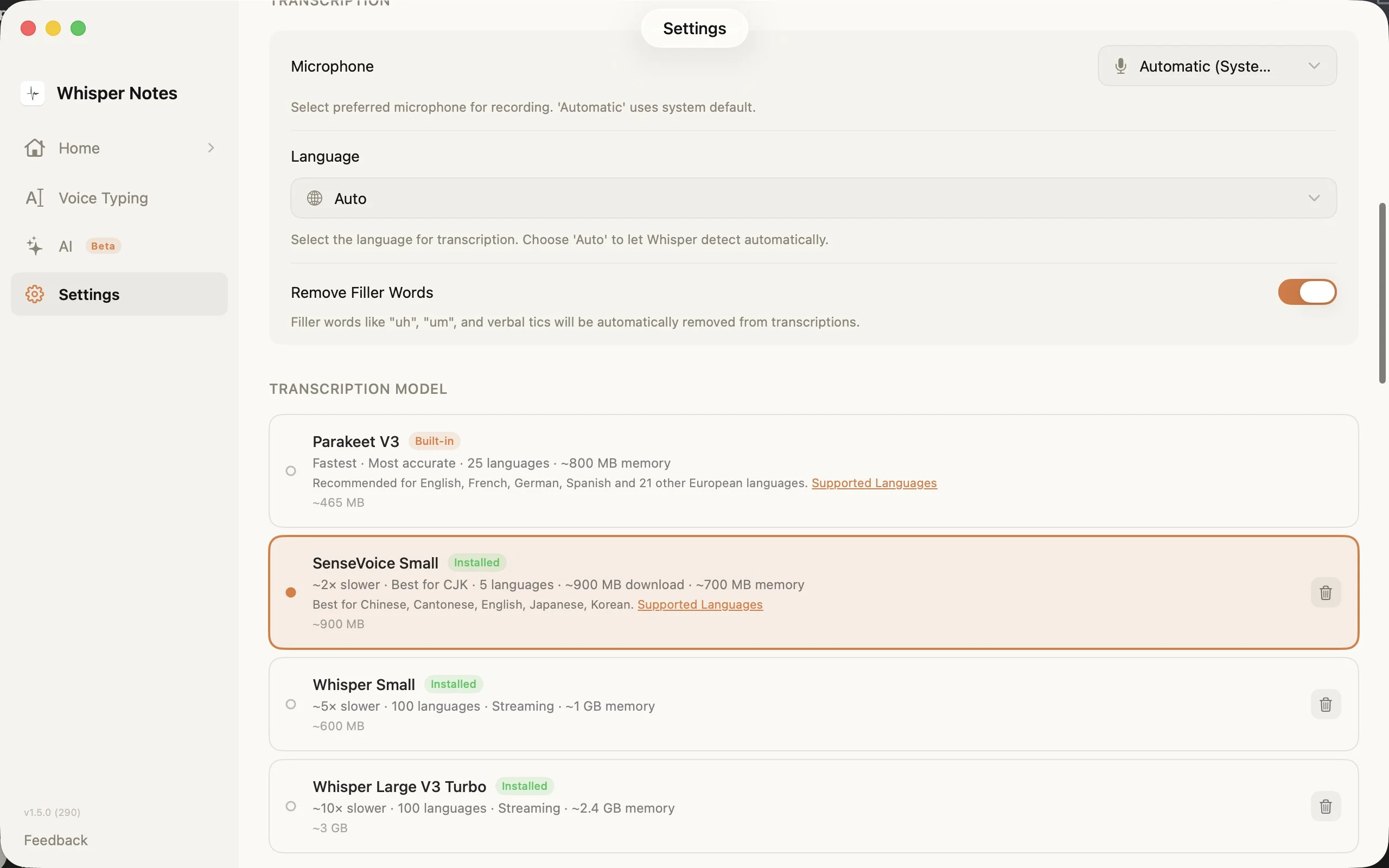
Ajustes → Modelo de transcripción: elige el motor adecuado para tu idioma
El selector de modelos en Ajustes muestra las cuatro opciones con tamaños de descarga, cantidad de idiomas y requisitos de memoria. SenseVoice se descarga en el primer uso (~827 MB) y permanece en tu dispositivo.
Las limitaciones
SenseVoice no es un modelo universal. Esto es lo que no puede hacer:
• Solo 5 idiomas. Si necesitas tailandés, ruso, árabe, hindi o cualquiera de los más de 90 idiomas que soporta Whisper, quédate con Whisper.
• Solo Mac. SenseVoice funciona mediante Apple MLX, que requiere macOS. No está disponible en iPhone. Los usuarios de iOS tienen Parakeet (para idiomas europeos) y Whisper.
• Particularidad con audio silencioso. Durante segmentos muy cortos o muy silenciosos, SenseVoice puede a veces producir texto en chino independientemente del idioma seleccionado. Configurar el idioma manualmente (en lugar de «Auto») reduce este comportamiento.
• Sin streaming. A diferencia del modo streaming de Whisper, SenseVoice procesa el audio completo después de la grabación. Para archivos largos, segmenta automáticamente en los puntos de silencio y muestra los resultados progresivamente.
Estas son limitaciones arquitectónicas, no errores. Un modelo entrenado en 5 idiomas domina esos 5 idiomas extremadamente bien. El soporte de 99+ idiomas de Whisper conlleva menor velocidad y mayores tasas de error en cada idioma individual.
Pruébalo
SenseVoice está disponible en Whisper Notes para Mac v1.4.8 y posteriores. Descárgalo desde Ajustes → Modelo de transcripción → SenseVoice Small (~827 MB). Requiere un Mac con Apple Silicon (M1 o posterior).
Si usas Parakeet V3 y dictas principalmente en inglés, no necesitas cambiar. SenseVoice es para cuando necesitas chino, japonés, coreano o cantonés — y lo quieres rápido.
Registro de cambios completo: whispernotes.app/changelog
Preguntas o comentarios: mac@whispernotes.app