EN BREF — Trois modèles Mac comparés
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min anglais | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 min chinois | 10,10s (161×) | 13,83s (118×) | 2 min 4s (13,1×) |
| Langues | 25 (européennes) | 5 (zh, en, ja, ko, yue) | 99+ |
| Téléchargement | 465 Mo | 827 Mo | 1,5 Go |
| Mémoire | ~800 Mo | ~700 Mo | ~1,6 Go |
| Idéal pour | Anglais & européen | Chinois, japonais, coréen, cantonais | Tout le reste (99+ langues) |
* Benchmarks de vitesse sur Apple M4 Pro, 32 Go. Podcast anglais de 5 minutes et podcast chinois de 27 minutes. Facteur temps réel = durée audio ÷ temps de traitement (plus élevé = plus rapide). SenseVoice est disponible uniquement sur macOS. iOS utilise Parakeet (via ANE) et Whisper.
À partir de la version 1.4.8, Whisper Notes pour Mac intègre SenseVoice Small comme moteur dédié à la transcription du chinois, du japonais, du coréen et du cantonais. Il remplace Qwen3-ASR et fonctionne sur le GPU d'Apple via MLX au lieu du CPU — traitant un podcast chinois de 27 minutes en 13,83 secondes au lieu de 3 minutes et 44 secondes.
Pourquoi nous avons remplacé Qwen3-ASR
Qwen3-ASR était un modèle solide. Il prenait en charge 30 langues plus 22 dialectes chinois, et sa précision pour le chinois était proche de l'état de l'art. Mais il avait un problème qui s'aggravait avec la durée de l'audio : la vitesse.
Qwen3 utilisait une architecture autorégressive — la même approche que Whisper, traitant l'audio image par image, sans jamais sauter en avant. Sur un podcast chinois de 27 minutes, cela prenait 73 secondes. Utilisable, mais loin de l'expérience de résultat instantané que Parakeet V3 offre pour l'anglais.
Le problème plus profond était notre infrastructure. Notre intégration Qwen3 utilisait sherpa-onnx, une bibliothèque C avec un wrapper Swift de 2 249 lignes qui acheminait tout via les cœurs CPU. Le GPU restait inactif pendant que le CPU de votre Mac faisait tout le travail.
SenseVoice a résolu les deux problèmes. Architecture non-autorégressive pour la vitesse. Apple MLX pour l'accélération GPU. Le résultat : une amélioration de vitesse de 16,2× sur le même matériel, avec une base de code réduite de 2 249 à 288 lignes.
Le benchmark
Les trois modèles fonctionnent sur le même Apple M4 Pro, mêmes fichiers audio, mêmes conditions. Pas de cloud. Pas d'internet. Juste du silicium.
| Modèle | 5 min anglais | 27 min chinois | Vitesse (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103–161× |
| SenseVoice Small | 5,8s | 13,83s | 52–118× |
| Whisper Large V3 Turbo | 20,92s | 2 min 4s | 13–14× |
| Qwen3-ASR (supprimé) | — | 73s | 4,7× |
SenseVoice est environ deux fois moins rapide que Parakeet V3 — mais reste extraordinairement rapide. Un podcast de 27 minutes est terminé en moins de 14 secondes. Vous appuyez sur transcrire, vous attendez un souffle, et le texte est là.
Comparez cela à Whisper avec 2 minutes et 4 secondes, ou à l'ancien Qwen3 avec 73 secondes. L'architecture compte plus que le nombre de paramètres.
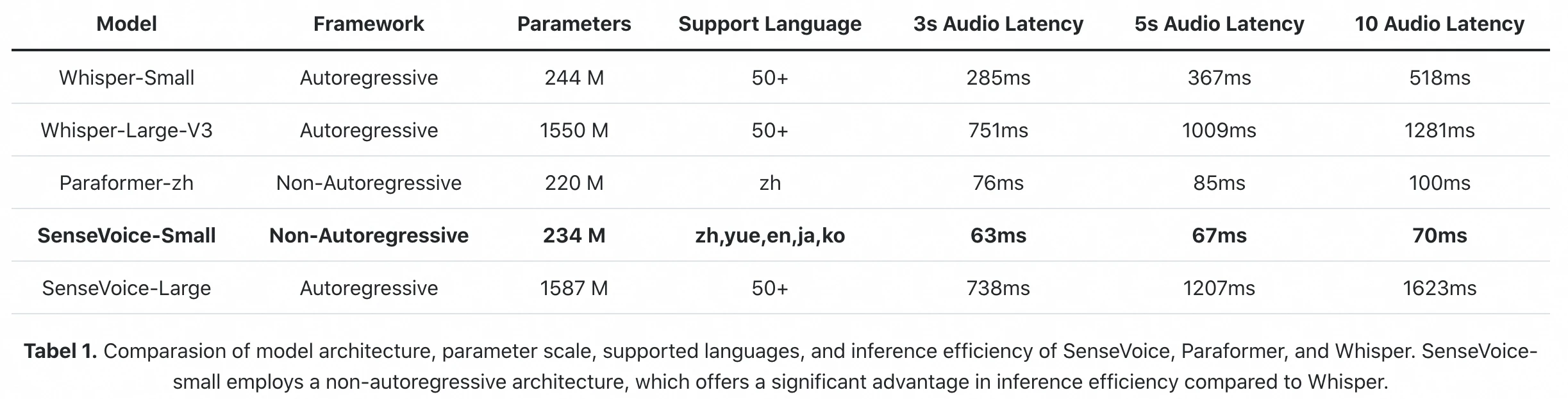
Benchmark officiel d'inférence du paper FunAudioLLM : SenseVoice-Small traite 10s d'audio en 70ms (GPU A800). Whisper-Large-V3 prend 1 281ms. C'est une différence de 18× en latence d'inférence brute.
| Modèle | Temps de chargement | Mémoire | Taille du téléchargement |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 Mo | 465 Mo |
| SenseVoice Small | 0,81s | ~700 Mo | 827 Mo |
| Whisper Small | 1,03s | ~487 Mo | 600 Mo |
| Whisper Large V3 Turbo | 3,18s | ~1,6 Go | 3 Go |
* Temps de chargement et mémoire mesurés sur Apple M4 Pro, 32 Go.
SenseVoice se charge en moins d'une seconde et utilise moins de mémoire que Parakeet. Sur un Mac 8 Go, il fonctionne confortablement aux côtés de vos autres applications.
Pourquoi SenseVoice est plus rapide : architecture + environnement d'exécution
L'écart de vitesse entre Qwen3-ASR et SenseVoice provient de deux facteurs indépendants.
Facteur 1 : Architecture du modèle. Qwen3-ASR est autorégressif — il génère du texte token par token, chacun dépendant du précédent. SenseVoice utilise un encodeur non-autorégressif (NAR) qui traite l'audio entier en parallèle. Cette différence architecturale seule rend SenseVoice fondamentalement plus rapide, quel que soit le matériel utilisé.
Facteur 2 : Environnement d'exécution. Notre intégration Qwen3-ASR utilisait sherpa-onnx, qui fonctionnait sur CPU. SenseVoice fonctionne via Apple MLX, acheminant les calculs vers le GPU. Qwen3 pourrait-il aussi fonctionner sur MLX ? Oui — mais il serait toujours plus lent que SenseVoice car le goulot d'étranglement autorégressif se situe dans l'architecture, pas dans l'environnement d'exécution.
| Qwen3-ASR (ancien) | SenseVoice (nouveau) | |
|---|---|---|
| Architecture | Autorégressive (token par token) | Non-autorégressive (parallèle) |
| Environnement d'exécution | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min chinois | 224 secondes | 13,83 secondes |
| Accélération combinée | référence | 16,2× plus rapide |
| Base de code | Framework C de 168 Mo + 2 249 lignes Swift | 288 lignes Swift Actor |
* Même podcast chinois de 27 minutes, Apple M4 Pro. L'accélération de 16,2× combine les améliorations architecturales (NAR vs AR) et d'exécution (GPU vs CPU).
Le code est aussi devenu plus simple. La nouvelle implémentation SenseVoice est un seul Swift Actor de 288 lignes qui communique directement avec MLX, remplaçant un framework C de 168 Mo. Moins de code, moins de bugs, application plus légère.
Cinq langues, bien maîtrisées
SenseVoice ne cherche pas à tout faire. Il prend en charge cinq langues :
| Langue | SenseVoice-Small | Whisper-Large-V3 | Gagnant |
|---|---|---|---|
| Chinois (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Cantonais (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japonais (ja) | 11,96% CER | 10,34% CER | Whisper (légèrement) |
| Coréen (ko) | 8,28% CER | 5,59% CER | Whisper |
| Anglais (en) | 14,71% WER | 9,39% WER | Whisper (utilisez Parakeet) |
* Benchmark CommonVoice, CER = taux d'erreur par caractère, WER = taux d'erreur par mot. Plus bas est mieux. Source : paper FunAudioLLM (2024). Latence d'inférence SenseVoice-Small : 70ms pour 10s d'audio (GPU A800), plus de 15× plus rapide que Whisper-Large-V3.
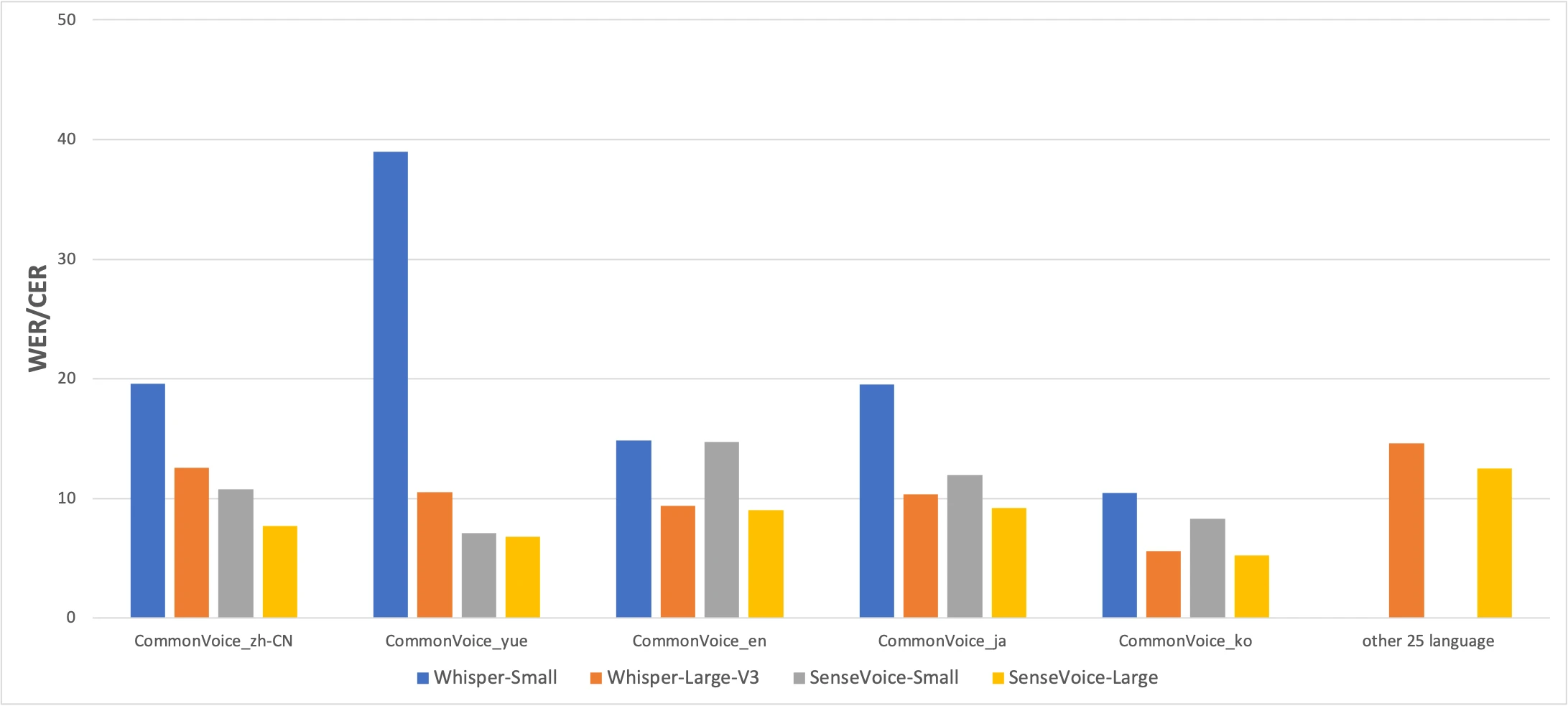
Benchmark CommonVoice : SenseVoice-Small (jaune) vs Whisper-Small (bleu) vs Whisper-Large-V3 (orange). Plus bas est mieux. Source : paper FunAudioLLM
Les chiffres racontent une histoire honnête. SenseVoice bat Whisper en précision sur le chinois et le cantonais avec une marge significative, tandis que Whisper est plus précis pour le japonais, le coréen et l'anglais. Mais SenseVoice est plus de 15× plus rapide que Whisper-Large-V3. Pour la plupart des usages réels, la différence de vitesse compte plus que quelques points de pourcentage de précision.
Le résultat pour le cantonais mérite d'être souligné séparément. Whisper-Small obtient 38,97% de CER sur le cantonais — quasiment inutilisable. Même Whisper-Large-V3 n'atteint que 10,41%. SenseVoice atteint 7,09%. Avant SenseVoice, il n'existait pas de bonne solution pour transcrire le cantonais localement sur un Mac. Si vous parlez cantonais, ce modèle a été créé pour vous.
Transcription coréenne avec SenseVoice : import vidéo avec sous-titres horodatés
Test en conditions réelles : podcast chinois de 27 minutes
Nous avons transcrit un épisode de 27 minutes de Thirteen Invitations (十三邀), un podcast d'interviews chinois, avec SenseVoice et Whisper Large V3 Turbo sur le même M4 Pro. ElevenLabs Scribe (cloud) a servi de référence. Les deux modèles embarqués font à peu près le même nombre d'erreurs, mais de types différents :
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Temps | 13,83s | 2 min 4s |
| Erreurs (échantillon de 5 min) | ~15–20 | ~12–15 |
| Pire erreur | 时差→食堂 (décalage horaire→cantine) | 西昌→西藏 (ville de Xichang→Tibet, 4 000 km d'écart) |
| Type d'erreur | Confusions d'homophones | Erreurs géographiques/factuelles |
* Comparaison manuelle avec ElevenLabs Scribe (référence cloud, également imparfaite). Les deux modèles embarqués ont correctement écrit « 根深蒂固 » là où Scribe s'est trompé.
Précision comparable. 9× plus rapide. Pour la transcription chinoise en conditions réelles, SenseVoice vous fournit un transcript utilisable avant même que Whisper ait fini de charger.
Quel modèle utiliser et quand
Whisper Notes pour Mac est désormais livré avec quatre modèles vocaux. Chacun est optimisé pour des scénarios différents :
| Vous avez besoin de... | Utilisez ce modèle | Pourquoi |
|---|---|---|
| Anglais ou langues européennes, vitesse maximale | Parakeet V3 | 103× temps réel, taux d'erreur le plus bas. Le choix par défaut. |
| Chinois, japonais, coréen ou cantonais | SenseVoice Small | 52–118× temps réel. Seul modèle avec support du cantonais. |
| L'une des 99+ langues (arabe, thaï, russe, etc.) | Whisper Large V3 Turbo | Support linguistique le plus large. Plus lent mais universel. |
| Consommation mémoire réduite (anciens Mac) | Whisper Small | 487 Mo de mémoire. Idéal pour les Mac 8 Go avec d'autres apps ouvertes. |
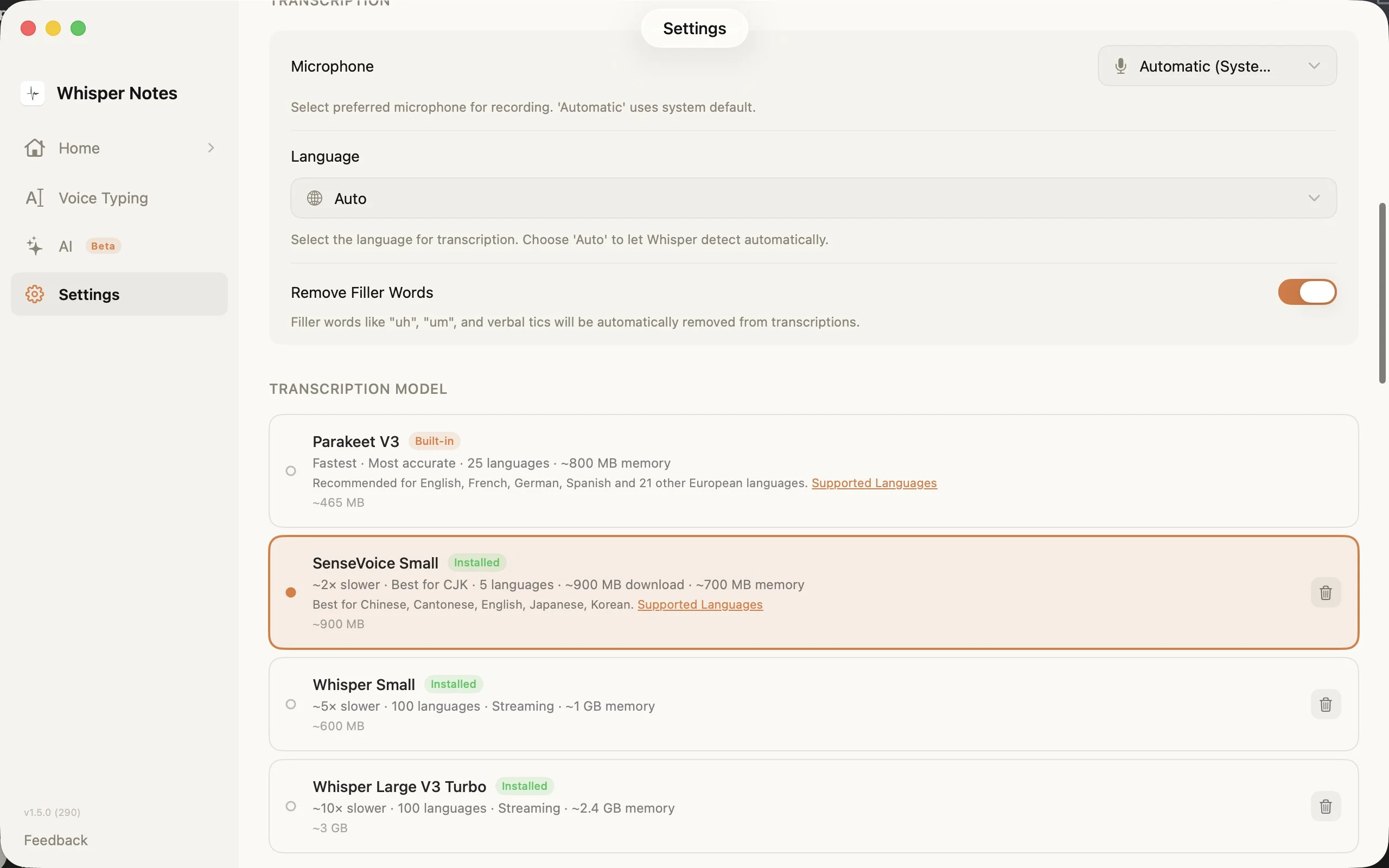
Réglages → Modèle de transcription : choisissez le bon moteur pour votre langue
Le sélecteur de modèles dans les Réglages affiche les quatre options avec les tailles de téléchargement, le nombre de langues et les exigences en mémoire. SenseVoice se télécharge à la première utilisation (~827 Mo) et reste sur votre appareil.
Les compromis
SenseVoice n'est pas un modèle universel. Voici ce qu'il ne peut pas faire :
• Seulement 5 langues. Si vous avez besoin du thaï, du russe, de l'arabe, de l'hindi ou de l'une des 90+ autres langues supportées par Whisper, restez sur Whisper.
• Mac uniquement. SenseVoice fonctionne via Apple MLX, qui nécessite macOS. Il n'est pas disponible sur iPhone. Les utilisateurs iOS disposent de Parakeet (pour les langues européennes) et de Whisper.
• Particularité avec l'audio silencieux. Lors de segments très courts ou très silencieux, SenseVoice peut parfois basculer en sortie chinoise quelle que soit la langue sélectionnée. Régler la langue manuellement (au lieu de « Auto ») réduit ce phénomène.
• Pas de streaming. Contrairement au mode streaming de Whisper, SenseVoice traite l'audio complet après l'enregistrement. Pour les fichiers longs, il segmente automatiquement aux points de silence et affiche les résultats progressivement.
Ce sont des contraintes architecturales, pas des bugs. Un modèle entraîné sur 5 langues maîtrise ces 5 langues extrêmement bien. Le support de 99+ langues de Whisper s'accompagne d'une vitesse réduite et de taux d'erreur plus élevés pour chaque langue individuelle.
Essayez-le
SenseVoice est disponible dans Whisper Notes pour Mac v1.4.8 et versions ultérieures. Téléchargez-le depuis Réglages → Modèle de transcription → SenseVoice Small (~827 Mo). Il nécessite un Mac Apple Silicon (M1 ou ultérieur).
Si vous utilisez Parakeet V3 et dictez principalement en anglais, il n'est pas nécessaire de changer. SenseVoice est fait pour quand vous avez besoin du chinois, du japonais, du coréen ou du cantonais — et que vous le voulez rapidement.
Journal des modifications complet : whispernotes.app/changelog
Questions ou commentaires : mac@whispernotes.app