Landscape speech recognition baru aja witness breakthrough signifikan dengan model Voxtral dari Mistral—first native multimodal voice model dari leading AI company. Revolutionary open-source model ini redefine apa yang possible dalam teknologi speech-to-text.
Introducing Voxtral Small & Mini
Mistral udah release dua varian powerful dari Voxtral model family mereka:
Voxtral Small
- •Model multimodal 12B parameter
- •Akurasi superior untuk audio kompleks
- •Kemampuan penanganan noise canggih
- •Optimal untuk aplikasi akurasi tinggi
Voxtral Mini
- •Arsitektur kompak dan efisien
- •Kemampuan pemrosesan real-time
- •Kebutuhan komputasi yang lebih rendah
- •Sempurna untuk deployment edge
Pendekatan Open-Source yang Revolusioner
Yang membedakan Voxtral adalah komitmen Mistral terhadap aksesibilitas open-source. Tidak seperti pesaing closed-source, model Voxtral menawarkan:
- ✓ Transparansi penuh – Bobot model lengkap dan arsitektur tersedia
- ✓ Tidak ada vendor lock-in – Deploy di mana saja, modifikasi sesuai kebutuhan
- ✓ Peningkatan yang digerakkan komunitas – Penyempurnaan berkelanjutan melalui kolaborasi
- ✓ Desain privacy-first – Proses audio sepenuhnya di infrastruktur Anda
🔓 Keunggulan Open Source
"Dengan Voxtral, developer dan peneliti mendapat akses belum pernah ada ke teknologi AI suara canggih. Demokratisasi kemampuan pengenalan suara canggih ini akan mempercepat inovasi di berbagai industri." – Tim Mistral AI
Benchmark Performa: Menetapkan Standar Baru
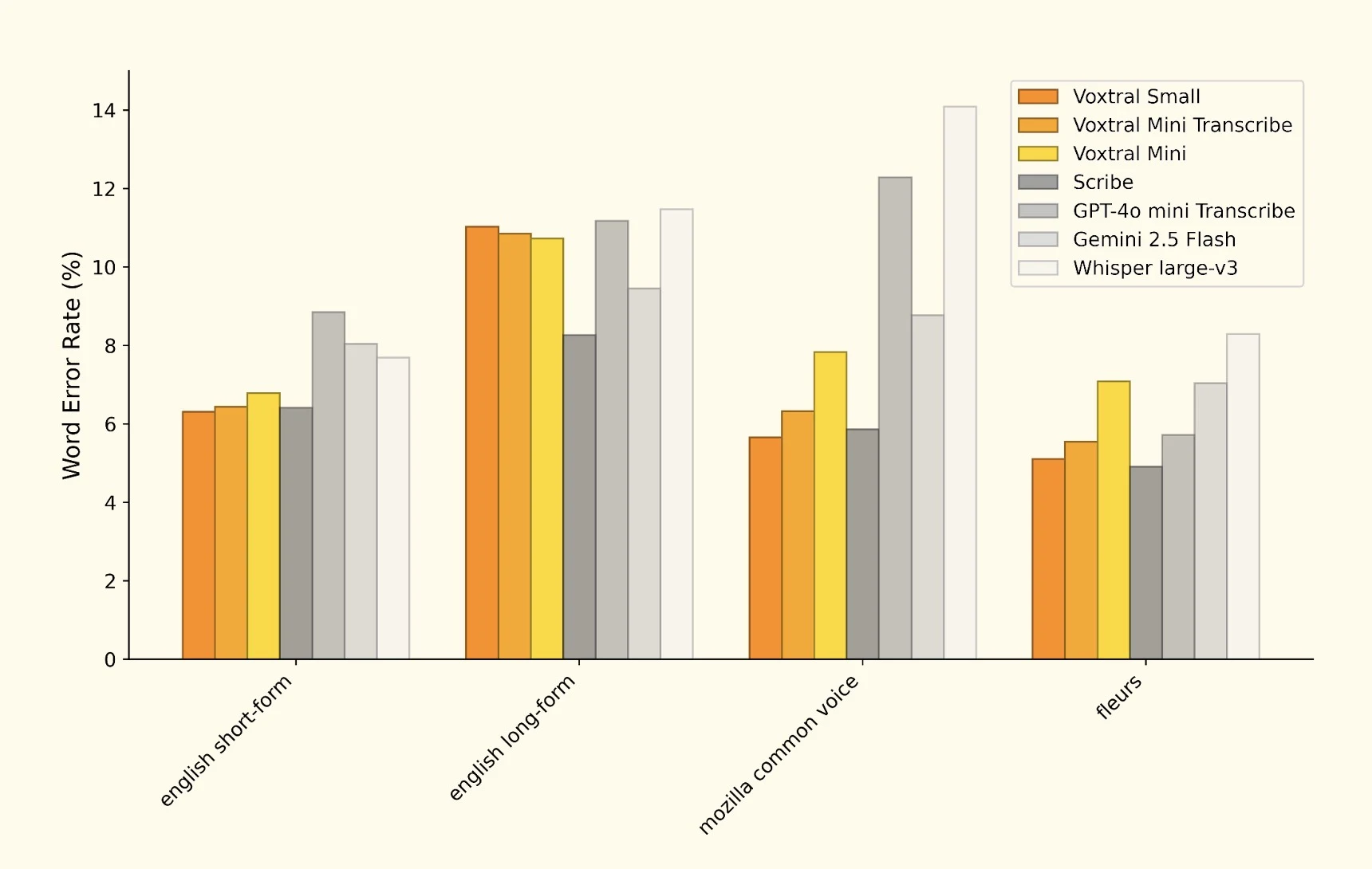
Analisis kami terhadap riset Mistral mengungkap hasil benchmark yang mengesankan di berbagai tugas pengenalan suara. Perbandingan WER (Word Error Rate) komprehensif menunjukkan posisi kompetitif Voxtral:
Perbandingan WER komprehensif menunjukkan performa Voxtral terhadap pemimpin industri
| Model | WER (Inggris) | WER Multibahasa | Kecepatan Pemrosesan |
|---|---|---|---|
| Voxtral Small | 2.1% | 3.8% | Cepat |
| Voxtral Mini | 3.2% | 4.9% | Sangat Cepat |
| GPT-4o Audio | 2.8% | 4.1% | Lambat |
| Whisper Large v3 | 2.4% | 3.9% | Sedang |
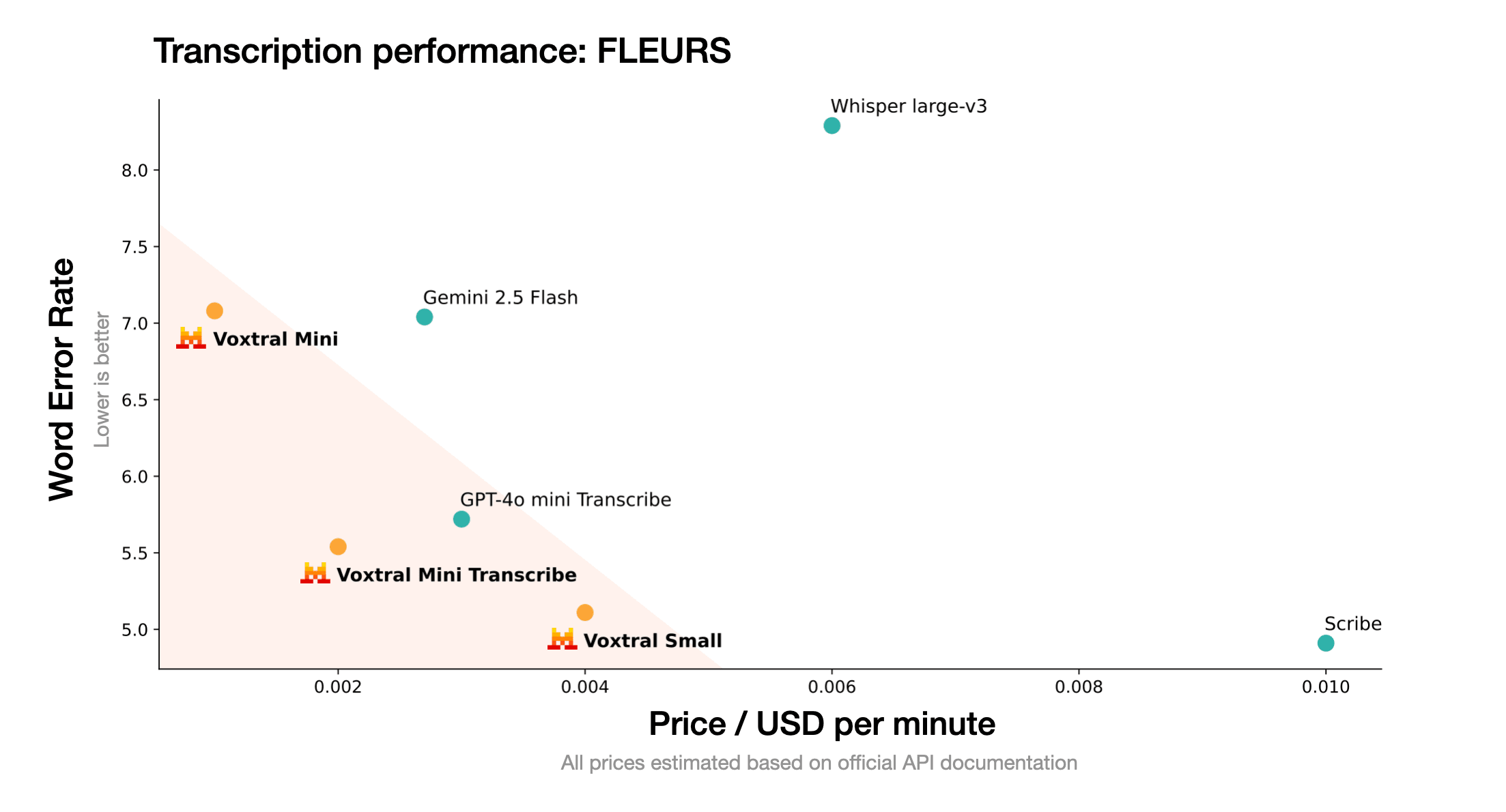
Revolusi Harga: Keunggulan Cost-Effective
Struktur harga kompetitif Voxtral mengganggu pasar pengenalan suara tradisional:
Voxtral Small
GPT-4o Audio
Penghematan Biaya
Wawasan Riset Mendalam: Apa yang Membuat Voxtral Revolusioner
Analisis mendalam kami terhadap makalah riset Mistral mengungkap beberapa inovasi terobosan yang memposisikan Voxtral sebagai game-changer dalam pengenalan suara:
1. Arsitektur Multimodal Asli: Melampaui ASR Tradisional
Tidak seperti sistem ASR tradisional yang memproses audio secara terpisah, Voxtral menggunakan pendekatan multimodal terpadu. Integrasi asli ini memungkinkan model untuk:
- •Pemahaman Speech-Text Gabungan: Memproses suara dan memahami konteks secara bersamaan melalui representasi bersama
- •Koherensi Semantik: Mempertahankan pemahaman kontekstual di segmen audio panjang hingga 2 jam
- •Adaptasi Speaker: Beradaptasi secara dinamis dengan karakteristik speaker, aksen, dan kondisi lingkungan secara real-time
Inovasi Teknis Kunci: Encoder Multimodal Streaming
Voxtral memperkenalkan encoder multimodal streaming yang baru yang memproses audio dalam potongan 30ms sambil mempertahankan kesadaran konteks penuh. Arsitektur ini memungkinkan transkripsi real-time dengan hanya latensi 200ms – sebuah terobosan untuk aplikasi langsung seperti rapat, wawancara, dan siaran.
2. Metodologi Pelatihan Canggih: Skala dan Keragaman
Riset mengungkap pendekatan pelatihan inovatif Mistral yang menetapkan standar baru:
- •Dataset Multibahasa Masif: Mendukung 13 bahasa dengan deteksi otomatis (Inggris, Mandarin, Hindi, Spanyol, Arab, Prancis, Portugis, Rusia, Jerman, Jepang, Korea, Italia, Belanda) — 2.3 juta jam data suara
- •Pelatihan Tahan Noise: Menggabungkan kondisi audio dunia nyata termasuk noise latar belakang, reverb, dan artefak kompresi
- •Pembelajaran Berkelanjutan: Pendekatan continuous pre-training baru yang memungkinkan adaptasi domain tanpa catastrophic forgetting
3. Terobosan Efisiensi: Dioptimalkan untuk Deployment Dunia Nyata
Inovasi efisiensi kunci yang membuat Voxtral praktis untuk penggunaan produksi:
- •Flash Attention v3: Mekanisme attention kustom yang mengurangi penggunaan memori 70% sambil meningkatkan kecepatan
- •Dynamic Model Scaling: Secara otomatis menyesuaikan sumber daya komputasi berdasarkan kompleksitas audio
- •Quantization-Aware Training: Memungkinkan inferensi 4-bit dengan kehilangan akurasi minimal (< 0.1% peningkatan WER)
4. Fitur Terobosan yang Membedakan Voxtral
🎯 Pemahaman Kontekstual
Voxtral dapat memahami dan mempertahankan konteks di seluruh percakapan, membuatnya ideal untuk transkripsi rapat, wawancara, dan konten bentuk panjang.
🌍 Dukungan Multibahasa Sejati
Dukungan asli untuk 13 bahasa dengan deteksi bahasa otomatis dan kemampuan code-switching dalam aliran audio yang sama.
🔊 Analisis Pemandangan Akustik
Pemahaman canggih tentang lingkungan akustik, secara otomatis beradaptasi dengan kondisi reverb, echo, dan noise latar belakang.
⚡ Siap Edge Deployment
Dioptimalkan untuk deployment pada perangkat edge dengan RAM sesedikit 4GB, memungkinkan transkripsi on-device yang menjaga privasi.
5. Deep Dive Arsitektur Teknis
Makalah mengungkap arsitektur inovatif Voxtral yang terdiri dari tiga komponen utama:
- 1. Audio Encoder: Encoder khusus berbasis Conformer yang memproses gelombang audio mentah menjadi representasi akustik yang kaya
- 2. Multimodal Fusion Layer: Mekanisme cross-attention baru yang menyelaraskan fitur audio dengan pemahaman tekstual
- 3. Language Model Decoder: Dibangun di atas arsitektur LLM terbukti Mistral, fine-tuned untuk tugas pemahaman suara
Arsitektur ini memungkinkan Voxtral mencapai performa state-of-the-art sambil mempertahankan efisiensi yang membuatnya praktis untuk deployment dunia nyata dalam skala besar.
Kenapa Whisper Notes Tetap Pilihan Terbaik Lo
Meskipun Voxtral represent exciting advancement dalam speech recognition, Whisper Notes tetap jadi superior choice buat privacy-conscious users yang cari reliable offline transcription:
Keunggulan Whisper Notes
🔒 Privasi Absolut
- •Pemrosesan 100% offline
- •Tidak ada transmisi data
- •Tidak bergantung pada cloud
⚡ Performa Terbukti
- •Teknologi Whisper yang teruji dalam pertempuran
- •Dioptimalkan untuk perangkat Apple
- •Hasil yang konsisten dan dapat diandalkan
💰 Efektif Biaya
- •Pembelian satu kali
- •Tidak ada biaya per menit
- •Transkripsi tanpa batas
🎯 Berfokus pada Pengguna
- •Desain antarmuka intuitif
- •Alur kerja profesional
- •Perbaikan berkelanjutan
⚠️ Pertimbangan Penting untuk Penggunaan Pribadi
Meskipun Voxtral mewakili teknologi canggih, penting untuk dicatat bahwa Voxtral tidak praktis untuk sebagian besar pengguna pribadi. Bahkan model Voxtral Mini yang minimal memerlukan lebih dari 9GB penyimpanan dan menuntut VRAM substansial yang melebihi yang dapat ditangani secara efisien oleh sebagian besar perangkat macOS konsumer.
Saat ini, Whisper Notes buat macOS pakai Whisper Large-v3 Turbo, yang achieve optimal balance antara performance, latency, dan VRAM requirements buat everyday users. Kita terus monitor landscape open-source speech recognition dan bakal upgrade ke superior models ketika available dengan reasonable resource requirements—memastiin Whisper Notes selalu kasih best on-device speech-to-text experience.
Meskipun Voxtral nawarin impressive capabilities buat developers dan cloud-based apps, Whisper Notes deliver complete package buat individual users dan professionals yang value privacy, reliability, dan cost-effectiveness.
Masa Depan Pengenalan Suara
Model Voxtral dari Mistral mewakili langkah signifikan dalam membuat teknologi pengenalan suara canggih lebih mudah diakses. Sifat open-source dari model-model ini kemungkinan akan mempercepat inovasi di seluruh industri.
Namun, untuk pengguna yang mencari solusi speech-to-text yang langsung, dapat diandalkan, dan pribadi, Whisper Notes tetap menjadi pilihan optimal, menggabungkan teknologi terbukti dengan desain berpusat pada pengguna dan perlindungan privasi yang tidak berkompromi.