TL;DR — Perbandingan Tiga Model Mac
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 menit Inggris | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| 27 menit Mandarin | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| Bahasa | 25 (Eropa) | 5 (zh, en, ja, ko, yue) | 99+ |
| Unduhan | 465 MB | 827 MB | 1.5 GB |
| Memori | ~800 MB | ~700 MB | ~1.6 GB |
| Terbaik untuk | Inggris & Eropa | Mandarin, Jepang, Korea, Kanton | Semua bahasa lainnya (99+) |
* Benchmark kecepatan pada Apple M4 Pro, 32 GB. Podcast Inggris 5 menit dan podcast Mandarin 27 menit. Faktor realtime = durasi audio ÷ waktu pemrosesan (lebih tinggi = lebih cepat). SenseVoice hanya untuk macOS. iOS menggunakan Parakeet (via ANE) dan Whisper.
Mulai dari versi 1.4.8, Whisper Notes untuk Mac menggunakan SenseVoice Small sebagai engine khusus untuk transkripsi Mandarin, Jepang, Korea, dan Kanton. Menggantikan Qwen3-ASR dan berjalan di GPU Apple melalui MLX alih-alih CPU — memproses podcast Mandarin 27 menit dalam 13.83 detik, bukan 3 menit 44 detik.
Mengapa Kami Mengganti Qwen3-ASR
Qwen3-ASR adalah model yang bagus. Mendukung 30 bahasa plus 22 dialek Mandarin, dan akurasi Mandarinnya mendekati state-of-the-art. Tapi ada masalah yang semakin parah seiring audio semakin panjang: kecepatan.
Qwen3 menggunakan arsitektur autoregressive — pendekatan yang sama dengan Whisper, memproses audio frame demi frame, tidak pernah melompat ke depan. Untuk podcast Mandarin 27 menit, butuh 73 detik. Bisa digunakan, tapi bukan pengalaman hasil instan yang Parakeet V3 berikan untuk bahasa Inggris.
Masalah yang lebih dalam ada di infrastruktur kami. Integrasi Qwen3 menggunakan sherpa-onnx, library C dengan Swift wrapper 2.249 baris yang merutekan semua melalui CPU. GPU Mac menganggur.
SenseVoice memperbaiki kedua masalah tersebut. Arsitektur non-autoregressive untuk kecepatan. Apple MLX untuk akselerasi GPU. Hasilnya: peningkatan kecepatan 16.2× pada hardware yang sama, dengan codebase berkurang dari 2.249 baris menjadi 288.
Benchmark
Ketiga model berjalan pada Apple M4 Pro yang sama, file audio yang sama, kondisi yang sama. Tanpa cloud. Tanpa internet. Hanya silicon.
| Model | 5 menit Inggris | 27 menit Mandarin | Kecepatan (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103–161× |
| SenseVoice Small | 5.8s | 13.83s | 52–118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13–14× |
| Qwen3-ASR (dihapus) | — | 73s | 4.7× |
SenseVoice kira-kira setengah kecepatan Parakeet V3 — tapi tetap luar biasa cepat. Podcast 27 menit selesai dalam kurang dari 14 detik. Anda tekan transkripsi, tarik napas sekali, dan teksnya sudah ada.
Bandingkan dengan Whisper yang butuh 2 menit 4 detik, atau Qwen3 lama yang butuh 73 detik. Arsitektur lebih penting daripada jumlah parameter.
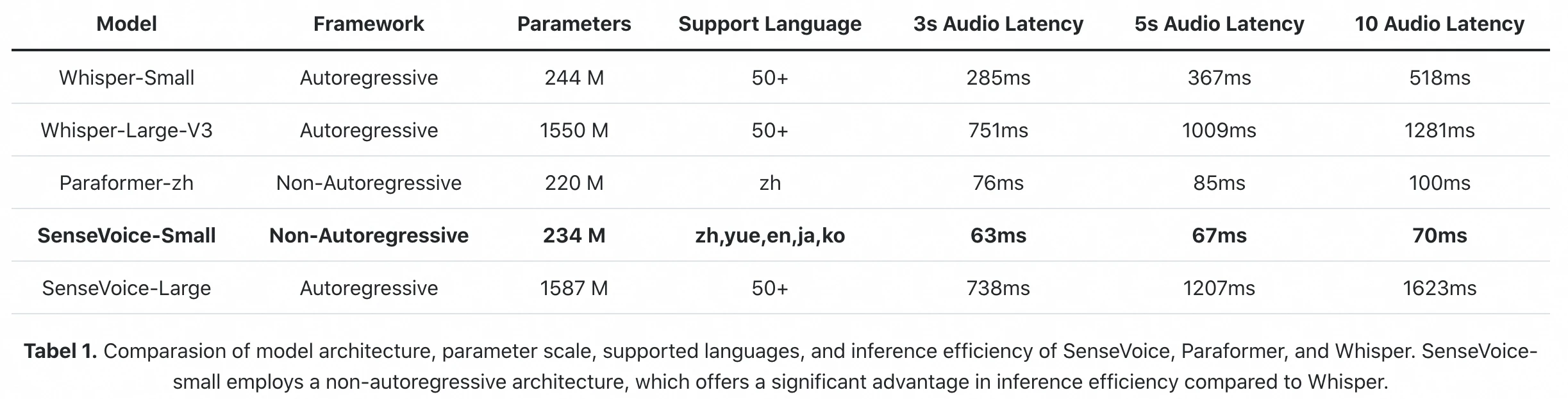
Benchmark inferensi resmi dari paper FunAudioLLM: SenseVoice-Small memproses 10s audio dalam 70ms (A800 GPU). Whisper-Large-V3 butuh 1.281ms. Perbedaan 18× dalam latensi inferensi mentah.
| Model | Waktu Muat | Memori | Ukuran Unduhan |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* Waktu muat dan memori diukur pada Apple M4 Pro, 32 GB.
SenseVoice dimuat dalam kurang dari satu detik dan menggunakan memori lebih sedikit daripada Parakeet. Di Mac 8 GB, berjalan nyaman bersama aplikasi lainnya.
Mengapa SenseVoice Lebih Cepat: Arsitektur + Runtime
Perbedaan kecepatan antara Qwen3-ASR dan SenseVoice berasal dari dua faktor independen.
Faktor 1: Arsitektur model. Qwen3-ASR bersifat autoregressive — menghasilkan token satu per satu, masing-masing bergantung pada yang sebelumnya. SenseVoice menggunakan encoder non-autoregressive (NAR) yang memproses seluruh audio secara paralel. Perbedaan arsitektur ini saja membuat SenseVoice secara fundamental lebih cepat, terlepas dari hardware yang digunakan.
Faktor 2: Runtime. Integrasi Qwen3-ASR kami menggunakan sherpa-onnx, yang berjalan di CPU. SenseVoice berjalan melalui Apple MLX, merutekan komputasi ke GPU. Bisakah Qwen3 juga berjalan di MLX? Ya — tapi tetap akan lebih lambat dari SenseVoice karena bottleneck autoregressive ada di arsitektur, bukan runtime.
| Qwen3-ASR (lama) | SenseVoice (baru) | |
|---|---|---|
| Arsitektur | Autoregressive (token per token) | Non-autoregressive (paralel) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 menit Mandarin | 224 detik | 13.83 detik |
| Percepatan gabungan | baseline | 16.2× lebih cepat |
| Codebase | Framework C 168 MB + 2.249 baris Swift | 288 baris Swift Actor |
* Podcast Mandarin 27 menit yang sama, Apple M4 Pro. Percepatan 16.2× menggabungkan peningkatan arsitektur (NAR vs AR) dan runtime (GPU vs CPU).
Kodenya juga lebih sederhana. Implementasi SenseVoice baru adalah satu Swift Actor 288 baris yang berkomunikasi langsung dengan MLX, menggantikan framework C 168 MB. Lebih sedikit kode, lebih sedikit bug, aplikasi lebih kecil.
Lima Bahasa, Dikerjakan dengan Baik
SenseVoice tidak mencoba melakukan semuanya. Ia menangani lima bahasa:
| Bahasa | SenseVoice-Small | Whisper-Large-V3 | Pemenang |
|---|---|---|---|
| Mandarin (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| Kanton (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| Jepang (ja) | 11.96% CER | 10.34% CER | Whisper (sedikit) |
| Korea (ko) | 8.28% CER | 5.59% CER | Whisper |
| Inggris (en) | 14.71% WER | 9.39% WER | Whisper (gunakan Parakeet) |
* Benchmark CommonVoice, CER = Character Error Rate, WER = Word Error Rate. Lebih rendah lebih baik. Sumber: paper FunAudioLLM (2024). Latensi inferensi SenseVoice-Small: 70ms per 10s audio (A800 GPU), lebih dari 15× lebih cepat dari Whisper-Large-V3.
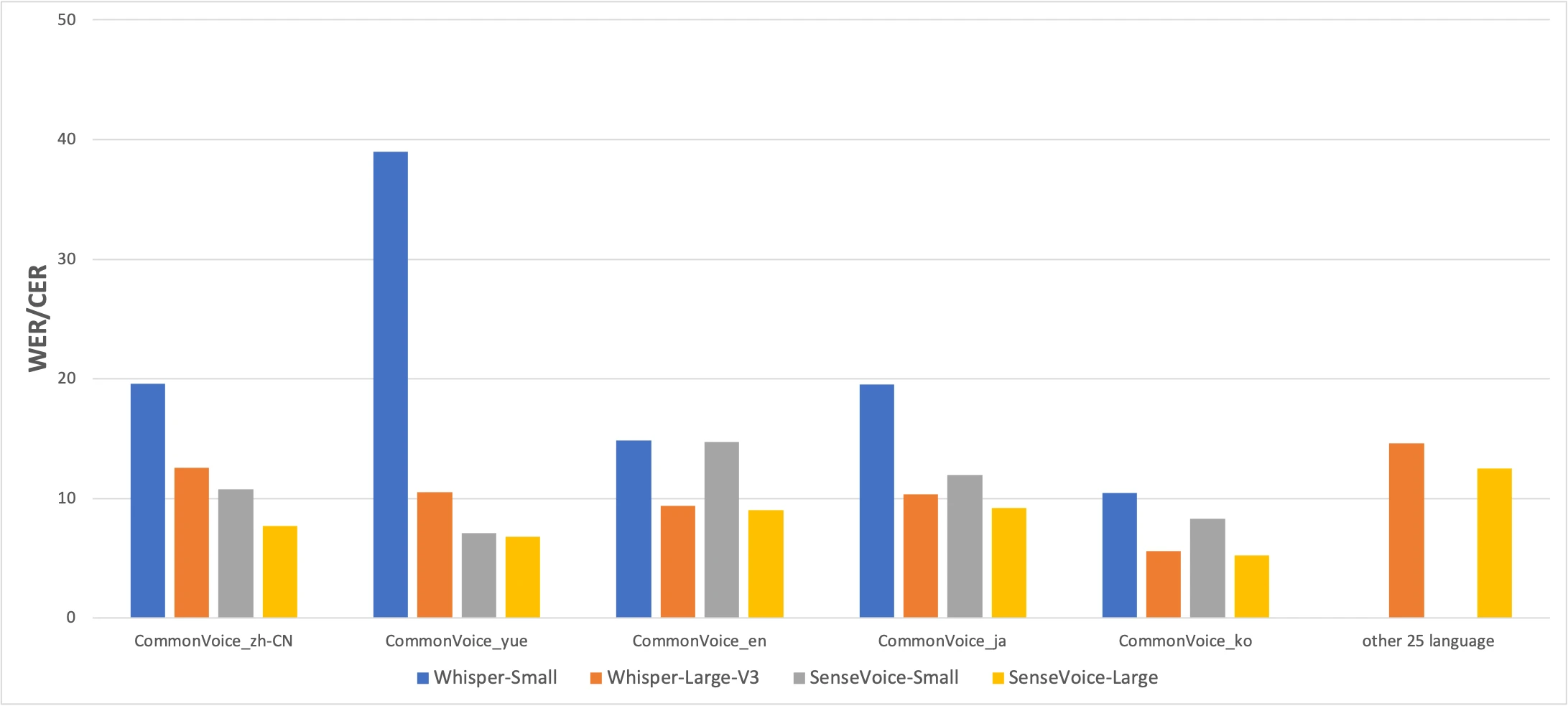
Benchmark CommonVoice: SenseVoice-Small (kuning) vs Whisper-Small (biru) vs Whisper-Large-V3 (oranye). Lebih rendah lebih baik. Sumber: paper FunAudioLLM
Angka-angka bercerita jujur. SenseVoice mengalahkan Whisper dalam akurasi Mandarin dan Kanton dengan margin signifikan, sementara Whisper lebih akurat untuk Jepang, Korea, dan Inggris. Tapi SenseVoice lebih dari 15× lebih cepat dari Whisper-Large-V3. Untuk penggunaan nyata, perbedaan kecepatan lebih penting dari beberapa persen akurasi.
Hasil Kanton layak disorot tersendiri. Whisper-Small mendapat 38.97% CER untuk Kanton — nyaris tidak bisa digunakan. Bahkan Whisper-Large-V3 hanya mencapai 10.41%. SenseVoice mencapai 7.09%. Sebelum SenseVoice, tidak ada cara yang baik untuk mentranskripsi Kanton secara lokal di Mac. Jika Anda berbicara Kanton, model ini ada untuk Anda.
Transkripsi Korea dengan SenseVoice: impor video dengan subtitle bertimestamp
Tes Dunia Nyata: Podcast Mandarin 27 Menit
Kami mentranskripsi episode 27 menit Thirteen Invitations (十三邀), podcast wawancara Mandarin, dengan SenseVoice dan Whisper Large V3 Turbo di M4 Pro yang sama. ElevenLabs Scribe (cloud) sebagai referensi. Kedua model on-device membuat jumlah kesalahan yang kurang lebih sama, tapi jenis yang berbeda:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Waktu | 13.83s | 2 min 4s |
| Kesalahan (sampel 5 menit) | ~15–20 | ~12–15 |
| Kesalahan terburuk | 时差→食堂 (zona waktu→kantin) | 西昌→西藏 (kota Xīchāng→Tibet, meleset 4.000 km) |
| Pola kesalahan | Pertukaran homofon | Kesalahan geografis/faktual |
* Perbandingan manual terhadap ElevenLabs Scribe (referensi cloud, juga tidak sempurna). Kedua model on-device menulis "根深蒂固" dengan benar sementara Scribe salah.
Akurasi sebanding. 9× lebih cepat. Untuk transkripsi Mandarin dunia nyata, SenseVoice memberi Anda transkrip yang bisa digunakan sebelum Whisper selesai loading.
Kapan Menggunakan Model Mana
Whisper Notes untuk Mac kini menyertakan empat model suara. Masing-masing dioptimalkan untuk skenario berbeda:
| Anda butuh... | Gunakan model ini | Alasan |
|---|---|---|
| Inggris atau bahasa Eropa, kecepatan maksimum | Parakeet V3 | 103× realtime, error rate terendah. Default. |
| Mandarin, Jepang, Korea, atau Kanton | SenseVoice Small | 52–118× realtime. Satu-satunya model dengan dukungan Kanton. |
| Salah satu dari 99+ bahasa (Arab, Thai, Rusia, dll.) | Whisper Large V3 Turbo | Dukungan bahasa terluas. Lebih lambat tapi universal. |
| Penggunaan memori rendah (Mac lama) | Whisper Small | 487 MB memori. Cocok untuk Mac 8 GB. |
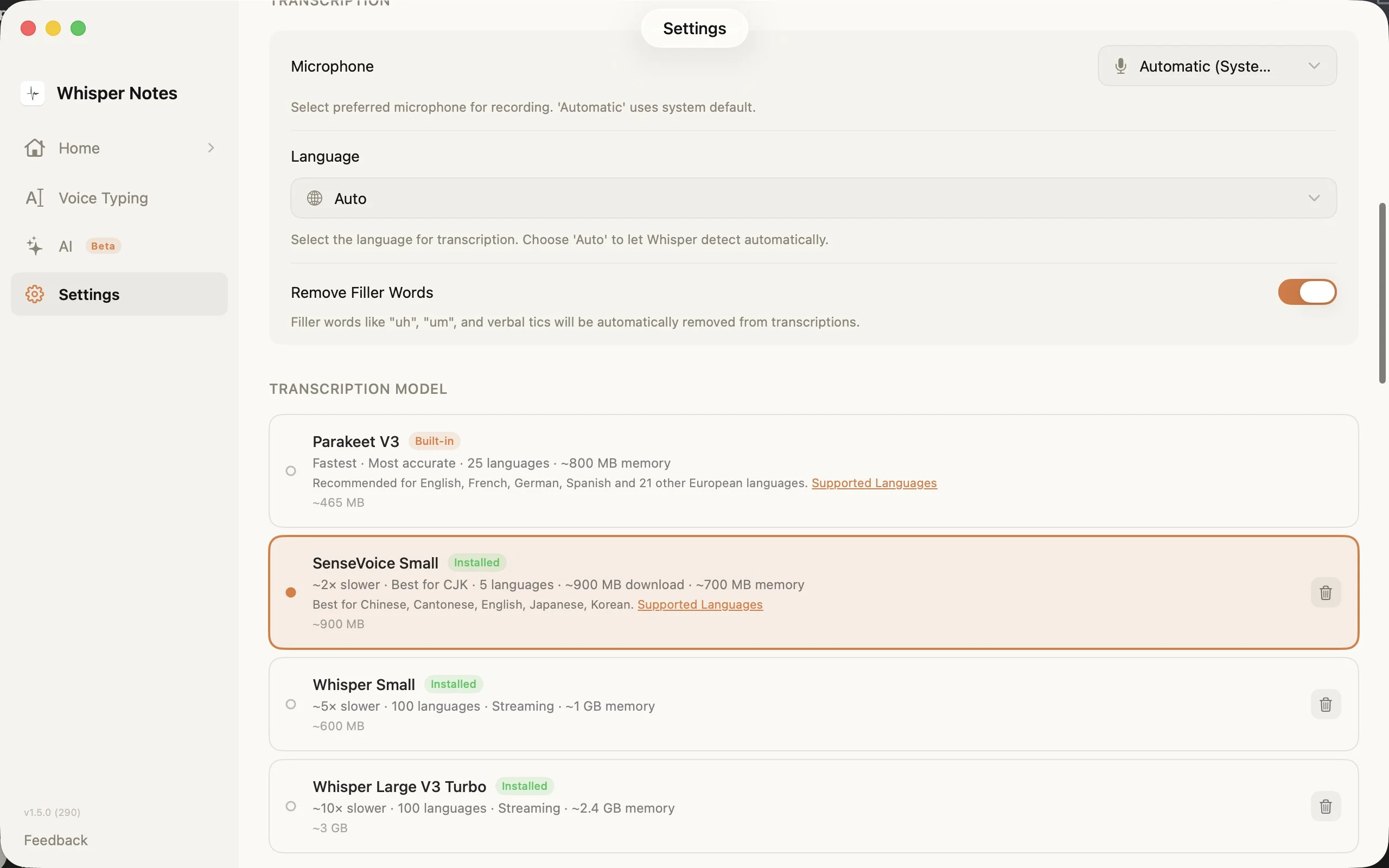
Pengaturan → Model Transkripsi: pilih engine yang tepat untuk bahasa Anda
Pemilih model di Pengaturan menampilkan keempat opsi dengan ukuran unduhan, jumlah bahasa, dan kebutuhan memori. SenseVoice diunduh pada penggunaan pertama (~827 MB) dan tersimpan di perangkat Anda.
Kompromi
SenseVoice bukan model universal. Berikut yang tidak bisa dilakukannya:
• Hanya 5 bahasa. Jika Anda butuh Thai, Rusia, Arab, Hindi, atau 90+ bahasa lain yang didukung Whisper, gunakan Whisper.
• Hanya Mac. SenseVoice berjalan via Apple MLX, yang membutuhkan macOS. Tidak tersedia di iPhone. Pengguna iOS punya Parakeet (untuk bahasa Eropa) dan Whisper.
• Quirk audio pelan. Selama segmen yang sangat pendek atau sangat pelan, SenseVoice terkadang bisa jatuh ke output Mandarin terlepas dari bahasa yang dipilih. Mengatur bahasa secara manual (bukan "Otomatis") mengurangi ini.
• Tanpa streaming. Tidak seperti mode streaming Whisper, SenseVoice memproses seluruh audio setelah rekaman. Untuk file panjang, ia otomatis memotong di titik hening dan menampilkan hasil secara progresif.
Ini adalah batasan arsitektur, bukan bug. Model yang dilatih pada 5 bahasa melakukan 5 bahasa itu dengan sangat baik. Dukungan 99+ bahasa Whisper datang dengan kecepatan lebih lambat dan error rate lebih tinggi pada setiap bahasa individual.
Coba Sekarang
SenseVoice tersedia di Whisper Notes untuk Mac v1.4.8 dan yang lebih baru. Unduh dari Pengaturan → Model Transkripsi → SenseVoice Small (~827 MB). Membutuhkan Mac Apple Silicon (M1 atau lebih baru).
Jika Anda menggunakan Parakeet V3 dan kebanyakan mendikte dalam bahasa Inggris, tidak perlu beralih. SenseVoice untuk ketika Anda butuh Mandarin, Jepang, Korea, atau Kanton — dan Anda ingin cepat.
Changelog lengkap: whispernotes.app/changelog
Pertanyaan atau masukan: mac@whispernotes.app