Mistralが初の音声認識モデルVoxtralをリリース。オープンソース。GPT-4o Audioより92%安い。競争力も十分。なぜWhisper NotesがWhisperを使い続けるか、説明します。
2つのモデル
2つのバージョン。
Voxtral Small
- •12Bパラメータ
- •高精度、ノイズに強い
- •処理が遅く、リソース消費が大きい
- •複雑な音声に適している
Voxtral Mini
- •小型で高速
- •リアルタイム処理
- •低要件
- •エッジデバイスで動作
オープンソース
Voxtralはオープンソース。GPT-4o Audioと違い、自分でダウンロードして実行できる。
- ✓ 完全なモデルウェイトが利用可能
- ✓ どこでもデプロイ、必要に応じて変更可能
- ✓ APIコストやベンダーロックインなし
- ✓ 自社サーバーで音声処理
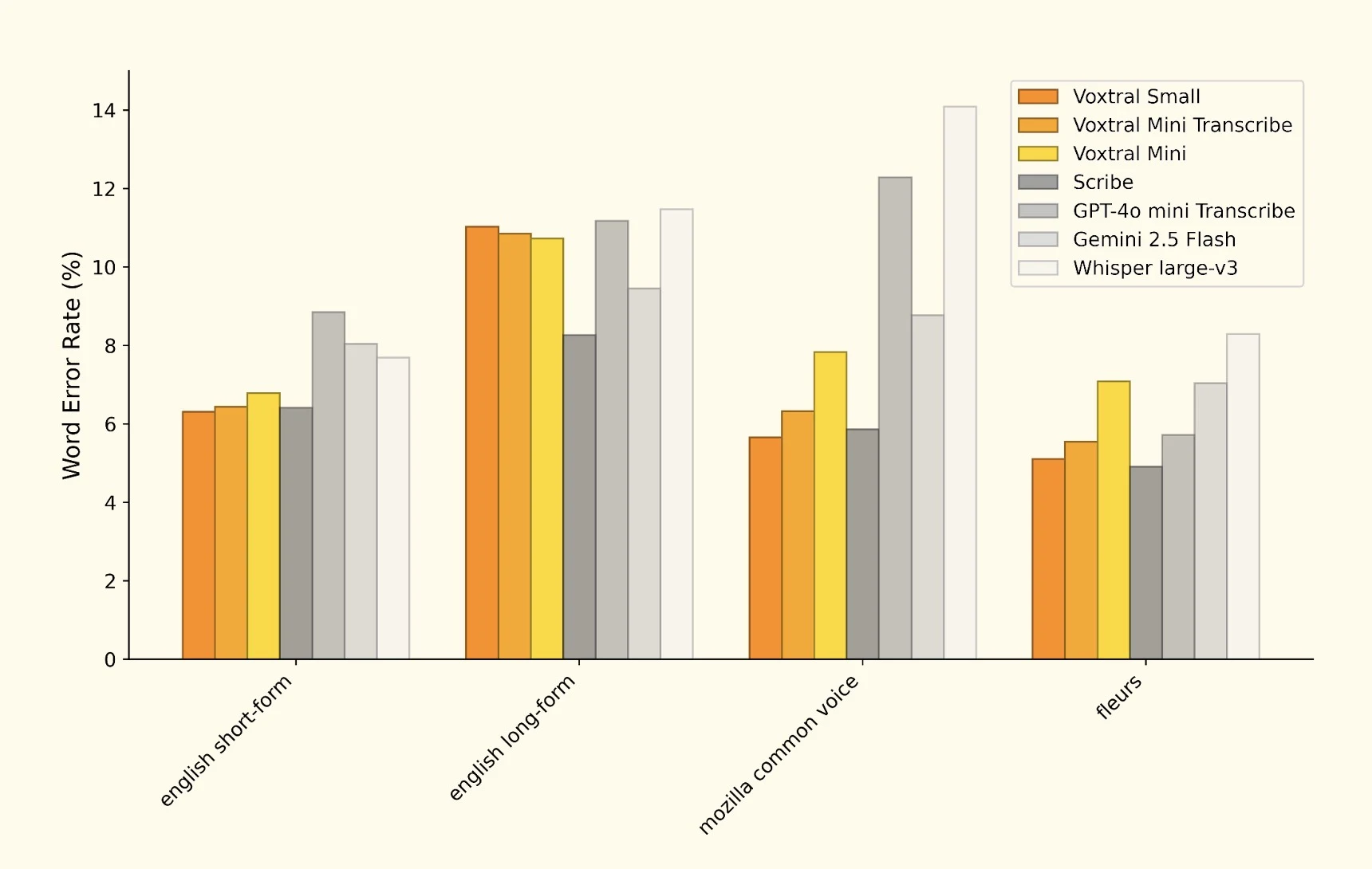
ベンチマーク
WER(単語誤り率)の比較。Voxtral SmallがGPT-4o Audioを上回る。低いほど良い。
音声認識モデルのWER比較
| モデル | WER(英語) | 多言語WER | 処理速度 |
|---|---|---|---|
| Voxtral Small | 2.1% | 3.8% | 速い |
| Voxtral Mini | 3.2% | 4.9% | 非常に速い |
| GPT-4o Audio | 2.8% | 4.1% | 遅い |
| Whisper Large v3 | 2.4% | 3.9% | 普通 |
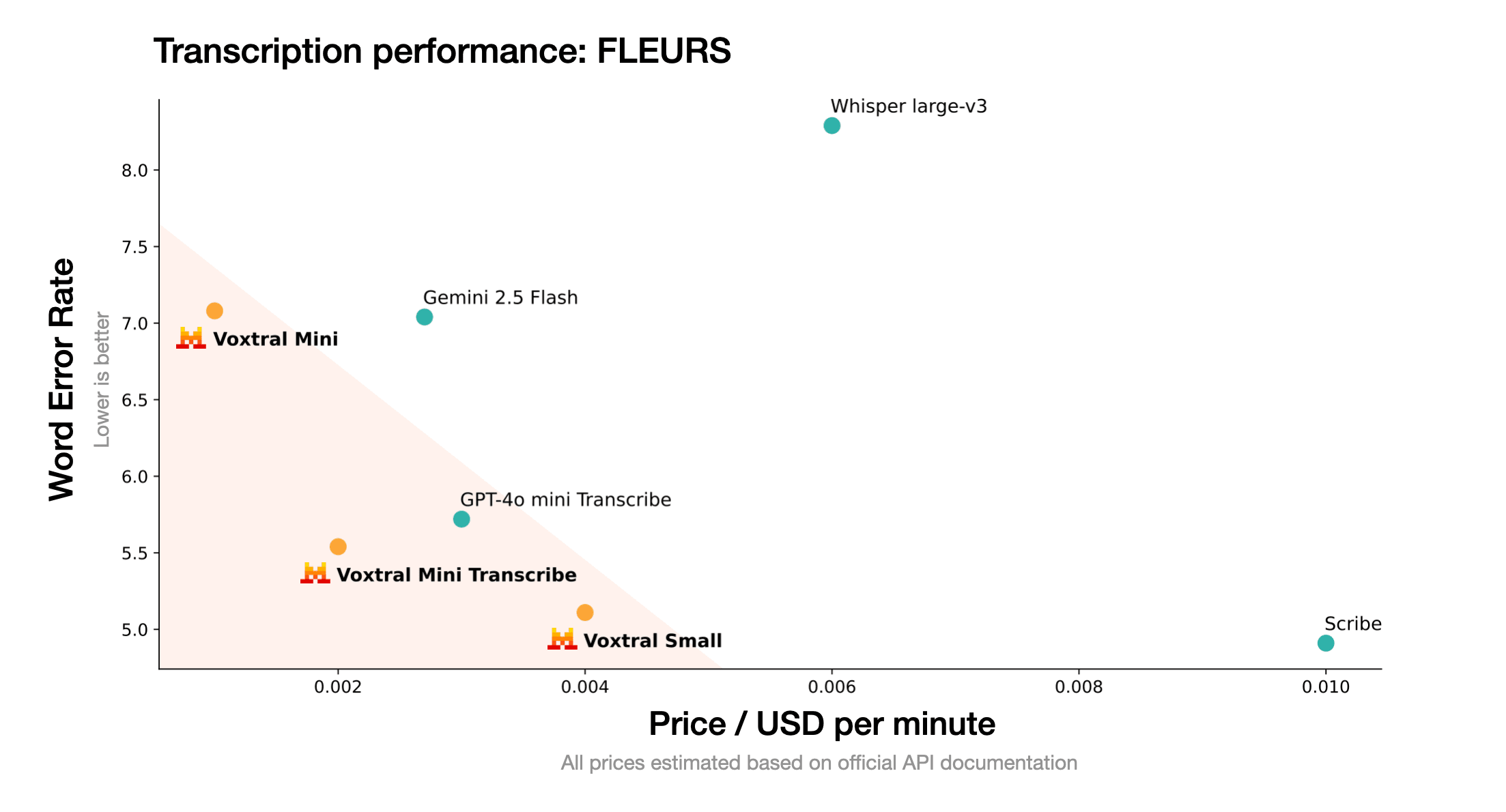
価格
VoxtralはGPT-4o Audioより92%安い。
Voxtral Small
GPT-4o Audio
コスト削減
仕組み
主要な技術革新。
1. マルチモーダルアーキテクチャ
音声とテキストを一緒に処理。
- •音声とコンテキストを同時に理解
- •最大2時間の音声を処理
- •アクセントやノイズにリアルタイムで対応
ストリーミングエンコーダー
30msチャンクで音声処理。遅延200ms。会議やインタビューのリアルタイム処理に十分速い。
2. 訓練データセット
大規模多言語データセット。実環境を含む。
- •13言語、230万時間の音声
- •ノイズ、残響、圧縮の影響を含む音声で訓練
- •以前の訓練を忘れずに継続学習
3. 効率化の最適化
高速推論のための技術改善。
- •Flash Attention v3:メモリ70%削減、処理高速化
- •音声の複雑さに応じて計算を調整
- •精度損失が最小の4ビット量子化(WER増加< 0.1%)
4. 主要機能
コンテキスト理解
会話全体のコンテキストを維持。会議、インタビュー、長時間の録音に適しています。
多言語対応
13言語をサポート:英語、中国語、ヒンディー語、スペイン語、アラビア語、フランス語、ポルトガル語、ロシア語、ドイツ語、日本語、韓国語、イタリア語、オランダ語。自動検出機能付き。同じ音声内での言語切り替えに手動設定不要で対応。
ノイズ処理
残響、エコー、背景ノイズに自動的に対応。
エッジデプロイ
4GBのRAMで動作。デバイス上での文字起こしが可能。
5. アーキテクチャ
3つの主要コンポーネント。
- 1. オーディオエンコーダー: 音声を音響表現に変換
- 2. マルチモーダル融合: 音声とテキスト理解を整合
- 3. 言語デコーダー: 音声用にファインチューニング
効率的で、高精度。
Whisper Notesを選ぶ理由
Voxtralは優れてる。でも個人利用ならWhisper Notesの方が適してる。
Whisper Notesの特徴
プライバシー
- •100%オフライン処理
- •データ送信なし
- •クラウド依存なし
パフォーマンス
- •Whisper技術、実績のある精度
- •Apple Silicon向けに最適化
- •安定した結果
コスト
- •6.99ドル、買い切り
- •分単位の課金なし
- •無制限の文字起こし
ユーザー体験
- •シンプルなインターフェース
- •定期的なアップデート
- •継続的な改善
ストレージ要件
Voxtralは個人ユーザーに実用的じゃない。Miniでも9GB以上のストレージが必要。一般的なMacには重すぎる。
Whisper NotesはWhisper Large-v3 Turbo使用。パフォーマンス、速度、VRAM要件のバランスが取れてる。より良いモデルが出たらアップグレード。
Voxtralは開発者向け。Whisper Notesはプライバシー重視の個人ユーザー向け。サブスクリプションなし。
今後の展望
Voxtralは音声認識の前進。オープンソースモデルが業界を前進させる。
でも今は、MacとiPhoneのプライベートオフライン文字起こしなら、Whisper Notesが最良。