W SKRÓCIE — Porównanie trzech modeli Mac
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min angielski | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 min chiński | 10,10s (161×) | 13,83s (118×) | 2 min 4s (13,1×) |
| Języki | 25 (europejskich) | 5 (zh, en, ja, ko, yue) | 99+ |
| Pobieranie | 465 MB | 827 MB | 1,5 GB |
| Pamięć | ~800 MB | ~700 MB | ~1,6 GB |
| Najlepszy do | Angielski & europejskie | Chiński, japoński, koreański, kantoński | Wszystko inne (99+ języków) |
* Testy szybkości na Apple M4 Pro, 32 GB. 5-minutowy podcast po angielsku i 27-minutowy podcast po chińsku. Współczynnik czasu rzeczywistego = czas trwania audio ÷ czas przetwarzania (wyższy = szybszy). SenseVoice jest dostępny tylko na macOS. iOS używa Parakeet (przez ANE) i Whisper.
Od wersji 1.4.8, Whisper Notes dla Mac zawiera SenseVoice Small jako dedykowany silnik do transkrypcji chińskiego, japońskiego, koreańskiego i kantońskiego. Zastępuje Qwen3-ASR i działa na GPU Apple przez MLX zamiast CPU — przetwarzając 27-minutowy chiński podcast w 13,83 sekundy zamiast 3 minut i 44 sekund.
Dlaczego zastąpiliśmy Qwen3-ASR
Qwen3-ASR był solidnym modelem. Obsługiwał 30 języków plus 22 chińskie dialekty, a jego dokładność dla chińskiego była bliska najlepszym wynikom. Ale miał problem, który narastał z długością audio: szybkość.
Qwen3 używał architektury autoregresyjnej — tego samego podejścia co Whisper, przetwarzając audio klatka po klatce, nigdy nie przeskakując do przodu. Na 27-minutowym chińskim podkaście zajmowało to 73 sekundy. Użyteczne, ale dalekie od natychmiastowego wyniku, jaki Parakeet V3 zapewnia dla angielskiego.
Głębszym problemem była nasza infrastruktura. Nasza integracja Qwen3 korzystała z sherpa-onnx — biblioteki C z wrapperem Swift o 2 249 liniach, który kierował wszystko przez rdzenie CPU. GPU pozostawało bezczynne, podczas gdy CPU twojego Maca wykonywał całą pracę.
SenseVoice rozwiązał oba problemy. Nieavtoregresyjna architektura zapewniająca szybkość. Apple MLX dla akceleracji GPU. Rezultat: 16,2-krotne przyspieszenie na tym samym sprzęcie, z kodem zredukowanym z 2 249 do 288 linii.
Benchmark
Wszystkie trzy modele działają na tym samym Apple M4 Pro, te same pliki audio, te same warunki. Bez chmury. Bez internetu. Tylko krzem.
| Model | 5 min angielski | 27 min chiński | Szybkość (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103–161× |
| SenseVoice Small | 5,8s | 13,83s | 52–118× |
| Whisper Large V3 Turbo | 20,92s | 2 min 4s | 13–14× |
| Qwen3-ASR (usunięty) | — | 73s | 4,7× |
SenseVoice jest mniej więcej o połowę wolniejszy od Parakeet V3 — ale wciąż nadzwyczajnie szybki. 27-minutowy podcast jest gotowy w mniej niż 14 sekund. Naciskasz transkrybuj, czekasz jeden oddech i tekst jest na ekranie.
Porównaj to z Whisper — 2 minuty i 4 sekundy, albo starym Qwen3 — 73 sekundy. Architektura ma większe znaczenie niż liczba parametrów.
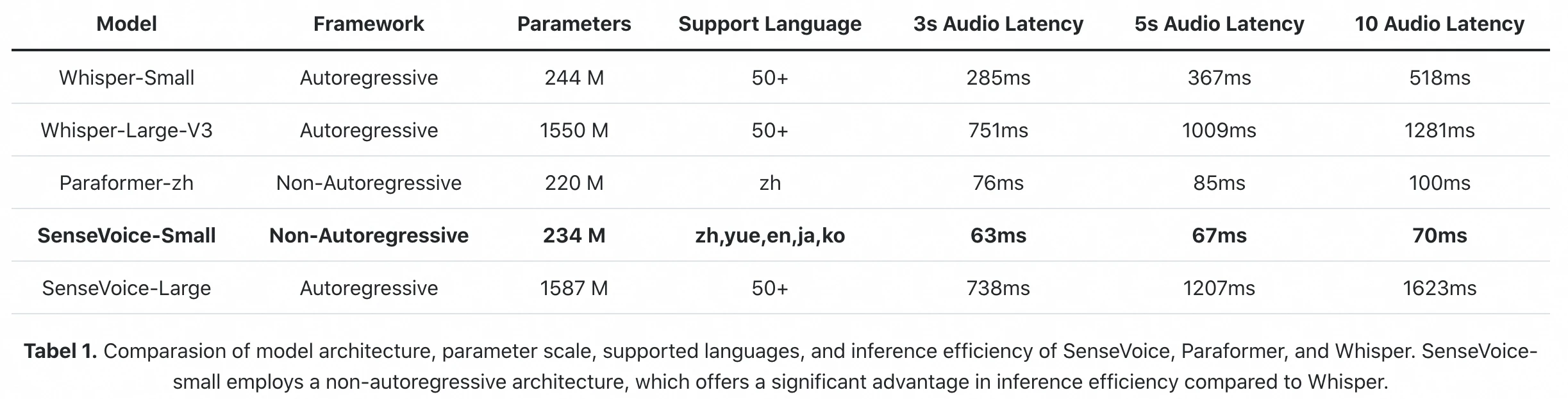
Oficjalny benchmark inferencji z artykułu FunAudioLLM: SenseVoice-Small przetwarza 10s audio w 70ms (GPU A800). Whisper-Large-V3 potrzebuje 1 281ms. To 18-krotna różnica w czystym opóźnieniu inferencji.
| Model | Czas ładowania | Pamięć | Rozmiar pobierania |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81s | ~700 MB | 827 MB |
| Whisper Small | 1,03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18s | ~1,6 GB | 3 GB |
* Czas ładowania i pamięć zmierzone na Apple M4 Pro, 32 GB.
SenseVoice ładuje się w mniej niż sekundę i zużywa mniej pamięci niż Parakeet. Na Macu z 8 GB działa komfortowo obok innych aplikacji.
Dlaczego SenseVoice jest szybszy: architektura + środowisko uruchomieniowe
Różnica w szybkości między Qwen3-ASR a SenseVoice wynika z dwóch niezależnych czynników.
Czynnik 1: Architektura modelu. Qwen3-ASR jest autoregresyjny — generuje tekst token po tokenie, każdy zależny od poprzedniego. SenseVoice używa nieavtoregresyjnego (NAR) enkodera, który przetwarza całe audio równolegle. Sama ta różnica architekturalna sprawia, że SenseVoice jest fundamentalnie szybszy, niezależnie od sprzętu.
Czynnik 2: Środowisko uruchomieniowe. Nasza integracja Qwen3-ASR używała sherpa-onnx, które działało na CPU. SenseVoice działa przez Apple MLX, kierując obliczenia na GPU. Czy Qwen3 mógłby też działać na MLX? Tak — ale wciąż byłby wolniejszy od SenseVoice, ponieważ wąskie gardło autoregresyjne tkwi w architekturze, nie w środowisku uruchomieniowym.
| Qwen3-ASR (stary) | SenseVoice (nowy) | |
|---|---|---|
| Architektura | Autoregresyjna (token po tokenie) | Nieavtoregresyjna (równoległa) |
| Środowisko uruchomieniowe | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min chiński | 224 sekundy | 13,83 sekundy |
| Łączne przyspieszenie | punkt odniesienia | 16,2× szybciej |
| Kod źródłowy | Framework C 168 MB + 2 249 linii Swift | 288 linii Swift Actor |
* Ten sam 27-minutowy chiński podcast, Apple M4 Pro. Przyspieszenie 16,2× łączy ulepszenia zarówno architekturalne (NAR vs AR), jak i środowiska uruchomieniowego (GPU vs CPU).
Kod też się uprościł. Nowa implementacja SenseVoice to pojedynczy Swift Actor o 288 liniach, komunikujący się bezpośrednio z MLX i zastępujący framework C o rozmiarze 168 MB. Mniej kodu, mniej błędów, lżejsza aplikacja.
Pięć języków, zrobionych dobrze
SenseVoice nie próbuje robić wszystkiego. Obsługuje pięć języków:
| Język | SenseVoice-Small | Whisper-Large-V3 | Zwycięzca |
|---|---|---|---|
| Chiński (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Kantoński (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japoński (ja) | 11,96% CER | 10,34% CER | Whisper (nieznacznie) |
| Koreański (ko) | 8,28% CER | 5,59% CER | Whisper |
| Angielski (en) | 14,71% WER | 9,39% WER | Whisper (użyj Parakeet) |
* Benchmark CommonVoice, CER = wskaźnik błędów znakowych, WER = wskaźnik błędów słownych. Niższy jest lepszy. Źródło: artykuł FunAudioLLM (2024). Opóźnienie inferencji SenseVoice-Small: 70ms na 10s audio (GPU A800), ponad 15× szybszy niż Whisper-Large-V3.
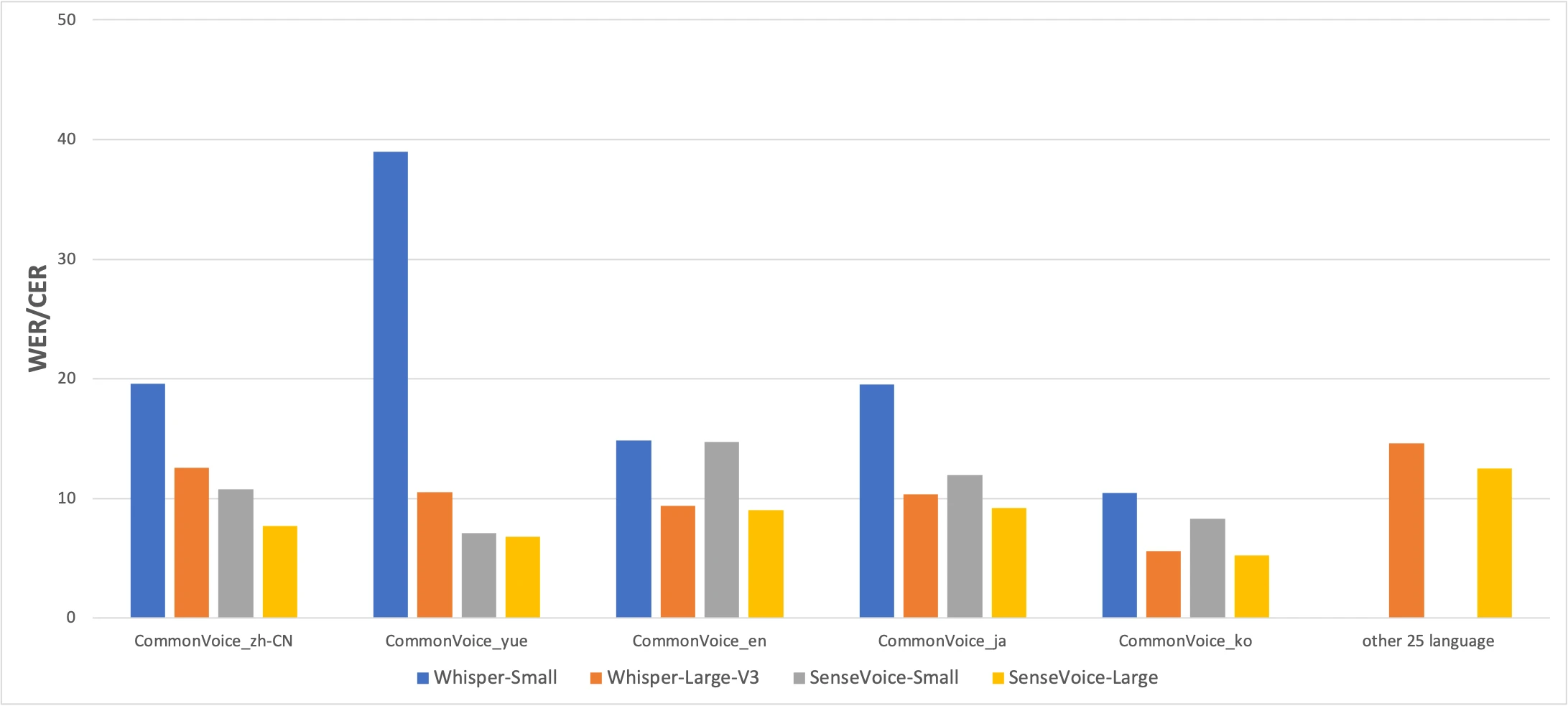
Benchmark CommonVoice: SenseVoice-Small (żółty) vs Whisper-Small (niebieski) vs Whisper-Large-V3 (pomarańczowy). Niższy jest lepszy. Źródło: artykuł FunAudioLLM
Liczby opowiadają uczciwą historię. SenseVoice pokonuje Whisper pod względem dokładności dla chińskiego i kantońskiego ze znaczącą przewagą, podczas gdy Whisper jest dokładniejszy dla japońskiego, koreańskiego i angielskiego. Ale SenseVoice jest ponad 15× szybszy niż Whisper-Large-V3. Dla większości zastosowań w praktyce różnica w szybkości liczy się bardziej niż kilka punktów procentowych dokładności.
Wynik dla kantońskiego zasługuje na osobne wyróżnienie. Whisper-Small osiąga 38,97% CER na kantońskim — praktycznie bezużyteczny. Nawet Whisper-Large-V3 osiąga tylko 10,41%. SenseVoice osiąga 7,09%. Przed SenseVoice nie było dobrego sposobu na transkrypcję kantońskiego lokalnie na Macu. Jeśli mówisz po kantońsku, ten model powstał dla ciebie.
Transkrypcja koreańskiego z SenseVoice: import wideo z napisami z znacznikami czasu
Test w warunkach rzeczywistych: 27-minutowy chiński podcast
Przetransskrybowaliśmy 27-minutowy odcinek Thirteen Invitations (十三邀), chińskiego podcastu z wywiadami, zarówno za pomocą SenseVoice, jak i Whisper Large V3 Turbo na tym samym M4 Pro. ElevenLabs Scribe (chmura) posłużył jako punkt odniesienia. Oba modele działające na urządzeniu popełniają mniej więcej tyle samo błędów, ale różnego rodzaju:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Czas | 13,83s | 2 min 4s |
| Błędy (próbka 5 min) | ~15–20 | ~12–15 |
| Najgorszy błąd | 时差→食堂 (strefa czasowa→stołówka) | 西昌→西藏 (miasto Xichang→Tybet, 4 000 km pomyłki) |
| Wzorzec błędów | Zamiany homofonów | Błędy geograficzne/faktyczne |
* Porównanie ręczne z ElevenLabs Scribe (referencja chmurowa, również niedoskonała). Oba modele na urządzeniu poprawnie napisały «根深蒂固», gdzie Scribe popełnił błąd.
Porównywalna dokładność. 9× szybciej. Dla transkrypcji chińskiego w codziennym użyciu SenseVoice dostarcza użyteczny transkrypt, zanim Whisper skończy się ładować.
Kiedy użyć którego modelu
Whisper Notes dla Mac jest teraz dostarczany z czterema modelami mowy. Każdy jest zoptymalizowany do innych scenariuszy:
| Potrzebujesz... | Użyj tego modelu | Dlaczego |
|---|---|---|
| Angielski lub języki europejskie, maksymalna szybkość | Parakeet V3 | 103× czas rzeczywisty, najniższy wskaźnik błędów. Domyślny. |
| Chiński, japoński, koreański lub kantoński | SenseVoice Small | 52–118× czas rzeczywisty. Jedyny model z obsługą kantońskiego. |
| Którykolwiek z 99+ języków (arabski, tajski, rosyjski itp.) | Whisper Large V3 Turbo | Najszersze wsparcie językowe. Wolniejszy, ale uniwersalny. |
| Mniejsze zużycie pamięci (starsze Maki) | Whisper Small | 487 MB pamięci. Dobry dla Maków z 8 GB i innymi otwartymi aplikacjami. |
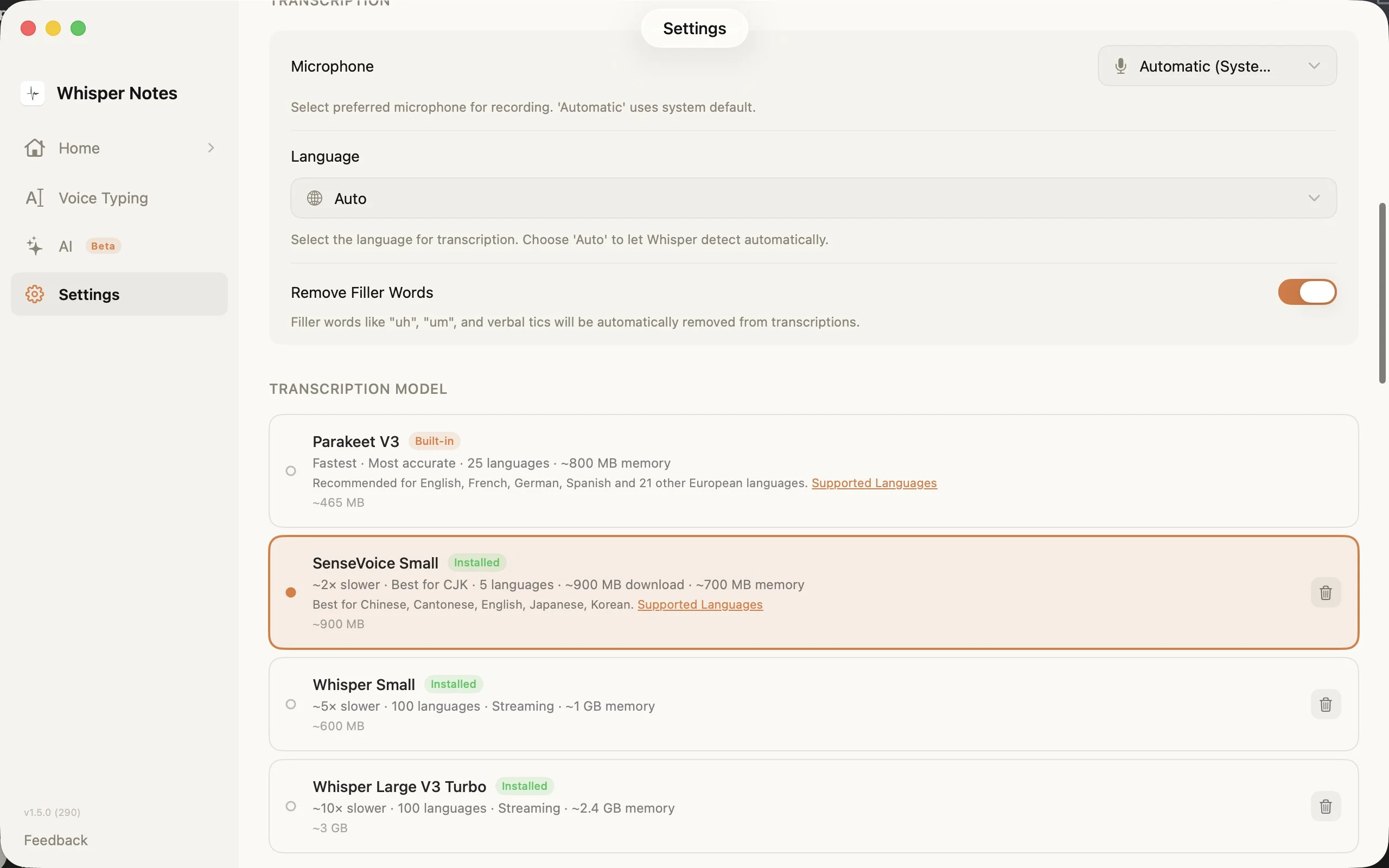
Ustawienia → Model transkrypcji: wybierz odpowiedni silnik dla swojego języka
Selektor modeli w Ustawieniach pokazuje wszystkie cztery opcje z rozmiarami pobierania, liczbą języków i wymaganiami pamięciowymi. SenseVoice pobiera się przy pierwszym użyciu (~827 MB) i zostaje na twoim urządzeniu.
Ograniczenia
SenseVoice nie jest modelem uniwersalnym. Oto czego nie potrafi:
• Tylko 5 języków. Jeśli potrzebujesz tajskiego, rosyjskiego, arabskiego, hindi lub któregokolwiek z ponad 90 innych języków obsługiwanych przez Whisper, zostań przy Whisper.
• Tylko Mac. SenseVoice działa przez Apple MLX, który wymaga macOS. Nie jest dostępny na iPhone. Użytkownicy iOS mają Parakeet (dla języków europejskich) i Whisper.
• Osobliwość przy cichym dźwięku. Podczas bardzo krótkich lub bardzo cichych segmentów SenseVoice może czasem przełączyć się na wyjście po chińsku, niezależnie od wybranego języka. Ręczne ustawienie języka (zamiast «Auto») zmniejsza to zjawisko.
• Brak streamingu. W przeciwieństwie do trybu strumieniowego Whisper, SenseVoice przetwarza pełne audio po nagraniu. Dla długich plików automatycznie segmentuje w punktach ciszy i pokazuje wyniki stopniowo.
To ograniczenia architekturalne, nie błędy. Model wytrenowany na 5 językach opanowuje te 5 języków wyjątkowo dobrze. Obsługa 99+ języków przez Whisper wiąże się z niższą szybkością i wyższymi wskaźnikami błędów dla każdego indywidualnego języka.
Wypróbuj
SenseVoice jest dostępny w Whisper Notes dla Mac od wersji 1.4.8. Pobierz go w Ustawienia → Model transkrypcji → SenseVoice Small (~827 MB). Wymaga Maca z Apple Silicon (M1 lub nowszy).
Jeśli używasz Parakeet V3 i dyktujesz głównie po angielsku, nie musisz zmieniać. SenseVoice jest na wypadek, gdy potrzebujesz chińskiego, japońskiego, koreańskiego lub kantońskiego — i chcesz to szybko.
Pełny dziennik zmian: whispernotes.app/changelog
Pytania lub opinie: mac@whispernotes.app