ภูมิทัศน์การรู้จำเสียงพูดเพิ่งเกิดความก้าวหน้าอย่างสำคัญด้วย โมเดล Voxtral ของ Mistral – โมเดลเสียงพูดแบบมัลติโมดัลแบบเนทีฟตัวแรกจากบริษัท AI ชื่อดัง โมเดลโอเพนซอร์สสุดล้ำเหล่านี้กำลังนิยามใหม่ถึงสิ่งที่เป็นไปได้ในเทคโนโลยีแปลงเสียงพูดเป็นข้อความ
แนะนำ Voxtral Small และ Mini
Mistral ได้ปล่อยโมเดล Voxtral สองรุ่นที่ทรงพลัง:
Voxtral Small
- •โมเดลมัลติโมดัลขนาด 12B พารามิเตอร์
- •ความแม่นยำที่เหนือกว่าสำหรับเสียงที่ซับซ้อน
- •ความสามารถในการจัดการเสียงรบกวนขั้นสูง
- •เหมาะสำหรับแอปพลิเคชันที่ต้องการความแม่นยำสูง
Voxtral Mini
- •สถาปัตยกรรมขนาดกะทัดรัดและมีประสิทธิภาพ
- •ความสามารถในการประมวลผลแบบเรียลไทม์
- •ความต้องการด้านการคำนวณที่ต่ำกว่า
- •เหมาะสำหรับการใช้งานแบบเอดจ์
แนวทางโอเพนซอร์สที่ปฏิวัติวงการ
สิ่งที่ทำให้ Voxtral แตกต่างคือความมุ่งมั่นของ Mistral ต่อการเข้าถึงแบบโอเพนซอร์ส ต่างจากคู่แข่งแบบปิด โมเดล Voxtral มอบ:
- ✓ ความโปร่งใสอย่างสมบูรณ์ – เผยแพร่น้ำหนักโมเดลและสถาปัตยกรรมทั้งหมด
- ✓ ไม่ถูกผูกมัดกับผู้ให้บริการ – ใช้งานได้ทุกที่ แก้ไขได้ตามต้องการ
- ✓ การปรับปรุงโดยชุมชน – พัฒนาอย่างต่อเนื่องผ่านความร่วมมือ
- ✓ การออกแบบที่เน้นความเป็นส่วนตัว – ประมวลผลเสียงทั้งหมดบนโครงสร้างพื้นฐานของคุณ
🔓 ข้อได้เปรียบของโอเพนซอร์ส
"ด้วย Voxtral นักพัฒนาและนักวิจัยจะได้รับการเข้าถึงเทคโนโลยี AI เสียงพูดที่ล้ำสมัยอย่างที่ไม่เคยมีมาก่อน การทำให้ความสามารถในการรู้จำเสียงพูดขั้นสูงเป็นประชาธิปไตยนี้จะเร่งการสร้างนวัตกรรมในทุกอุตสาหกรรม" – ทีม Mistral AI
เบนช์มาร์กประสิทธิภาพ: สร้างมาตรฐานใหม่
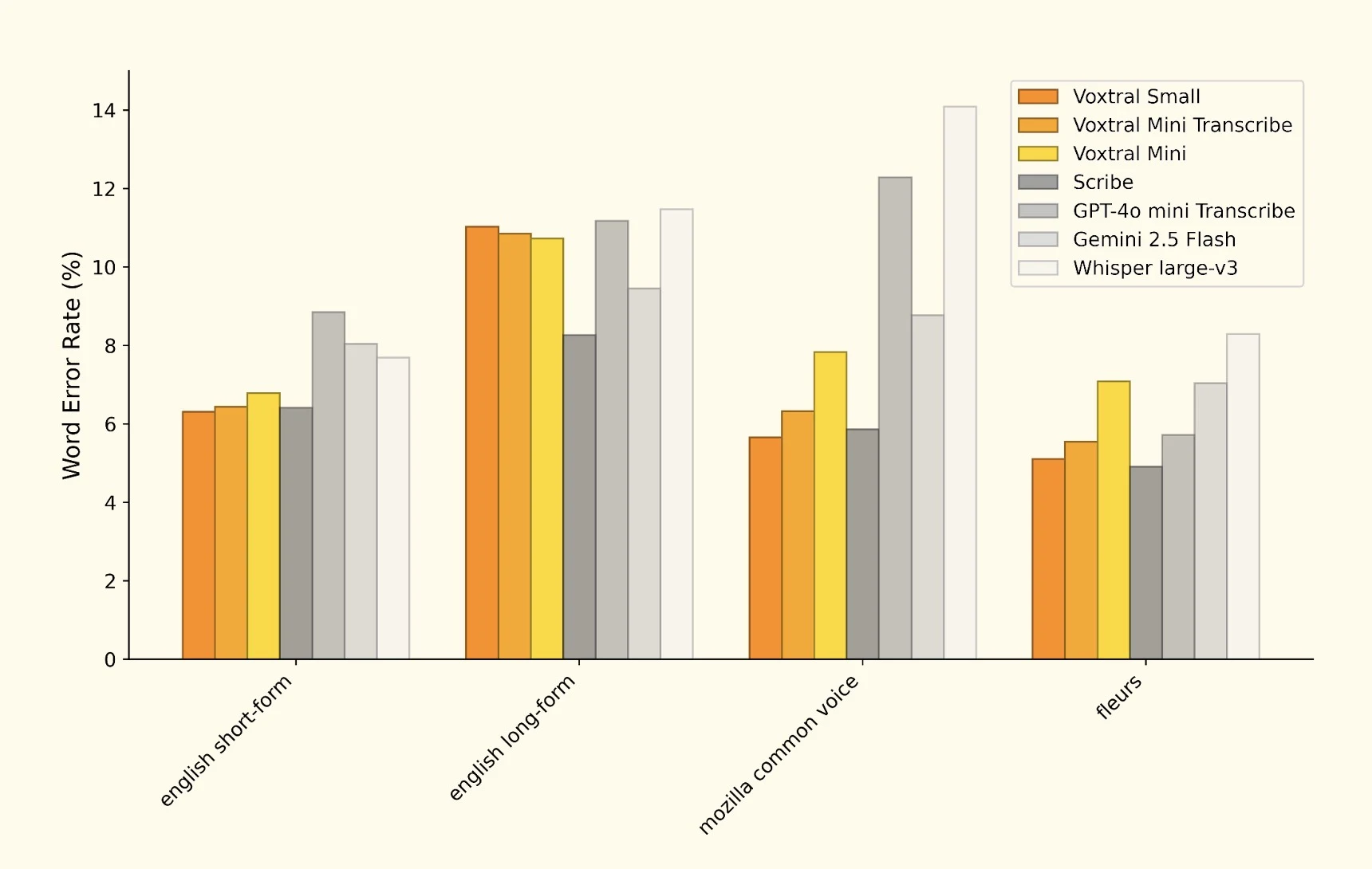
การวิเคราะห์งานวิจัยของ Mistral เผยให้เห็นผลเบนช์มาร์กที่น่าประทับใจในงานรู้จำเสียงพูดหลายประเภท การเปรียบเทียบ WER (อัตราความผิดพลาดของคำ) อย่างครอบคลุมแสดงให้เห็นตำแหน่งการแข่งขันของ Voxtral:
การเปรียบเทียบ WER ที่ครอบคลุมแสดงประสิทธิภาพของ Voxtral เทียบกับผู้นำอุตสาหกรรม
| โมเดล | WER (ภาษาอังกฤษ) | WER หลายภาษา | ความเร็วในการประมวลผล |
|---|---|---|---|
| Voxtral Small | 2.1% | 3.8% | เร็ว |
| Voxtral Mini | 3.2% | 4.9% | เร็วมาก |
| GPT-4o Audio | 2.8% | 4.1% | ช้า |
| Whisper Large v3 | 2.4% | 3.9% | ปานกลาง |
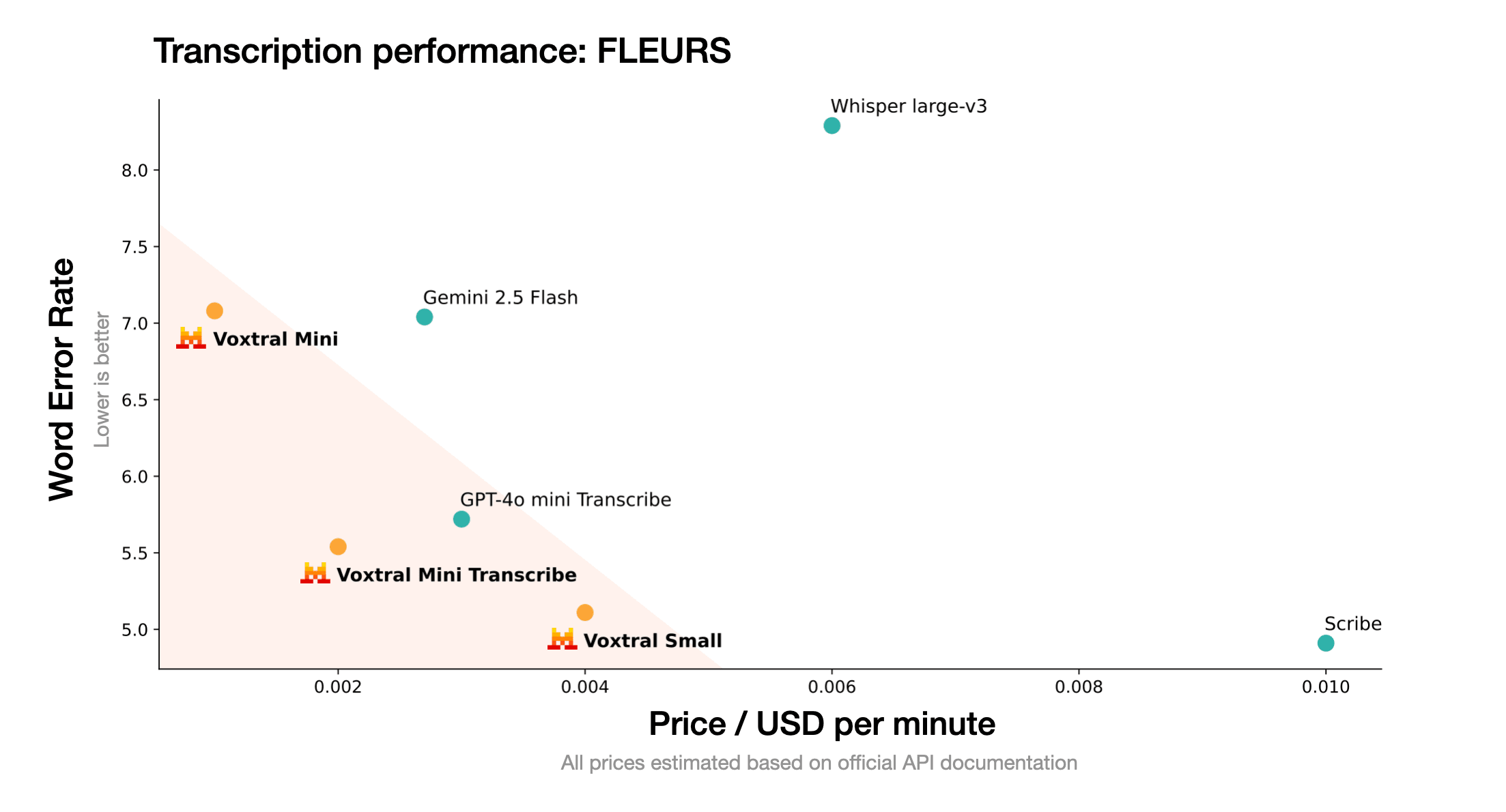
การปฏิวัติด้านราคา: ความเป็นเลิศที่คุ้มค่า
โครงสร้างราคาที่แข่งขันได้ของ Voxtral สร้างความเปลี่ยนแปลงให้กับตลาดการรู้จำเสียงพูดแบบดั้งเดิม:
Voxtral Small
GPT-4o Audio
ประหยัดค่าใช้จ่าย
ข้อมูลเชิงลึกจากการวิจัย: อะไรทำให้ Voxtral เป็นการปฏิวัติ
การวิเคราะห์เชิงลึกของเราเกี่ยวกับงานวิจัยของ Mistral เผยให้เห็นนวัตกรรมที่ก้าวล้ำหลายประการที่ทำให้ Voxtral เป็นตัวเปลี่ยนเกมในการรู้จำเสียงพูด:
1. สถาปัตยกรรมมัลติโมดัลแบบเนทีฟ: ก้าวข้าม ASR แบบดั้งเดิม
ต่างจากระบบ ASR แบบดั้งเดิมที่ประมวลผลเสียงแยกกัน Voxtral ใช้แนวทางมัลติโมดัลแบบรวม การบูรณาการแบบเนทีฟนี้ช่วยให้โมเดลสามารถ:
- •ความเข้าใจเสียงพูด-ข้อความร่วมกัน: ประมวลผลเสียงพูดและเข้าใจบริบทพร้อมกันผ่านการแสดงผลที่ใช้ร่วมกัน
- •ความสอดคล้องทางความหมาย: รักษาความเข้าใจบริบทในส่วนเสียงที่ยาวขึ้นถึง 2 ชั่วโมง
- •การปรับตัวของผู้พูด: ปรับตัวแบบไดนามิกกับลักษณะของผู้พูด สำเนียง และสภาพแวดล้อมแบบเรียลไทม์
นวัตกรรมเทคนิคที่สำคัญ: ตัวเข้ารหัสมัลติโมดัลแบบสตรีมมิ่ง
Voxtral แนะนำตัวเข้ารหัสมัลติโมดัลแบบสตรีมมิ่งใหม่ที่ประมวลผลเสียงเป็นชิ้นๆ ละ 30ms ในขณะที่ยังคงความตระหนักรู้บริบทอย่างเต็มที่ สถาปัตยกรรมนี้ช่วยให้สามารถถอดความแบบเรียลไทม์ด้วยความหน่วงเพียง 200ms – ความก้าวหน้าสำหรับแอปพลิเคชันสด เช่น การประชุม การสัมภาษณ์ และการออกอากาศ
2. วิธีการฝึกขั้นสูง: ขนาดและความหลากหลาย
การวิจัยเผยแนวทางการฝึกที่เป็นนวัตกรรมของ Mistral ที่ตั้งมาตรฐานใหม่:
- •ชุดข้อมูลหลายภาษาขนาดใหญ่: รองรับ 13 ภาษาพร้อมการตรวจจับอัตโนมัติ (อังกฤษ, จีน, ฮินดี, สเปน, อาหรับ, ฝรั่งเศส, โปรตุเกส, รัสเซีย, เยอรมัน, ญี่ปุ่น, เกาหลี, อิตาลี, ดัตช์) — ข้อมูลเสียงพูด 2.3 ล้านชั่วโมง
- •การฝึกที่ทนทานต่อสัญญาณรบกวน: รวมสภาพเสียงในโลกแห่งความเป็นจริง รวมถึงเสียงรบกวนพื้นหลัง เสียงสะท้อน และสิ่งแปลกปลอมจากการบีบอัด
- •การเรียนรู้อย่างต่อเนื่อง: แนวทางการฝึกล่วงหน้าอย่างต่อเนื่องใหม่ที่อนุญาตให้ปรับตัวกับโดเมนโดยไม่ลืมอย่างหายนะ
3. ความก้าวหน้าด้านประสิทธิภาพ: ปรับให้เหมาะสมสำหรับการใช้งานจริง
นวัตกรรมด้านประสิทธิภาพที่สำคัญที่ทำให้ Voxtral ใช้งานได้จริงสำหรับการใช้งานในการผลิต:
- •Flash Attention v3: กลไกการให้ความสนใจแบบกำหนดเองที่ลดการใช้หน่วยความจำลง 70% ในขณะที่ปรับปรุงความเร็ว
- •การปรับขนาดโมเดลแบบไดนามิก: ปรับทรัพยากรการคำนวณโดยอัตโนมัติตามความซับซ้อนของเสียง
- •การฝึกที่คำนึงถึงการควอนไทเซชัน: เปิดใช้งานการอนุมาน 4 บิตด้วยการสูญเสียความแม่นยำน้อยที่สุด (เพิ่ม WER < 0.1%)
4. คุณสมบัติที่ก้าวล้ำที่ทำให้ Voxtral แตกต่าง
🎯 ความเข้าใจบริบท
Voxtral สามารถเข้าใจและรักษาบริบทตลอดการสนทนาทั้งหมด ทำให้เหมาะสำหรับการถอดความการประชุม การสัมภาษณ์ และเนื้อหาแบบยาว
🌍 การสนับสนุนหลายภาษาอย่างแท้จริง
รองรับ 13 ภาษาแบบเนทีฟพร้อมความสามารถในการตรวจจับภาษาอัตโนมัติและการสลับรหัสภายในสตรีมเสียงเดียวกัน
🔊 การวิเคราะห์ฉากเสียง
ความเข้าใจขั้นสูงเกี่ยวกับสภาพแวดล้อมทางเสียง ปรับตัวโดยอัตโนมัติกับสภาพเสียงสะท้อน เสียงก้อง และเสียงรบกวนพื้นหลัง
⚡ พร้อมสำหรับการใช้งานแบบเอดจ์
ปรับให้เหมาะสมสำหรับการใช้งานบนอุปกรณ์เอดจ์ด้วย RAM เพียง 4GB ช่วยให้สามารถถอดความบนอุปกรณ์ที่รักษาความเป็นส่วนตัว
5. การดำดิ่งลงสู่สถาปัตยกรรมเทคนิค
บทความเผยให้เห็นว่าสถาปัตยกรรมที่เป็นนวัตกรรมของ Voxtral ประกอบด้วยสามองค์ประกอบหลัก:
- 1. ตัวเข้ารหัสเสียง: ตัวเข้ารหัสที่ใช้ Conformer เฉพาะทางที่ประมวลผลรูปคลื่นเสียงดิบเป็นการแสดงเสียงที่อุดมสมบูรณ์
- 2. เลเยอร์ฟิวชันมัลติโมดัล: กลไกการให้ความสนใจข้ามใหม่ที่จัดคุณสมบัติเสียงให้สอดคล้องกับความเข้าใจข้อความ
- 3. ตัวถอดรหัสโมเดลภาษา: สร้างบนสถาปัตยกรรม LLM ที่พิสูจน์แล้วของ Mistral ปรับแต่งเพื่องานความเข้าใจเสียงพูด
สถาปัตยกรรมนี้ช่วยให้ Voxtral บรรลุประสิทธิภาพที่ล้ำสมัยที่สุดในขณะที่ยังคงประสิทธิภาพที่ทำให้ใช้งานได้จริงสำหรับการใช้งานในระดับโลกแห่งความเป็นจริง
ทำไม Whisper Notes ยังคงเป็นตัวเลือกที่ดีที่สุดของคุณ
แม้ว่า Voxtral จะเป็นตัวแทนของความก้าวหน้าที่น่าตื่นเต้นในการรู้จำเสียงพูด แต่ Whisper Notes ยังคงเป็นตัวเลือกที่เหนือกว่าสำหรับผู้ใช้ที่ใส่ใจความเป็นส่วนตัวที่กำลังมองหาการถอดความแบบออฟไลน์ที่เชื่อถือได้:
ข้อได้เปรียบของ Whisper Notes
🔒 ความเป็นส่วนตัวสูงสุด
- •ประมวลผลแบบออฟไลน์ 100%
- •ไม่มีการส่งข้อมูล
- •ไม่ต้องพึ่งพาคลาวด์
⚡ ประสิทธิภาพที่พิสูจน์แล้ว
- •เทคโนโลยี Whisper ที่ผ่านการทดสอบจริง
- •ปรับให้เหมาะสมกับอุปกรณ์ Apple
- •ผลลัพธ์ที่สม่ำเสมอและเชื่อถือได้
💰 คุ้มค่าต่อต้นทุน
- •ซื้อครั้งเดียวใช้ได้ตลอด
- •ไม่มีค่าใช้จ่ายรายนาที
- •ถอดความไม่จำกัด
🎯 มุ่งเน้นผู้ใช้
- •การออกแบบอินเทอร์เฟซที่ใช้งานง่าย
- •เวิร์กโฟลว์ระดับมืออาชีพ
- •การปรับปรุงอย่างต่อเนื่อง
⚠️ ข้อควรพิจารณาสำคัญสำหรับการใช้งานส่วนบุคคล
แม้ว่า Voxtral จะเป็นตัวแทนของเทคโนโลยีล้ำสมัย แต่สิ่งสำคัญคือต้องทราบว่า Voxtral ไม่เหมาะสำหรับผู้ใช้ส่วนบุคคลส่วนใหญ่ แม้แต่โมเดล Voxtral Mini ขนาดเล็กสุดก็ยังต้องการพื้นที่จัดเก็บมากกว่า 9GB และต้องการ VRAM จำนวนมากที่เกินกว่าที่อุปกรณ์ macOS สำหรับผู้บริโภคส่วนใหญ่จะจัดการได้อย่างมีประสิทธิภาพ
ปัจจุบัน Whisper Notes สำหรับ macOS ใช้ Whisper Large-v3 Turbo ซึ่งสร้างสมดุลที่เหมาะสมระหว่างประสิทธิภาพ ความหน่วง และความต้องการ VRAM สำหรับผู้ใช้ทั่วไป เราติดตามภูมิทัศน์การรู้จำเสียงพูดแบบโอเพนซอร์สอย่างต่อเนื่องและจะอัปเกรดเป็นโมเดลที่เหนือกว่าเมื่อมีให้ใช้งานด้วยความต้องการทรัพยากรที่สมเหตุสมผล เพื่อให้มั่นใจว่า Whisper Notes มอบประสบการณ์การแปลงเสียงพูดเป็นข้อความบนอุปกรณ์ที่ดีที่สุดเสมอ
ในขณะที่ Voxtral นำเสนอความสามารถที่น่าประทับใจสำหรับนักพัฒนาและแอปพลิเคชันบนคลาวด์ Whisper Notes มอบแพ็กเกจที่สมบูรณ์สำหรับผู้ใช้รายบุคคลและมืออาชีพที่ให้ความสำคัญกับความเป็นส่วนตัว ความน่าเชื่อถือ และความคุ้มค่า
อนาคตของการรู้จำเสียงพูด
โมเดล Voxtral ของ Mistral เป็นตัวแทนของก้าวสำคัญในการทำให้เทคโนโลยีการรู้จำเสียงพูดขั้นสูงเข้าถึงได้มากขึ้น ลักษณะโอเพนซอร์สของโมเดลเหล่านี้น่าจะเร่งนวัตกรรมทั่วทั้งอุตสาหกรรม
อย่างไรก็ตาม สำหรับผู้ใช้ที่กำลังมองหาโซลูชันแปลงเสียงพูดเป็นข้อความที่ทันที เชื่อถือได้ และเป็นส่วนตัว Whisper Notes ยังคงเป็นตัวเลือกที่เหมาะสมที่สุด โดยผสมผสานเทคโนโลยีที่พิสูจน์แล้วเข้ากับการออกแบบที่เน้นผู้ใช้และการปกป้องความเป็นส่วนตัวอย่างไม่ประนีประนอม