TL;DR — เปรียบเทียบ 3 โมเดลบน Mac
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| อังกฤษ 5 นาที | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| จีน 27 นาที | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| ภาษาที่รองรับ | 25 (ยุโรป) | 5 (zh, en, ja, ko, yue) | 99+ |
| ดาวน์โหลด | 465 MB | 827 MB | 1.5 GB |
| หน่วยความจำ | ~800 MB | ~700 MB | ~1.6 GB |
| เหมาะสำหรับ | อังกฤษ & ยุโรป | จีน, ญี่ปุ่น, เกาหลี, กวางตุ้ง | ภาษาอื่นทั้งหมด (99+) |
* เบนช์มาร์กความเร็วบน Apple M4 Pro, 32 GB พอดแคสต์อังกฤษ 5 นาทีและพอดแคสต์จีน 27 นาที ตัวคูณเรียลไทม์ = ความยาวเสียง ÷ เวลาประมวลผล (สูงกว่า = เร็วกว่า) SenseVoice ใช้ได้เฉพาะ macOS iOS ใช้ Parakeet (ผ่าน ANE) และ Whisper
เริ่มตั้งแต่ เวอร์ชัน 1.4.8 Whisper Notes สำหรับ Mac ใช้ SenseVoice Small เป็นเอนจิ้นเฉพาะสำหรับการถอดเสียงภาษาจีน ญี่ปุ่น เกาหลี และกวางตุ้ง มาแทนที่ Qwen3-ASR โดยทำงานบน GPU ของ Apple ผ่าน MLX แทน CPU — ประมวลผลพอดแคสต์จีน 27 นาทีใน 13.83 วินาที แทนที่จะเป็น 3 นาที 44 วินาที
ทำไมเราจึงเปลี่ยนจาก Qwen3-ASR
Qwen3-ASR เป็นโมเดลที่ดี รองรับ 30 ภาษาและ 22 สำเนียงจีน ความแม่นยำภาษาจีนใกล้เคียงระดับสูงสุด แต่มีปัญหาที่แย่ลงเมื่อเสียงยาวขึ้น นั่นคือความเร็ว
Qwen3 ใช้สถาปัตยกรรมแบบ autoregressive — วิธีเดียวกับ Whisper ประมวลผลเสียงทีละเฟรม ไม่เคยข้ามไปข้างหน้า พอดแคสต์จีน 27 นาทีใช้เวลา 73 วินาที ใช้งานได้ แต่ไม่ใช่ประสบการณ์ผลลัพธ์ทันทีที่ Parakeet V3 มอบให้สำหรับภาษาอังกฤษ
ปัญหาที่ลึกกว่าคือโครงสร้างพื้นฐาน การรวม Qwen3 ของเราใช้ sherpa-onnx ซึ่งเป็นไลบรารี C ที่มี Swift wrapper 2,249 บรรทัด ส่งทุกอย่างผ่าน CPU GPU ของ Mac ไม่ได้ทำงานเลย
SenseVoice แก้ทั้งสองปัญหา สถาปัตยกรรม non-autoregressive เพื่อความเร็ว Apple MLX เพื่อการเร่งความเร็ว GPU ผลลัพธ์: เร็วขึ้น 16.2 เท่าบนฮาร์ดแวร์เดียวกัน โค้ดลดจาก 2,249 บรรทัดเหลือ 288
เบนช์มาร์ก
ทั้งสามโมเดลทำงานบน Apple M4 Pro เครื่องเดียวกัน ไฟล์เสียงเดียวกัน เงื่อนไขเดียวกัน ไม่มีคลาวด์ ไม่มีอินเทอร์เน็ต มีแค่ซิลิคอน
| โมเดล | อังกฤษ 5 นาที | จีน 27 นาที | ความเร็ว (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103–161× |
| SenseVoice Small | 5.8s | 13.83s | 52–118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13–14× |
| Qwen3-ASR (ลบออกแล้ว) | — | 73s | 4.7× |
SenseVoice เร็วประมาณครึ่งหนึ่งของ Parakeet V3 — แต่ก็ยังเร็วมากอย่างน่าทึ่ง พอดแคสต์ 27 นาทีเสร็จใน 14 วินาที กดถอดเสียง หายใจหนึ่งครั้ง ข้อความก็พร้อมแล้ว
เทียบกับ 2 นาที 4 วินาทีของ Whisper หรือ 73 วินาทีของ Qwen3 เดิม สถาปัตยกรรมสำคัญกว่าจำนวนพารามิเตอร์
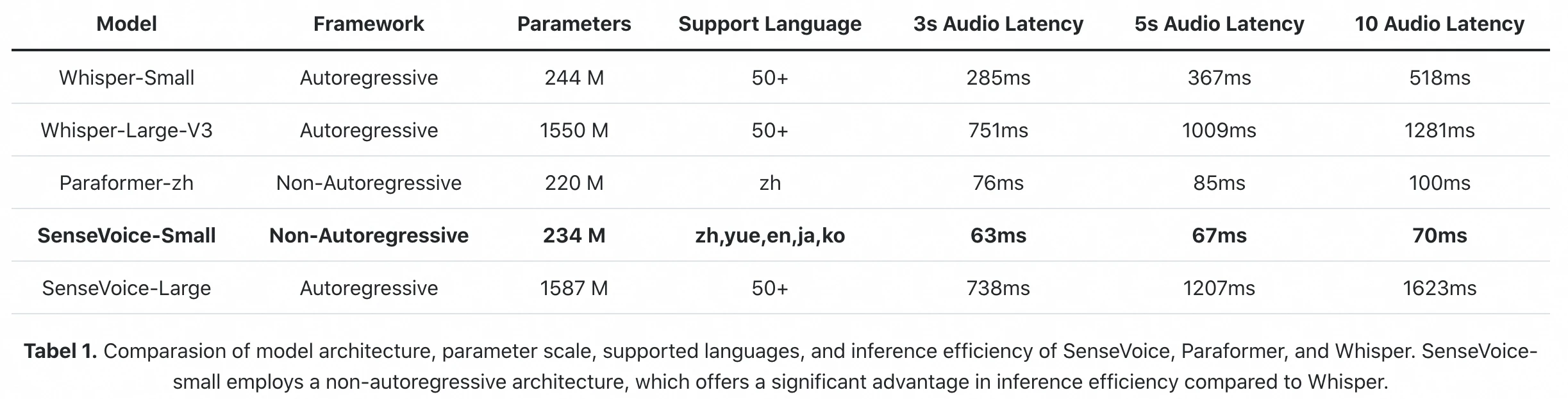
เบนช์มาร์กการอนุมานอย่างเป็นทางการจากบทความ FunAudioLLM: SenseVoice-Small ประมวลผลเสียง 10 วินาทีใน 70ms (A800 GPU) Whisper-Large-V3 ใช้เวลา 1,281ms ต่างกัน 18 เท่าในเวลาแฝงการอนุมาน
| โมเดล | เวลาโหลด | หน่วยความจำ | ขนาดดาวน์โหลด |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* เวลาโหลดและหน่วยความจำวัดบน Apple M4 Pro, 32 GB
SenseVoice โหลดภายในหนึ่งวินาทีและใช้หน่วยความจำน้อยกว่า Parakeet บน Mac 8 GB ทำงานได้สบายพร้อมกับแอปอื่น
ทำไม SenseVoice จึงเร็วกว่า: สถาปัตยกรรม + Runtime
ช่องว่างความเร็วระหว่าง Qwen3-ASR และ SenseVoice มาจากสองปัจจัยที่เป็นอิสระต่อกัน
ปัจจัยที่ 1: สถาปัตยกรรมโมเดล Qwen3-ASR เป็น autoregressive — สร้างโทเค็นทีละตัว แต่ละตัวขึ้นอยู่กับตัวก่อนหน้า SenseVoice ใช้ตัวเข้ารหัส non-autoregressive (NAR) ที่ประมวลผลเสียงทั้งหมดแบบขนาน ความแตกต่างทางสถาปัตยกรรมเพียงอย่างเดียวนี้ทำให้ SenseVoice เร็วกว่าโดยพื้นฐาน ไม่ว่าจะใช้ฮาร์ดแวร์อะไร
ปัจจัยที่ 2: Runtime การรวม Qwen3-ASR ใช้ sherpa-onnx ซึ่งทำงานบน CPU SenseVoice ทำงานผ่าน Apple MLX ส่งการคำนวณไปที่ GPU Qwen3 สามารถทำงานบน MLX ได้ไหม? ได้ — แต่ก็ยังจะช้ากว่า SenseVoice เพราะคอขวดของ autoregressive อยู่ที่สถาปัตยกรรม ไม่ใช่ runtime
| Qwen3-ASR (เก่า) | SenseVoice (ใหม่) | |
|---|---|---|
| สถาปัตยกรรม | Autoregressive (ทีละโทเค็น) | Non-autoregressive (ขนาน) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| จีน 27 นาที | 224 วินาที | 13.83 วินาที |
| เร็วขึ้นรวม | ค่าฐาน | เร็วขึ้น 16.2 เท่า |
| โค้ดเบส | เฟรมเวิร์ก C 168 MB + Swift 2,249 บรรทัด | Swift Actor 288 บรรทัด |
* พอดแคสต์จีน 27 นาทีเดียวกัน Apple M4 Pro การเร่งความเร็ว 16.2 เท่ารวมทั้งการปรับปรุงสถาปัตยกรรม (NAR vs AR) และ runtime (GPU vs CPU)
โค้ดก็ง่ายขึ้นด้วย การใช้งาน SenseVoice ใหม่เป็น Swift Actor เพียง 288 บรรทัดที่สื่อสารกับ MLX โดยตรง แทนที่เฟรมเวิร์ก C 168 MB โค้ดน้อยลง บั๊กน้อยลง แอปเล็กลง
ห้าภาษา ทำได้ดี
SenseVoice ไม่พยายามทำทุกอย่าง มันจัดการห้าภาษา:
| ภาษา | SenseVoice-Small | Whisper-Large-V3 | ผู้ชนะ |
|---|---|---|---|
| จีน (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| กวางตุ้ง (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| ญี่ปุ่น (ja) | 11.96% CER | 10.34% CER | Whisper (เล็กน้อย) |
| เกาหลี (ko) | 8.28% CER | 5.59% CER | Whisper |
| อังกฤษ (en) | 14.71% WER | 9.39% WER | Whisper (ใช้ Parakeet ดีกว่า) |
* เบนช์มาร์ก CommonVoice, CER = อัตราผิดพลาดตัวอักษร, WER = อัตราผิดพลาดคำ ยิ่งต่ำยิ่งดี แหล่งข้อมูล: บทความ FunAudioLLM (2024) เวลาแฝงการอนุมาน SenseVoice-Small: 70ms ต่อเสียง 10 วินาที (A800 GPU) เร็วกว่า Whisper-Large-V3 กว่า 15 เท่า
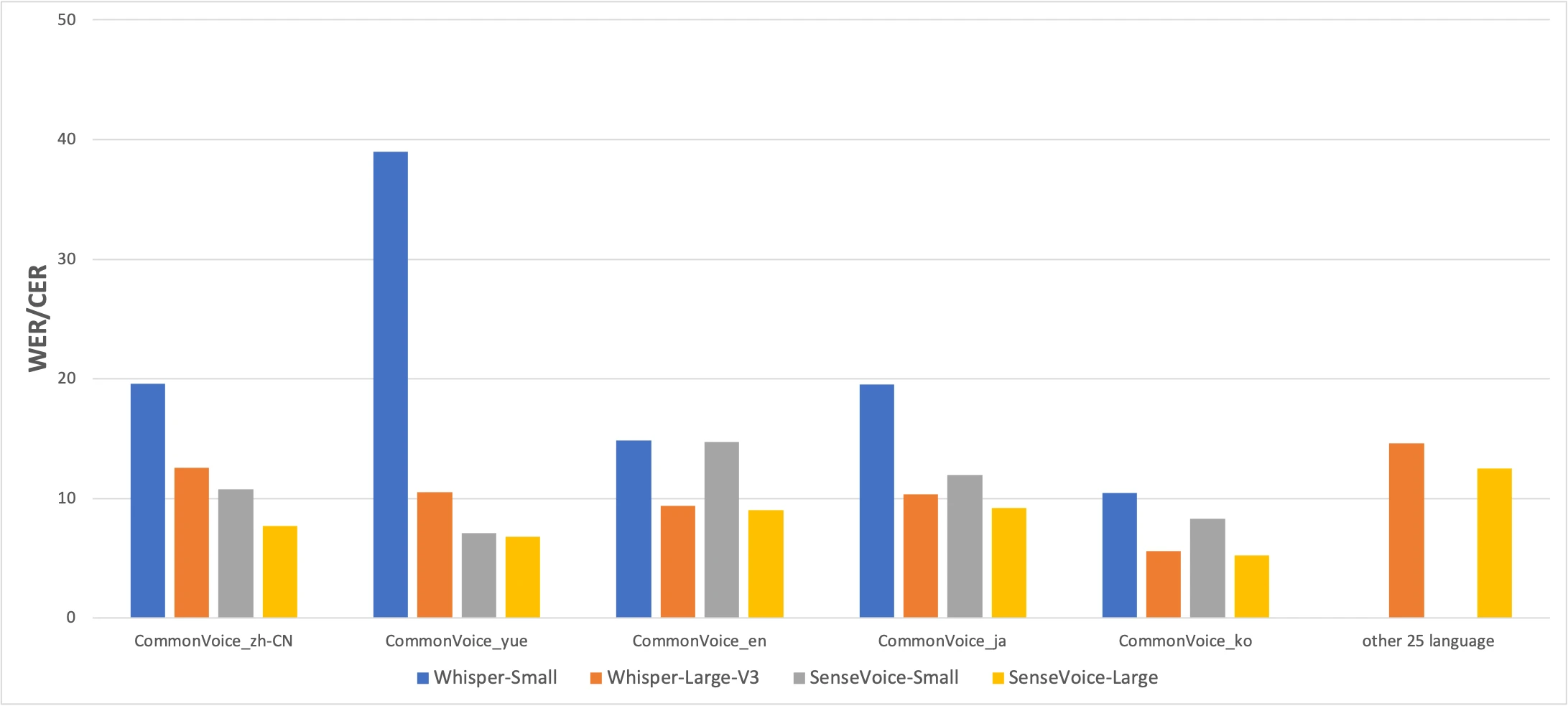
เบนช์มาร์ก CommonVoice: SenseVoice-Small (เหลือง) vs Whisper-Small (น้ำเงิน) vs Whisper-Large-V3 (ส้ม) ยิ่งต่ำยิ่งดี แหล่งข้อมูล: บทความ FunAudioLLM
ตัวเลขบอกเล่าเรื่องจริง SenseVoice ชนะ Whisper ในความแม่นยำภาษาจีนและกวางตุ้งอย่างมีนัยสำคัญ ขณะที่ Whisper แม่นยำกว่าสำหรับญี่ปุ่น เกาหลี และอังกฤษ แต่ SenseVoice เร็วกว่า Whisper-Large-V3 กว่า 15 เท่า ในการใช้งานจริง ความแตกต่างของความเร็วสำคัญกว่าความแม่นยำที่ต่างกันไม่กี่เปอร์เซ็นต์
ผลลัพธ์กวางตุ้งควรค่าแก่การเน้นย้ำเป็นพิเศษ Whisper-Small ได้ 38.97% CER สำหรับกวางตุ้ง — แทบใช้ไม่ได้ แม้แต่ Whisper-Large-V3 ก็ทำได้แค่ 10.41% SenseVoice ทำได้ 7.09% ก่อน SenseVoice ไม่มีวิธีที่ดีในการถอดเสียงกวางตุ้งบน Mac แบบออฟไลน์ หากคุณพูดกวางตุ้ง โมเดลนี้มีเพื่อคุณ
การถอดเสียงเกาหลีด้วย SenseVoice: นำเข้าวิดีโอพร้อมคำบรรยายที่มีเวลากำกับ
ทดสอบจริง: พอดแคสต์จีน 27 นาที
เราถอดเสียงตอนหนึ่ง 27 นาทีของ Thirteen Invitations (十三邀) พอดแคสต์สัมภาษณ์จีน ด้วยทั้ง SenseVoice และ Whisper Large V3 Turbo บน M4 Pro เครื่องเดียวกัน ใช้ ElevenLabs Scribe (คลาวด์) เป็นตัวอ้างอิง โมเดลทั้งสองบนเครื่องมีจำนวนข้อผิดพลาดใกล้เคียงกัน แต่ประเภทต่างกัน:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| เวลา | 13.83s | 2 min 4s |
| ข้อผิดพลาด (ตัวอย่าง 5 นาที) | ~15–20 | ~12–15 |
| ข้อผิดพลาดที่เลวร้ายที่สุด | 时差→食堂 (เขตเวลา→โรงอาหาร) | 西昌→西藏 (เมือง Xīchāng→ทิเบต, คลาดเคลื่อน 4,000 กม.) |
| รูปแบบข้อผิดพลาด | สลับคำพ้องเสียง | ข้อผิดพลาดทางภูมิศาสตร์/ข้อเท็จจริง |
* เปรียบเทียบด้วยตนเองกับ ElevenLabs Scribe (อ้างอิงคลาวด์ ซึ่งก็ไม่สมบูรณ์แบบ) โมเดลทั้งสองบนเครื่องเขียน "根深蒂固" ถูกต้อง ขณะที่ Scribe ผิด
ความแม่นยำใกล้เคียงกัน เร็วกว่า 9 เท่า สำหรับการถอดเสียงจีนในสถานการณ์จริง SenseVoice ให้บทถอดเสียงที่ใช้ได้ก่อนที่ Whisper จะโหลดเสร็จ
เมื่อไหร่ควรใช้โมเดลไหน
Whisper Notes สำหรับ Mac มาพร้อมสี่โมเดลเสียง แต่ละโมเดลเหมาะสำหรับสถานการณ์ที่แตกต่างกัน:
| คุณต้องการ... | ใช้โมเดลนี้ | เหตุผล |
|---|---|---|
| อังกฤษหรือยุโรป ความเร็วสูงสุด | Parakeet V3 | 103× เรียลไทม์, อัตราข้อผิดพลาดต่ำสุด ค่าเริ่มต้น |
| จีน ญี่ปุ่น เกาหลี หรือกวางตุ้ง | SenseVoice Small | 52–118× เรียลไทม์ โมเดลเดียวที่รองรับกวางตุ้ง |
| ภาษาใดก็ได้ใน 99+ (อาหรับ ไทย รัสเซีย ฯลฯ) | Whisper Large V3 Turbo | รองรับภาษามากที่สุด ช้ากว่าแต่ใช้ได้ทุกภาษา |
| ใช้หน่วยความจำน้อย (Mac รุ่นเก่า) | Whisper Small | 487 MB หน่วยความจำ เหมาะกับ Mac 8 GB |
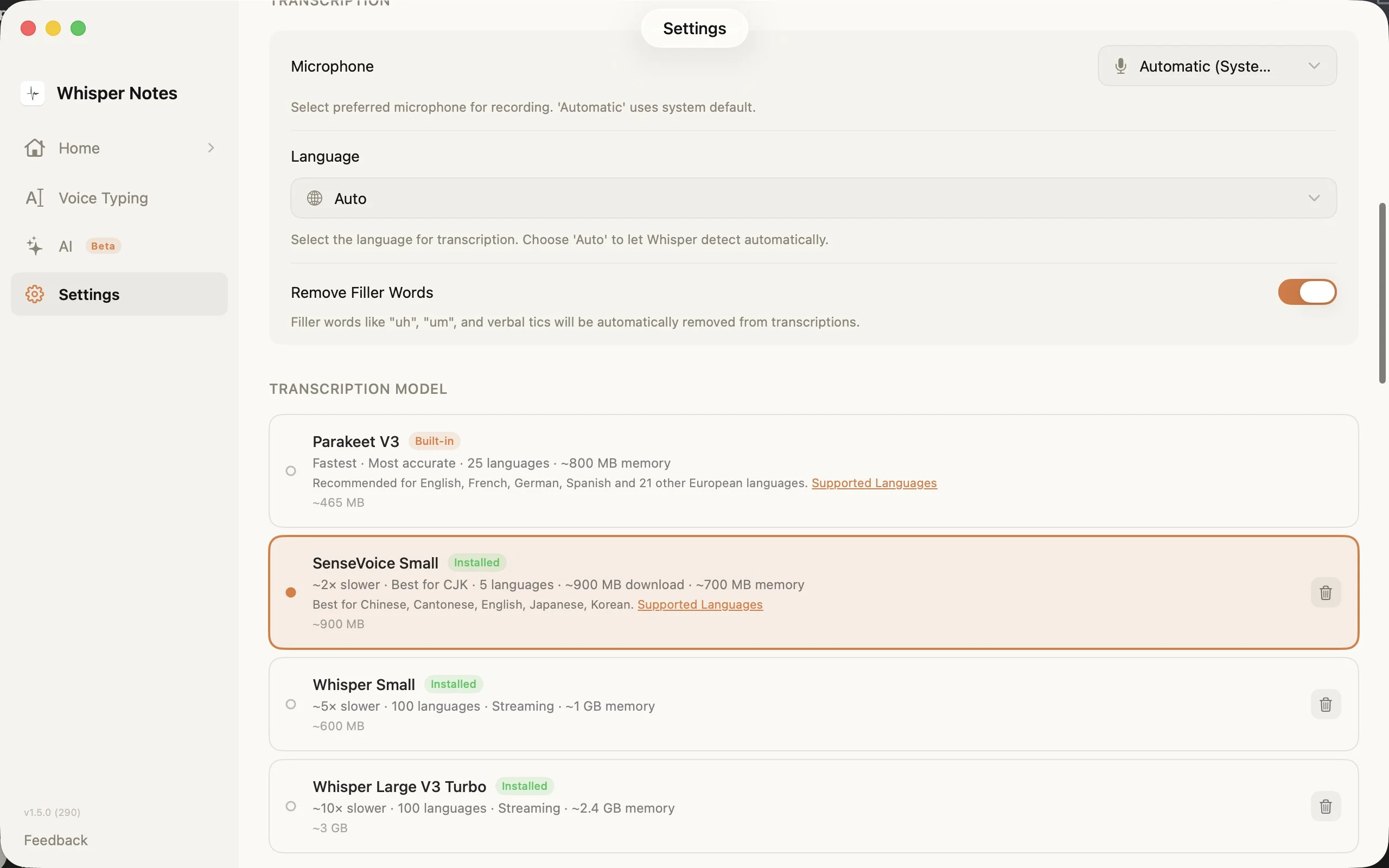
การตั้งค่า → โมเดลถอดเสียง: เลือกเอนจิ้นที่เหมาะกับภาษาของคุณ
ตัวเลือกโมเดลในการตั้งค่าแสดงทั้งสี่ตัวเลือกพร้อมขนาดดาวน์โหลด จำนวนภาษา และข้อกำหนดหน่วยความจำ SenseVoice ดาวน์โหลดเมื่อใช้ครั้งแรก (~827 MB) และเก็บไว้บนเครื่อง
ข้อจำกัด
SenseVoice ไม่ใช่โมเดลสากล สิ่งที่ทำไม่ได้มีดังนี้:
• รองรับแค่ 5 ภาษา หากคุณต้องการภาษาไทย รัสเซีย อาหรับ ฮินดี หรือภาษาอื่นอีก 90+ ภาษาที่ Whisper รองรับ ให้ใช้ Whisper
• Mac เท่านั้น SenseVoice ทำงานผ่าน Apple MLX ซึ่งต้องใช้ macOS ไม่มีบน iPhone ผู้ใช้ iOS มี Parakeet (สำหรับภาษายุโรป) และ Whisper
• ปัญหาเสียงเบา ในช่วงที่สั้นมากหรือเบามาก SenseVoice อาจออกเป็นภาษาจีนโดยไม่สนใจภาษาที่เลือก การตั้งภาษาด้วยตนเอง (แทน "อัตโนมัติ") ช่วยลดปัญหานี้
• ไม่รองรับสตรีมมิ่ง ต่างจากโหมดสตรีมมิ่งของ Whisper SenseVoice ประมวลผลเสียงทั้งหมดหลังจากบันทึกเสร็จ สำหรับไฟล์ยาว มันจะตัดอัตโนมัติที่จุดเงียบและแสดงผลทีละส่วน
เหล่านี้คือข้อจำกัดทางสถาปัตยกรรม ไม่ใช่บั๊ก โมเดลที่ฝึกด้วย 5 ภาษาทำ 5 ภาษานั้นได้ดีมาก การรองรับ 99+ ภาษาของ Whisper มาพร้อมกับความเร็วที่ช้าลงและอัตราข้อผิดพลาดที่สูงขึ้นในแต่ละภาษา
ลองใช้งาน
SenseVoice มีใน Whisper Notes สำหรับ Mac v1.4.8 ขึ้นไป ดาวน์โหลดจาก การตั้งค่า → โมเดลถอดเสียง → SenseVoice Small (~827 MB) ต้องใช้ Mac Apple Silicon (M1 ขึ้นไป)
หากคุณใช้ Parakeet V3 และพิมพ์ด้วยเสียงเป็นภาษาอังกฤษเป็นหลัก ไม่จำเป็นต้องเปลี่ยน SenseVoice สำหรับเมื่อคุณต้องการจีน ญี่ปุ่น เกาหลี หรือกวางตุ้ง — และต้องการความเร็ว
บันทึกการเปลี่ยนแปลง: whispernotes.app/changelog
คำถามหรือข้อเสนอแนะ: mac@whispernotes.app