El panorama del reconeixement de veu acaba de presenciar un avenç significatiu amb els models Voxtral de Mistral – els primers models de veu multimodals natius de la reconeguda empresa d'IA. Aquests revolucionaris models de codi obert estan redefinint el que és possible en la tecnologia de conversió de veu a text.
Presentació de Voxtral Small i Mini
Mistral ha llançat dues potents variants de la seva família de models Voxtral:
Voxtral Small
- •Model multimodal de 12B paràmetres
- •Precisió superior per a àudio complex
- •Capacitats avançades de gestió del soroll
- •Òptim per a aplicacions d'alta precisió
Voxtral Mini
- •Arquitectura compacta i eficient
- •Capacitats de processament en temps real
- •Requisits computacionals més baixos
- •Perfecte per al desplegament a la vora
Enfocament revolucionari de codi obert
El que distingeix Voxtral és el compromís de Mistral amb l'accessibilitat de codi obert. A diferència dels competidors de codi tancat, els models Voxtral ofereixen:
- ✓ Transparència completa – Pesos complets del model i arquitectura disponibles
- ✓ Sense bloqueig del proveïdor – Desplegueu en qualsevol lloc, modifiqueu segons les necessitats
- ✓ Millores impulsades per la comunitat – Millora contínua mitjançant col·laboració
- ✓ Disseny centrat en la privacitat – Processeu àudio completament en la vostra infraestructura
🔓 L'avantatge del codi obert
"Amb Voxtral, els desenvolupadors i investigadors obtenen un accés sense precedents a la tecnologia d'IA de veu d'avantguarda. Aquesta democratització de les capacitats avançades de reconeixement de veu accelerarà la innovació en totes les indústries." – Equip Mistral AI
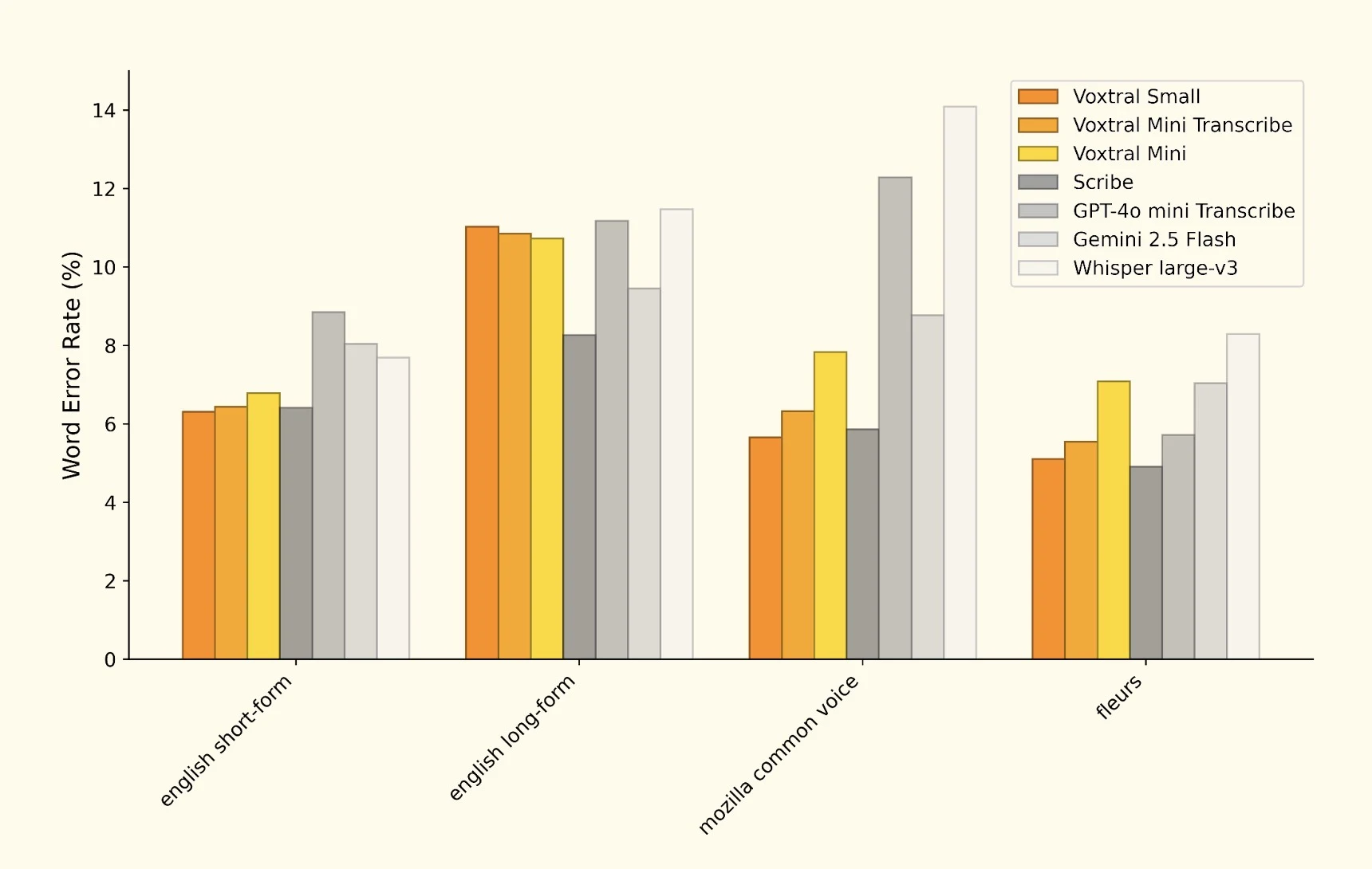
Punts de referència del rendiment: Establint nous estàndards
La nostra anàlisi de la investigació de Mistral revela resultats impressionants de punts de referència en múltiples tasques de reconeixement de veu. La comparació completa del WER (Taxa d'error de paraules) demostra el posicionament competitiu de Voxtral:
Comparació completa del WER que mostra el rendiment de Voxtral davant dels líders de la indústria
| Model | WER (Anglès) | WER Multilingüe | Velocitat de processament |
|---|---|---|---|
| Voxtral Small | 2,1% | 3,8% | Ràpid |
| Voxtral Mini | 3,2% | 4,9% | Molt ràpid |
| GPT-4o Audio | 2,8% | 4,1% | Lent |
| Whisper Large v3 | 2,4% | 3,9% | Mitjà |
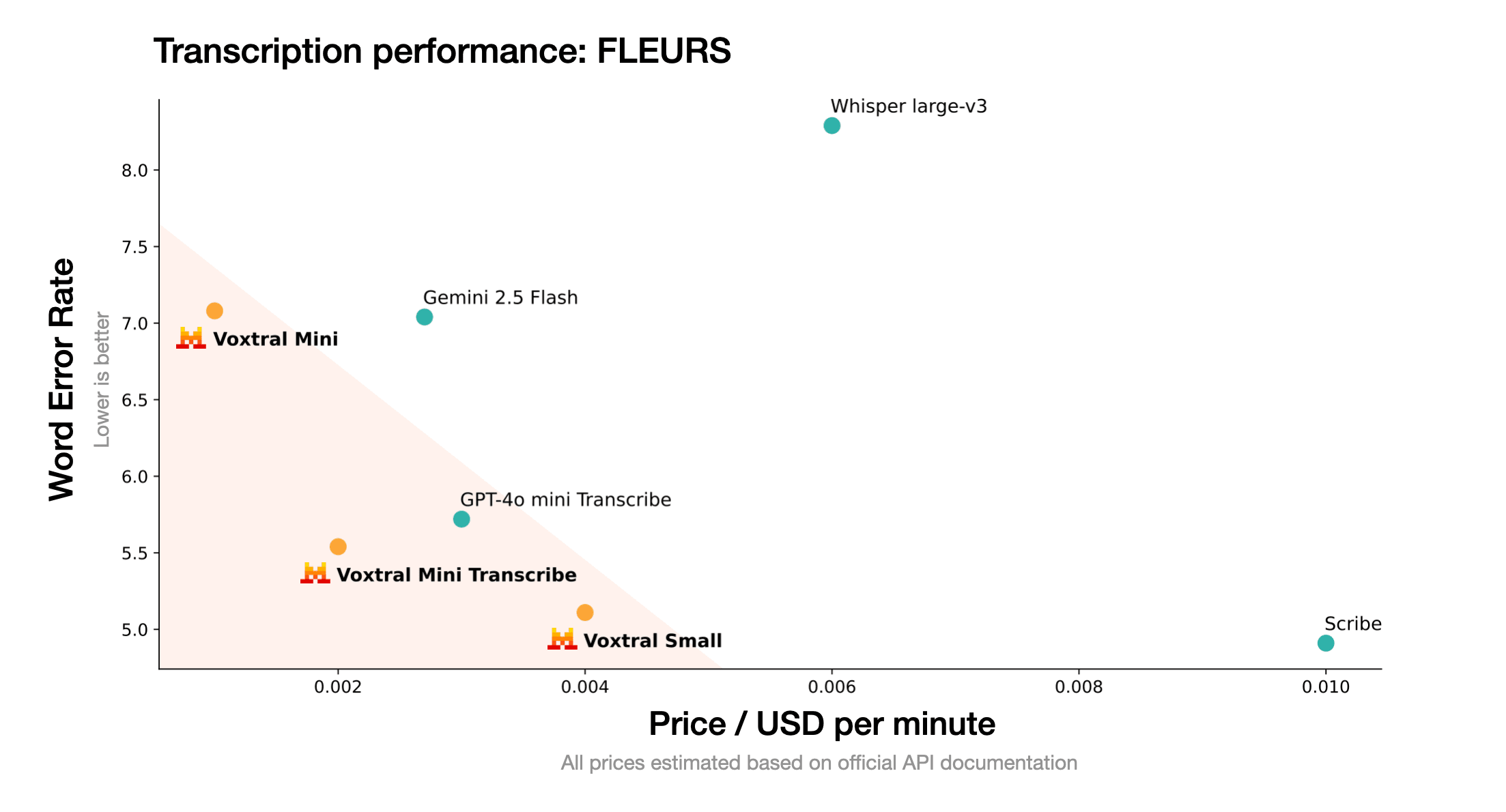
Revolució de preus: Excel·lència rendible
L'estructura de preus competitiva de Voxtral pertorba el mercat tradicional del reconeixement de veu:
Voxtral Small
GPT-4o Audio
Estalvi de costos
Coneixements profunds de la investigació: Què fa revolucionari Voxtral
La nostra anàlisi en profunditat de l'article de recerca de Mistral revela diverses innovacions revolucionàries que posicionen Voxtral com un canvi de joc en el reconeixement de veu:
1. Arquitectura multimodal nativa: Més enllà de l'ASR tradicional
A diferència dels sistemes ASR tradicionals que processen l'àudio per separat, Voxtral empra un enfocament multimodal unificat. Aquesta integració nativa permet al model:
- •Comprensió conjunta de veu-text: Processar la veu i entendre el context simultàniament mitjançant representacions compartides
- •Coherència semàntica: Mantenir la comprensió contextual a través de segments d'àudio més llargs fins a 2 hores
- •Adaptació del parlant: Adaptar-se dinàmicament a les característiques del parlant, accents i condicions ambientals en temps real
Innovació tècnica clau: Codificador multimodal de transmissió
Voxtral introdueix un nou codificador multimodal de transmissió que processa àudio en blocs de 30ms mentre manté la consciència completa del context. Aquesta arquitectura permet la transcripció en temps real amb només 200ms de latència – un avenç per a aplicacions en directe com reunions, entrevistes i emissions.
2. Metodologia d'entrenament avançada: Escala i diversitat
La investigació revela l'enfocament innovador d'entrenament de Mistral que estableix nous estàndards:
- •Conjunt de dades multilingüe massiu: 2,3 milions d'hores de dades de veu que abracen 13 idiomes
- •Entrenament robust al soroll: Incorpora condicions d'àudio del món real incloent soroll de fons, reverberació i artefactes de compressió
- •Aprenentatge continu: Nou enfocament de pre-entrenament continu que permet l'adaptació del domini sense oblit catastròfic
3. Avenços en eficiència: Optimitzat per al desplegament real
Innovacions clau en eficiència que fan pràctic Voxtral per a ús en producció:
- •Flash Attention v3: Mecanisme d'atenció personalitzat que redueix l'ús de memòria en un 70% mentre millora la velocitat
- •Escalat dinàmic del model: Ajusta automàticament els recursos computacionals basant-se en la complexitat de l'àudio
- •Entrenament conscient de la quantització: Permet inferència de 4 bits amb pèrdua mínima de precisió (< 0,1% d'augment del WER)
4. Funcions revolucionàries que distingeixen Voxtral
🎯 Comprensió contextual
Voxtral pot entendre i mantenir el context a través de converses senceres, cosa que el fa ideal per a la transcripció de reunions, entrevistes i contingut de format llarg.
🌍 Suport multilingüe real
Admet 13 idiomes amb detecció automàtica (anglès, xinès, hindi, espanyol, àrab, francès, portuguès, rus, alemany, japonès, coreà, italià, neerlandès) i capacitats de canvi de codi dins del mateix flux d'àudio.
🔊 Anàlisi d'escena acústica
Comprensió avançada dels entorns acústics, adaptant-se automàticament a les condicions de reverberació, eco i soroll de fons.
⚡ Preparat per al desplegament a la vora
Optimitzat per al desplegament en dispositius de vora amb tan sols 4GB de RAM, permetent la transcripció en el dispositiu que preserva la privacitat.
5. Immersió profunda en l'arquitectura tècnica
L'article revela que l'arquitectura innovadora de Voxtral consta de tres components principals:
- 1. Codificador d'àudio: Un codificador especialitzat basat en Conformer que processa formes d'ona d'àudio en brut en representacions acústiques riques
- 2. Capa de fusió multimodal: Nou mecanisme d'atenció creuada que alinea les característiques d'àudio amb la comprensió textual
- 3. Descodificador del model de llenguatge: Construït sobre l'arquitectura LLM provada de Mistral, afinat per a tasques de comprensió de veu
Aquesta arquitectura permet a Voxtral aconseguir un rendiment d'última generació mentre manté l'eficiència que el fa pràctic per al desplegament a escala real.
Per què Whisper Notes continua sent la vostra millor opció
Tot i que Voxtral representa un progrés emocionant en el reconeixement de veu, Whisper Notes continua sent l'opció superior per als usuaris conscients de la privacitat que busquen transcripció fora de línia fiable:
Avantatges de Whisper Notes
🔒 Privacitat absoluta
- •Processament 100% fora de línia
- •Zero transmissió de dades
- •Sense dependències del núvol
⚡ Rendiment provat
- •Tecnologia Whisper provada en batalla
- •Optimitzat per a dispositius Apple
- •Resultats consistents i fiables
💰 Rendible
- •Compra única
- •Sense càrrecs per minut
- •Transcripció il·limitada
🎯 Centrat en l'usuari
- •Disseny d'interfície intuïtiu
- •Fluxos de treball professionals
- •Millores contínues
⚠️ Consideració important per a l'ús personal
Tot i que Voxtral representa tecnologia d'avantguarda, és important notar que Voxtral no és pràctic per a la majoria d'usuaris personals. Fins i tot el model Voxtral Mini mínim requereix més de 9GB d'emmagatzematge i demanda VRAM substancial que excedeix el que la majoria de dispositius macOS de consum poden gestionar eficientment.
Actualment, Whisper Notes per a macOS utilitza Whisper Large-v3 Turbo, que aconsegueix l'equilibri òptim entre rendiment, latència i requisits de VRAM per als usuaris quotidians. Monitoritzem contínuament el panorama del reconeixement de veu de codi obert i actualitzarem a models superiors quan estiguin disponibles amb requisits de recursos raonables, assegurant que Whisper Notes sempre ofereixi la millor experiència de veu a text en el dispositiu.
Mentre que Voxtral ofereix capacitats impressionants per a desenvolupadors i aplicacions basades en núvol, Whisper Notes ofereix el paquet complet per a usuaris individuals i professionals que valoren la privacitat, la fiabilitat i la rendibilitat.
El futur del reconeixement de veu
Els models Voxtral de Mistral representen un pas significatiu endavant en fer la tecnologia avançada de reconeixement de veu més accessible. La naturalesa de codi obert d'aquests models probablement accelerarà la innovació a tota la indústria.
No obstant això, per als usuaris que busquen solucions immediates, fiables i privades de veu a text, Whisper Notes continua sent l'opció òptima, combinant tecnologia provada amb disseny centrat en l'usuari i protecció de la privacitat sense compromisos.