La veu a text fora de línia ja és pràctica en el maquinari Apple de cada dia: l'àudio es queda al teu dispositiu, les gravacions llargues acaben en segons o minuts i no hi ha cap factura per minut.

Un model de transcripció local funcionant en Apple Silicon
La resposta ràpida: la millor veu a text fora de línia per plataforma
Si només vols la resposta: al Mac i l'iPhone, fes servir Whisper Notes — tres motors d'IA locals i una compra única de $6.99 per plataforma; el Mac inclou una prova de 10.000 paraules. A Windows, fes servir Buzz o faster-whisper (gratuïts, de codi obert). A Android, les opcions encara són escasses — mira la secció de plataformes més avall. Totes les eines d'aquesta taula funcionen 100% fora de línia:
| Eina | Plataformes | Preu | Configuració | Models |
|---|---|---|---|---|
| Whisper Notes | Mac (sèrie M), iPhone | $6.99 per plataforma; prova de 10.000 paraules al Mac | Cap — aplicació nativa | Parakeet V3, SenseVoice, Whisper Turbo |
| MacWhisper | Només Mac | Nivell gratuït; Pro €64 un sol pagament | Cap — aplicació nativa | Família Whisper |
| Buzz | Windows, Mac, Linux | Gratuït (codi obert) | Instal·lador; interfície bàsica | Família Whisper |
| faster-whisper / whisper.cpp | Windows, Mac, Linux | Gratuït (codi obert) | Línia d'ordres | Família Whisper |
| Dictat d'Apple | Integrat a l'iPhone/Mac | Gratuït | Cap | Model d'Apple al dispositiu; només dictats curts |
La resta d'aquesta guia explica per què la transcripció local guanya en latència, cost i privadesa — amb xifres de benchmark reals — i mostra com transcriure àudio a text fora de línia, pas a pas.
El problema de la latència
El circuit de la transcripció al núvol: parles, l'àudio puja a un servidor, l'API el processa i els resultats tornen. Fins i tot els serveis «en temps real» afegeixen 2-3 segons d'anada i tornada per la xarxa per a una gravació de 10 segons.
Amb la transcripció local, tota aquesta latència desapareix. L'àudio no surt mai del teu dispositiu, el processament passa al xip i els resultats apareixen a l'instant. Sense pujades, sense esperes, sense l'indicador giratori de «processant».
Els iPhone recents i els Macs amb Apple Silicon inclouen el Neural Engine, maquinari dedicat a l'aprenentatge automàtic al dispositiu. La transcripció local fa servir maquinari que ja tens en lloc d'esperar una pujada i una resposta remota.
El 2019, la transcripció al núvol tenia sentit. El teu telèfon no podia executar una xarxa neuronal de mil milions de paràmetres. Aquesta restricció ha desaparegut. L'iPhone 15 Pro executa models Whisper més ràpid del que la majoria de serveis al núvol triguen a retornar resultats. El MacBook M3 processa 60 minuts d'àudio en 5 minuts — localment, fora de línia, sense cap pujada.
La transcripció al núvol encara té sentit per a la col·laboració en directe i els fluxos de treball centralitzats. Per a una gravació privada que només necessites tu, la pujada sovint és innecessària.
El xip ja l'has pagat
Aquí hi ha una cosa que t'hauria de molestar.
Apple cobra una prima pel xip M3. L'has pagat tu. Aquell Neural Engine? És teu. Els 18.000 milions de transistors optimitzats per a l'aprenentatge automàtic? Teus.
I després pagues $10 al mes a Otter.ai perquè transcrigui l'àudio als seus servidors.
Estàs llogant el maquinari d'algú altre quan ja tens un maquinari més ràpid. És com comprar-se un cotxe esportiu i pagar taxis.
L'economia de la transcripció al núvol tenia sentit quan la inferència local era impossible. Ara només és un impost a la inèrcia. En tres anys, una subscripció de $10 al mes costa $360. Whisper Notes costa $6.99 un sol cop. La mateixa precisió. Un processament més ràpid. El teu xip fa la feina per a la qual va ser dissenyat.
| Servei | Any 1 | Any 3 | Any 5 |
|---|---|---|---|
| Subscripció al núvol ($10/mes) | $120 | $360 | $600 |
| Whisper Notes (un sol pagament) | $6.99 | $6.99 | $6.99 |
No cobrem subscripcions perquè no operem servidors. El teu àudio no toca mai la nostra infraestructura. No hi ha res a facturar cada mes.
Les filtracions de dades són arquitectòniques
Parlem clar sobre la privadesa.
Quan fas servir un servei de transcripció al núvol, el teu àudio viu als servidors d'algú altre. Aquests servidors tenen empleats amb accés. Aquests servidors es connecten a xarxes. Aquestes xarxes reben atacs. Les filtracions de dades no són accidents — són inevitabilitats arquitectòniques d'emmagatzemar dades sensibles en infraestructura de tercers.
Les dades de veu comporten un risc únic. A diferència d'una contrasenya, la veu no es pot restablir. Els teus patrons vocals són identificadors biomètrics permanents. Un cop filtrats, queden compromesos per sempre. Els atacants poden fer servir empremtes de veu per evadir autenticacions, cometre frau d'identitat o generar deepfakes.
L'única manera d'eliminar aquest risc és eliminar la pujada. L'àudio que no surt mai del teu dispositiu no pot formar part d'una filtració de servidors. Això no és una funció — és física.
Pensa en qui grava àudio sensible:
- Advocats que graven consultes amb clients
- Terapeutes que documenten sessions amb pacients
- Periodistes que protegeixen les seves fonts
- Directius que capturen discussions estratègiques
- Metges que anoten historials de pacients
Per a aquests professionals, l'emmagatzematge al núvol no és només incòmode — és una responsabilitat legal. La transcripció local no és una preferència. És un requisit.
La precisió i les seves contrapartides
Cal ser directes sobre què fa bé la transcripció local i on es queda curta.
El que el Whisper local fa millor: la transcripció literal. Si necessites un registre exacte del que s'ha dit — cada paraula, cada pausa, cada «ehem» — els models Whisper locals hi excel·leixen. Taxes d'error de paraula del 5-8% en àudio net igualen els transcriptors humans. La transcripció és fidel al que s'ha dit.
El que la IA al núvol fa millor: resumir i extreure. GPT-4o pot escoltar una reunió i produir tasques pendents, resums i accions de seguiment. Entén el context més enllà de les paraules literals. Si vols «digue'm quines decisions s'han pres», la IA al núvol és realment millor.
La contrapartida és real. Si el teu flux de treball és «transcriure → resumir amb Claude/GPT», obtens el millor de tots dos móns: una transcripció local precisa i un resum intel·ligent al núvol. El teu àudio en brut es manté privat. Només el text que tries compartir surt del teu dispositiu.
La IA local no resol totes les parts del flux de treball. Els models de veu són bons transcrivint; els models de llenguatge són millors resumint i raonant sobre el resultat. Mantén l'àudio local i tria després un model de llenguatge local o al núvol segons la sensibilitat del text.
| Tasca | Millor eina | Per què |
|---|---|---|
| Transcripció literal | Whisper local | Privadesa, velocitat, precisió |
| Resum de reunió | LLM al núvol (sobre la transcripció) | Comprensió contextual |
| Extracció de tasques pendents | LLM al núvol (sobre la transcripció) | Raonament semàntic |
| Col·laboració en temps real | Servei al núvol (Otter, etc.) | Coordinació multiusuari |
Xifres de velocitat reals
L'elecció del model canvia el resultat més del que la paraula «local» suggereix. Parakeet és el model ràpid per defecte per a l'anglès i les llengües europees, SenseVoice està optimitzat per al xinès, el japonès, el coreà i el cantonès, i Whisper Large-v3 Turbo ofereix la cobertura més àmplia, amb més de 100 llengües.
| Dispositiu i model | Àudio de prova | Temps de processament | Millor per a |
|---|---|---|---|
| M4 Pro — Parakeet V3 | 35 min | ~20 s | Anglès i llengües europees |
| M4 Pro — SenseVoice | Podcast en xinès de 27 min | 13.83 s | Xinès, japonès, coreà, cantonès |
| M4 Pro — Whisper Turbo | Podcast en xinès de 27 min | 2 min 4 s | La cobertura lingüística més àmplia |
Mètode: Whisper Notes en un Apple M4 Pro amb 32 GB de RAM, temps real des de l'inici de la transcripció fins al text final. Parakeet va utilitzar una gravació de 35 minuts; SenseVoice i Whisper, el mateix podcast en xinès de 27 minuts. Són proves de producte, no benchmarks entre proveïdors de núvol.
La fitxa actual de l'App Store també informa d'uns 18 segons per a 5 minuts d'àudio amb Parakeet en un iPhone 15, davant d'aproximadament un minut amb Whisper. Els dispositius més antics són més lents. En tots els casos, la feina continua funcionant en mode avió perquè no hi ha cap pas de pujada.
Com transcriure àudio a text fora de línia (pas a pas)
Al Mac:
- Descarrega Whisper Notes per a Mac (prova gratuïta, sense compte).
- Tria un model a Configuració: Parakeet V3 per a velocitat en anglès, SenseVoice per al xinès, el japonès, el coreà o el cantonès, Whisper Large V3 Turbo per a més de 100 llengües. El model es descarrega un sol cop i després funciona fora de línia.
- Grava directament, o arrossega-hi qualsevol fitxer d'àudio o vídeo (MP3, WAV, M4A, MP4).
- Per a reunions en línia, activa la detecció de reunions. Zoom, Teams i Google Meet es detecten automàticament; l'àudio del sistema i el teu micròfon es capturen junts, i la transcripció es queda al teu Mac.
- El text apareix mentre es processa. Exporta'l com a TXT o SRT, o copia'l on vulguis.
A l'iPhone: instal·la Whisper Notes des de l'App Store, grava o importa des de Notes de Veu i Fitxers, i la transcripció s'executa al xip de la sèrie A. Activa primer el mode avió si vols la prova que no es puja res.
Com ho hem construït
Whisper Notes és la nostra implementació d'aquests principis. Val la pena destacar algunes decisions concretes:
Widgets a la pantalla de bloqueig
Les millors idees arriben en moments inoportuns. Hem creat widgets per a la pantalla de bloqueig perquè puguis començar a gravar amb un sol toc — sense obrir l'aplicació, sense autenticació, sense comprovar la connexió. El processament local significa disponibilitat immediata.
Un toc per gravar. Zero dependència de la xarxa.
Models adaptats al maquinari
Els Macs tenen marge tèrmic i energia de sobres. Els iPhones viuen a la teva butxaca. Tots dos executen ara la mateixa gamma de models — Parakeet V3 (el predeterminat), Whisper Large-v3 Turbo (809 milions de paràmetres) i SenseVoice — cadascun ajustat al seu maquinari. Les mateixes garanties de privadesa, amb un ús adequat dels recursos.
Les teves dades, els teus fitxers
Les transcripcions són fitxers al teu dispositiu. Formats estàndard, ubicacions estàndard. Sense bases de dades propietàries, sense dependència del proveïdor. Si Whisper Notes desaparegués demà, les teves gravacions continuarien sent accessibles. L'exportació massiva no és una funció prèmium — és l'estat natural de les dades que et pertanyen.
Les teves dades. Els teus formats. La teva destinació.
Vocabulari personalitzat
Argot tècnic, noms poc habituals, termes específics d'un camp — el vocabulari que més necessita una transcripció precisa sol ser el que menys vols pujar enlloc. Els prompts inicials et permeten afegir context localment. El model s'hi adapta sense que la teva terminologia es converteixi en dades d'entrenament.
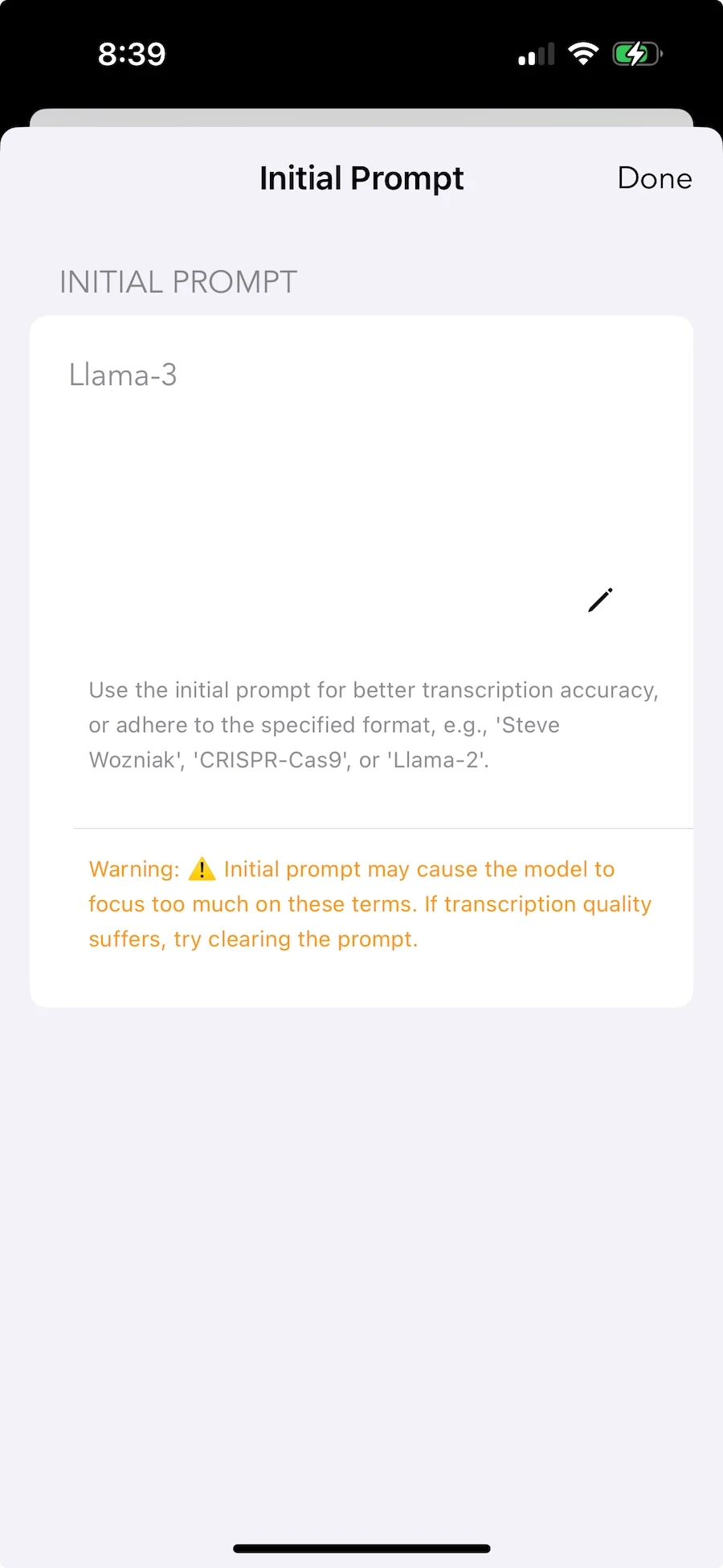
Personalització local. El teu vocabulari es manté privat.
Quan el núvol funciona millor
No pretenem que la transcripció local sigui universalment millor. El núvol té avantatges reals:
Col·laboració d'equip en temps real. Cinc persones editant una transcripció alhora durant una reunió requereix coordinació de servidor. Les eines locals són monousuari per naturalesa.
Identificació de parlants a gran escala. Saber «qui ha dit què» en gravacions amb diversos parlants es beneficia de dades d'entrenament a escala del núvol. La diarització al dispositiu existeix, però amb menys precisió per a grups grans.
Automatització de fluxos de treball. Els serveis al núvol es connecten a CRMs, extreuen tasques pendents i envien resums a Slack. Les eines locals produeixen fitxers de text — el que en facis després és manual.
Maquinari antic. Els iPhones anteriors a l'A14, els Macs amb Intel — alguns dispositius no poden executar inferència local de manera pràctica. El núvol continua sent l'única opció.
Si la teva necessitat principal és la col·laboració en equip durant reunions en directe, les eines al núvol probablement són millors. Si sobretot transcrius les teves pròpies gravacions i la privadesa t'importa, el processament local s'hi ajusta millor.
La trajectòria
Cada generació de xips aporta més rendiment al Neural Engine. Cada iteració dels models aporta més eficiència. La distància entre local i núvol s'escurça mentre els avantatges de privadesa i latència es mantenen constants.
La transcripció al núvol tenia sentit quan el teu telèfon no podia fer la feina. Aquella era es va acabar cap al 2022. El que queda és inèrcia — subscripcions en pagament automàtic, fluxos de treball construïts sobre supòsits de servidor, la vaga creença que el núvol ha de ser millor.
La qüestió no és si la transcripció local funciona. Funciona. La qüestió és si vols continuar pagant lloguer per un maquinari que ja és teu.
Detalls tècnics
Requisits de dispositiu: iOS 18 o posterior (es recomana un iPhone 12 o més recent) o un Mac amb Apple Silicon.
Models: Parakeet V3 per a 25 llengües europees, SenseVoice Small per al xinès, el japonès, el coreà i el cantonès, i Whisper Large V3 Turbo per a més de 100 llengües. Les tres famílies de motors funcionen localment al Mac i a l'iPhone.
Velocitat: Parakeet V3: 35 min d'àudio en 20 segons en un M4 Pro. SenseVoice: podcast en xinès de 27 min en 14 segons. Whisper Turbo: 35 min en ~3 minuts.
IA local al Mac: la versió DMG pot descarregar Gemma 4 per resumir gravacions, generar títols i respondre preguntes sobre una transcripció sense cap API al núvol.
Preu: $6.99 un sol pagament per plataforma. El Mac inclou una prova de 10.000 paraules; iOS i Mac són compres separades.
Veu a text fora de línia a Windows i Android
Whisper Notes està construït per a Apple Silicon, així que només funciona al Mac i l'iPhone. En altres plataformes, les opcions actuals són:
Windows: les millors opcions gratuïtes són Buzz (una interfície gràfica senzilla per a Whisper) i faster-whisper (línia d'ordres, diverses vegades més ràpid que la implementació de referència en el mateix maquinari). Tots dos funcionen completament fora de línia un cop descarregat el model. Compta amb més fricció de configuració que amb una aplicació nativa — entorns de Python, fitxers de model, controladors de GPU si vols velocitat.
Android: whisper.cpp té versions per a Android i algunes aplicacions que l'embolcallen, però la qualitat i el manteniment varien. Encara no hi ha cap aplicació de transcripció fora de línia polida i de referència a Android — consulta l'estat de Whisper Notes per a Android per veure com estan les coses.
Moltes persones buscant "Whisper Notes Windows"Vull el mateix model fora de línia, d'una sola compra, en un PC. T'entenem — però preferim dir "encara no" que enviar alguna cosa lenta (explicació completa a la Whisper Notes per a Windows pàgina). El Neural Engine d'Apple és el que fa 100x-transcripció local en temps real possible avui.
Traducció de veu fora de línia: què pot fer la IA local i què no
Sovint sorgeix una pregunta relacionada: la IA local pot traduir la parla, no només transcriure-la? Parcialment. El model original Whisper Large V3 es va entrenar per a dues tasques — la transcripció i la traducció de qualsevol llengua a l'anglès. Executat localment, pot agafar àudio en francès, japonès o àrab i produir text en anglès, completament fora de línia. Dues advertències: només tradueix cap a l'anglès (no en l'altra direcció), i això s'aplica al model Large V3 complet — la variant més ràpida Large-v3 Turbo va renunciar a la tasca de traducció per especialitzar-se en la transcripció.
La traducció de veu fora de línia encara està en una fase inicial. No hi ha cap aplicació de consum àmpliament adoptada que iguali la traducció de veu a veu en temps real a l'estil del núvol mantenint-se completament fora de línia. El flux de treball pràctic avui té dos passos: transcriu localment i després tradueix el text resultant amb una eina en què confiïs. L'àudio en brut no ha de sortir mai del teu dispositiu.
Preguntes freqüents
Es pot transcriure sense connexió a internet?
Sí. Whisper Notes és un programari de transcripció fora de línia que funciona completament al teu dispositiu. Els tres models d'IA — Parakeet V3, SenseVoice i Whisper — processen l'àudio localment amb el Neural Engine del teu Mac o el xip de la sèrie A del teu iPhone. No es puja cap dada, no es contacta cap servidor. Ho pots comprovar tu mateix activant el mode avió.
OpenAI Whisper funciona fora de línia?
Sí. OpenAI va publicar Whisper com a model de codi obert, cosa que vol dir que pot funcionar localment al teu maquinari. Whisper Notes empaqueta Whisper Large V3 Turbo perquè s'executi en Apple Silicon via CoreML/Metal — sense Python, sense línia d'ordres, sense internet. Admet més de 100 llengües amb reconeixement de veu fora de línia. Per a una anàlisi detallada de la família de models, consulta la nostra guia de transcripció amb Whisper.
Whisper Notes està disponible per a Windows o Android?
Encara no. Whisper Notes actualment és compatible amb el Mac (sèrie M) i l'iPhone (12 o posterior). Per a Windows, les alternatives inclouen faster-whisper (línia d'ordres) o Buzz (interfície gràfica). Potser donarem suport a altres plataformes en el futur, però el Neural Engine d'Apple Silicon ofereix ara mateix als usuaris de Mac la millor experiència local de veu a text.
Hi ha una aplicació gratuïta de transcripció fora de línia?
Whisper Notes ofereix una prova gratuïta de 10.000 paraules al Mac. Després, l'aplicació per a Mac costa $6.99 un sol cop; l'aplicació per a iPhone és una compra separada de $6.99. Cap de les dues plataformes té subscripció.
Com es compara Whisper Notes amb MacWhisper o faster-whisper?
MacWhisper és un frontend de Whisper només per a Mac. faster-whisper és una eina de línia d'ordres. Whisper Notes inclou Parakeet V3, SenseVoice i Whisper al Mac i l'iPhone, a més del dictat amb la tecla Fn al Mac i la captura des de la pantalla de bloqueig a l'iPhone. Cada plataforma és una compra única separada de $6.99.
Quin és el millor programari de veu a text fora de línia?
Depèn de la teva plataforma. Al Mac i l'iPhone, Whisper Notes ofereix tres motors locals per $6.99 per plataforma, amb una prova de 10.000 paraules al Mac. A Windows o Linux, Buzz (interfície gràfica) o faster-whisper (línia d'ordres) són gratuïts i de codi obert. El dictat integrat és suficient per a notes curtes, però no està dissenyat per a gravacions llargues.
Puc convertir àudio a text fora de línia gratis?
Sí. Whisper Notes per a Mac té una prova gratuïta, i les eines de codi obert com whisper.cpp, faster-whisper i Buzz són completament gratuïtes en totes les plataformes d'escriptori. També hi ha serveis gratuïts al núvol, però pugen el teu àudio — cosa que anul·la el propòsit si has buscat «fora de línia» precisament per la privadesa.
Puc executar Whisper com a API local amb LocalAI?
Sí. LocalAI és un servidor d'API de codi obert compatible amb OpenAI que pot servir models de whisper.cpp, de manera que pots allotjar al teu propi maquinari un substitut directe dels serveis de transcripció al núvol. És una bona opció per a desenvolupadors que construeixen fluxos fora de línia. Si vols els mateixos models sense configurar cap servidor, Whisper Notes els executa com a aplicació nativa al Mac i l'iPhone.