TL;DR -- Drei Mac-Modelle im Vergleich
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 Min Englisch | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 Min Chinesisch | 10,10s (161×) | 13,83s (118×) | 2 Min 4s (13,1×) |
| Sprachen | 25 (europaeisch) | 5 (zh, en, ja, ko, yue) | 99+ |
| Download | 465 MB | 827 MB | 1,5 GB |
| Speicher | ~800 MB | ~700 MB | ~1,6 GB |
| Am besten fuer | Englisch & europaeisch | Chinesisch, Japanisch, Koreanisch, Kantonesisch | Alles andere (99+ Sprachen) |
* Geschwindigkeitsbenchmarks auf Apple M4 Pro, 32 GB. 5-Minuten-Podcast auf Englisch und 27-Minuten-Podcast auf Chinesisch. Echtzeitfaktor = Audiodauer / Verarbeitungszeit (hoeher = schneller). SenseVoice ist nur fuer macOS. iOS verwendet Parakeet (ueber ANE) und Whisper.
Ab Version 1.4.8 liefert Whisper Notes fuer Mac SenseVoice Small als dedizierte Engine fuer chinesische, japanische, koreanische und kantonesische Transkription. Es ersetzt Qwen3-ASR und laeuft auf Apples GPU ueber MLX statt auf der CPU -- ein 27-minuetiger chinesischer Podcast wird in 13,83 Sekunden verarbeitet statt in 3 Minuten und 44 Sekunden.
Warum wir Qwen3-ASR ersetzt haben
Qwen3-ASR war ein solides Modell. Es unterstuetzte 30 Sprachen plus 22 chinesische Dialekte, und seine chinesische Genauigkeit war nahe am State-of-the-Art. Aber es hatte ein Problem, das mit der Audiodauer schlimmer wurde: die Geschwindigkeit.
Qwen3 verwendete eine autoregressive Architektur -- derselbe Ansatz wie Whisper, Audio Frame fuer Frame verarbeitend, ohne jemals vorauszuspringen. Bei einem 27-minuetigen chinesischen Podcast dauerte es 73 Sekunden. Brauchbar, aber nicht das Sofort-Ergebnis-Erlebnis, das Parakeet V3 fuer Englisch liefert.
Das tiefere Problem war unsere Infrastruktur. Unsere Qwen3-Integration verwendete sherpa-onnx, eine C-Bibliothek mit einem 2.249-Zeilen-Swift-Wrapper, der alles ueber CPU-Kerne leitete. Die GPU sass untaetig herum, waehrend die CPU Ihres Macs die ganze Arbeit machte.
SenseVoice hat beide Probleme geloest. Nicht-autoregressive Architektur fuer Geschwindigkeit. Apple MLX fuer GPU-Beschleunigung. Das Ergebnis: eine 16,2-fache Geschwindigkeitsverbesserung auf derselben Hardware, mit einer Codebasis, die von 2.249 Zeilen auf 288 reduziert wurde.
Der Benchmark
Alle drei Modelle laufen auf demselben Apple M4 Pro, dieselben Audiodateien, dieselben Bedingungen. Keine Cloud. Kein Internet. Nur Silizium.
| Modell | 5 Min Englisch | 27 Min Chinesisch | Geschwindigkeit (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103--161× |
| SenseVoice Small | 5,8s | 13,83s | 52--118× |
| Whisper Large V3 Turbo | 20,92s | 2 Min 4s | 13--14× |
| Qwen3-ASR (entfernt) | -- | 73s | 4,7× |
SenseVoice ist etwa halb so schnell wie Parakeet V3 -- immer noch ausserordentlich schnell. Ein 27-minuetiger Podcast ist in unter 14 Sekunden fertig. Sie druecken Transkribieren, warten einen Atemzug, und der Text ist da.
Vergleichen Sie das mit Whisper bei 2 Minuten und 4 Sekunden oder dem alten Qwen3 bei 73 Sekunden. Die Architektur zaehlt mehr als die Parameterzahl.
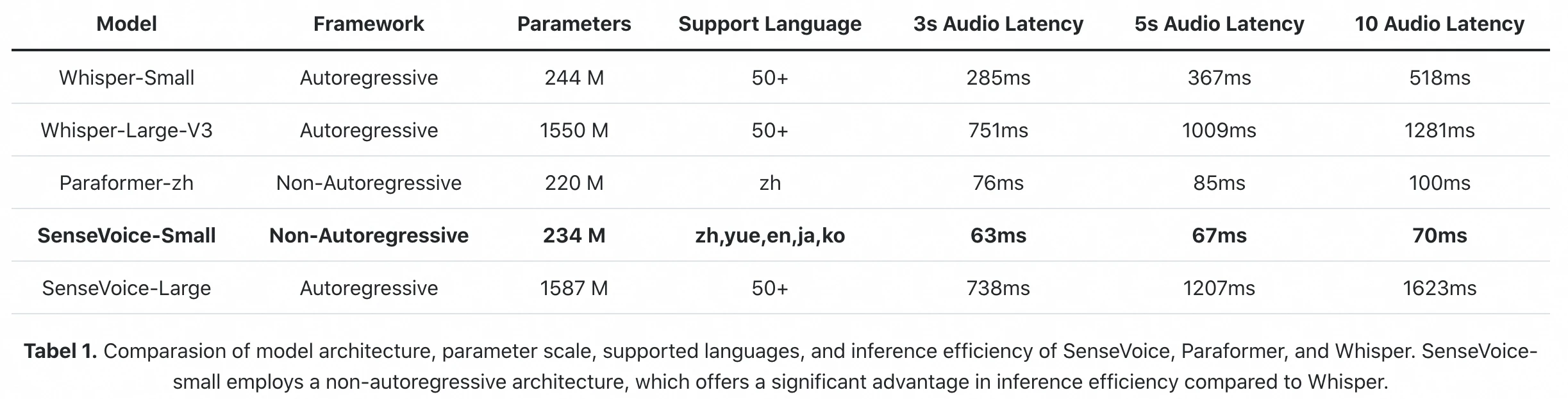
Offizieller Inferenz-Benchmark aus dem FunAudioLLM-Paper: SenseVoice-Small verarbeitet 10s Audio in 70ms (A800 GPU). Whisper-Large-V3 braucht 1.281ms. Das ist ein 18-facher Unterschied in der rohen Inferenzlatenz.
| Modell | Ladezeit | Speicher | Downloadgroesse |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81s | ~700 MB | 827 MB |
| Whisper Small | 1,03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18s | ~1,6 GB | 3 GB |
* Ladezeit und Speicher gemessen auf Apple M4 Pro, 32 GB.
SenseVoice laed in unter einer Sekunde und verbraucht weniger Speicher als Parakeet. Auf einem 8-GB-Mac laeuft es komfortabel neben Ihren anderen Anwendungen.
Warum SenseVoice schneller ist: Architektur + Laufzeit
Der Geschwindigkeitsunterschied zwischen Qwen3-ASR und SenseVoice kommt von zwei unabhaengigen Faktoren.
Faktor 1: Modellarchitektur. Qwen3-ASR ist autoregressiv -- es erzeugt Text Token fuer Token, wobei jedes vom vorherigen abhaengt. SenseVoice verwendet einen nicht-autoregressiven (NAR) Encoder, der das gesamte Audio parallel verarbeitet. Dieser architektonische Unterschied allein macht SenseVoice grundsaetzlich schneller, unabhaengig von der Hardware.
Faktor 2: Laufzeit. Unsere Qwen3-ASR-Integration verwendete sherpa-onnx, das auf der CPU lief. SenseVoice laeuft ueber Apple MLX und leitet die Berechnung an die GPU. Koennte Qwen3 auch auf MLX laufen? Ja -- aber es waere immer noch langsamer als SenseVoice, weil der autoregressive Flaschenhals in der Architektur liegt, nicht in der Laufzeit.
| Qwen3-ASR (alt) | SenseVoice (neu) | |
|---|---|---|
| Architektur | Autoregressiv (Token fuer Token) | Nicht-autoregressiv (parallel) |
| Laufzeit | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 Min Chinesisch | 224 Sekunden | 13,83 Sekunden |
| Kombinierte Beschleunigung | Basislinie | 16,2× schneller |
| Codebasis | 168 MB C-Framework + 2.249 Zeilen Swift | 288 Zeilen Swift Actor |
* Derselbe 27-minuetige chinesische Podcast, Apple M4 Pro. Die 16,2-fache Beschleunigung kombiniert sowohl architektonische (NAR vs AR) als auch Laufzeit-Verbesserungen (GPU vs CPU).
Der Code wurde auch einfacher. Die neue SenseVoice-Implementierung ist ein einzelner 288-Zeilen Swift Actor, der direkt mit MLX kommuniziert und ein 168 MB C-Framework ersetzt. Weniger Code, weniger Bugs, kleinere App.
Fuenf Sprachen, gut gemacht
SenseVoice versucht nicht, alles zu koennen. Es beherrscht fuenf Sprachen:
| Sprache | SenseVoice-Small | Whisper-Large-V3 | Gewinner |
|---|---|---|---|
| Chinesisch (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Kantonesisch (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japanisch (ja) | 11,96% CER | 10,34% CER | Whisper (knapp) |
| Koreanisch (ko) | 8,28% CER | 5,59% CER | Whisper |
| Englisch (en) | 14,71% WER | 9,39% WER | Whisper (Parakeet verwenden) |
* CommonVoice-Benchmark, CER = Character Error Rate, WER = Word Error Rate. Niedriger ist besser. Quelle: FunAudioLLM-Paper (2024). SenseVoice-Small Inferenzlatenz: 70ms pro 10s Audio (A800 GPU), mehr als 15× schneller als Whisper-Large-V3.
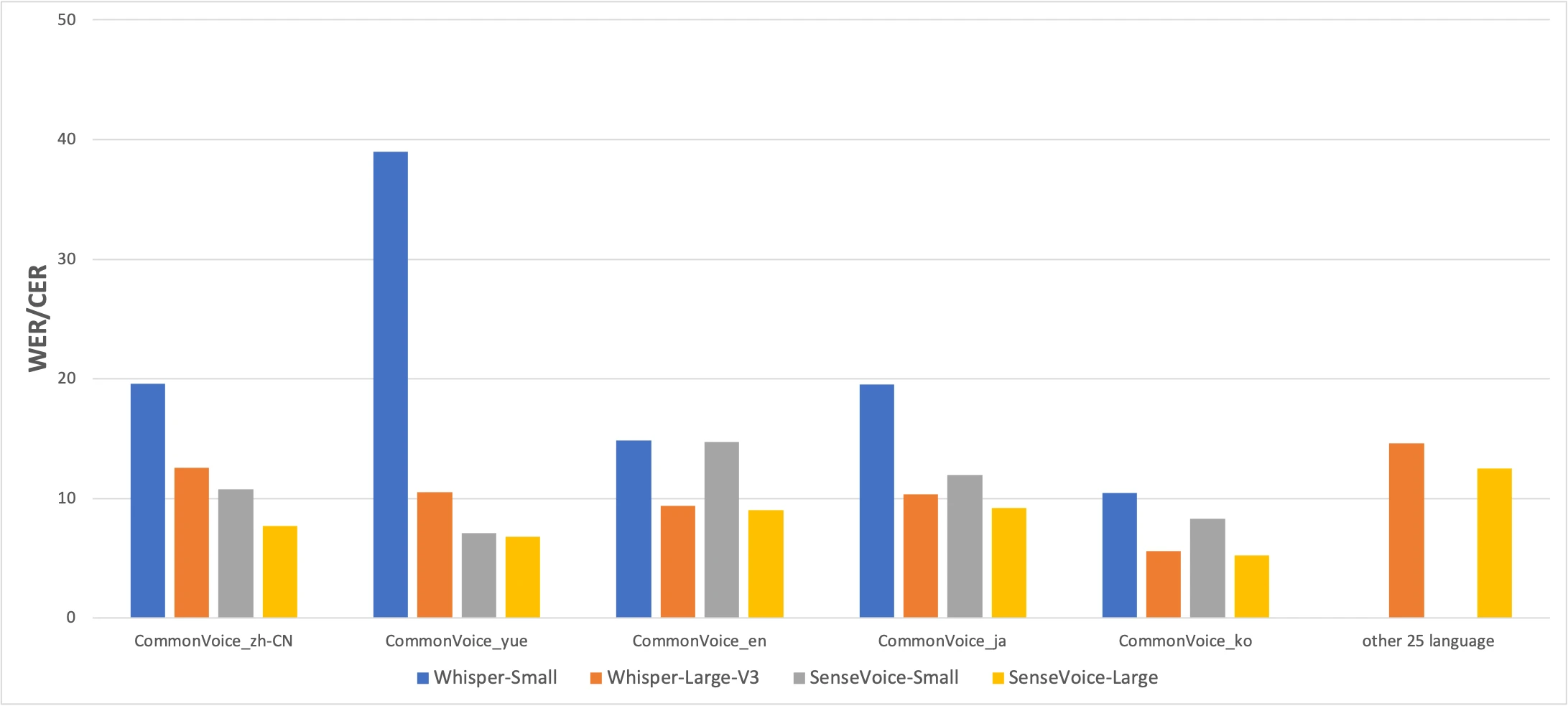
CommonVoice-Benchmark: SenseVoice-Small (gelb) vs Whisper-Small (blau) vs Whisper-Large-V3 (orange). Niedriger ist besser. Quelle: FunAudioLLM-Paper
Die Zahlen erzaehlen eine ehrliche Geschichte. SenseVoice schlaegt Whisper bei der Genauigkeit fuer Chinesisch und Kantonesisch mit deutlichem Vorsprung, waehrend Whisper bei Japanisch, Koreanisch und Englisch genauer ist. Aber SenseVoice ist mehr als 15× schneller als Whisper-Large-V3. Fuer die meisten realen Anwendungen zaehlt der Geschwindigkeitsunterschied mehr als ein paar Prozentpunkte Genauigkeit.
Das Kantonesisch-Ergebnis verdient besondere Hervorhebung. Whisper-Small erreicht 38,97% CER bei Kantonesisch -- nahezu unbrauchbar. Selbst Whisper-Large-V3 schafft nur 10,41%. SenseVoice erreicht 7,09%. Vor SenseVoice gab es keine gute Moeglichkeit, Kantonesisch lokal auf einem Mac zu transkribieren. Wenn Sie Kantonesisch sprechen, existiert dieses Modell fuer Sie.
Koreanische Transkription mit SenseVoice: Videoimport mit Zeitstempel-Untertiteln
Praxistest: 27-minuetiger chinesischer Podcast
Wir haben eine 27-minuetige Folge von Thirteen Invitations (十三邀), einem chinesischen Interview-Podcast, mit SenseVoice und Whisper Large V3 Turbo auf demselben M4 Pro transkribiert. ElevenLabs Scribe (Cloud) diente als Referenz. Beide lokalen Modelle machen etwa gleich viele Fehler, aber unterschiedlicher Art:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Zeit | 13,83s | 2 Min 4s |
| Fehler (5 Min Stichprobe) | ~15--20 | ~12--15 |
| Schlimmster Fehler | 时差→食堂 (Zeitzone→Kantine) | 西昌→西藏 (Stadt Xichang→Tibet, 4.000 km daneben) |
| Fehlermuster | Homophon-Verwechslungen | Geografische/faktische Fehler |
* Manueller Vergleich gegen ElevenLabs Scribe (Cloud-Referenz, ebenfalls nicht perfekt). Beide lokalen Modelle schrieben "根深蒂固" korrekt, wo Scribe falsch lag.
Vergleichbare Genauigkeit. 9× schneller. Fuer chinesische Transkription in der Praxis liefert SenseVoice ein brauchbares Transkript, bevor Whisper fertig geladen hat.
Wann welches Modell verwenden
Whisper Notes fuer Mac liefert jetzt vier Sprachmodelle. Jedes ist fuer unterschiedliche Szenarien optimiert:
| Sie brauchen... | Verwenden Sie dieses Modell | Warum |
|---|---|---|
| Englisch oder europaeische Sprachen, maximale Geschwindigkeit | Parakeet V3 | 103× Echtzeit, niedrigste Fehlerrate. Standard. |
| Chinesisch, Japanisch, Koreanisch oder Kantonesisch | SenseVoice Small | 52--118× Echtzeit. Einziges Modell mit Kantonesisch-Unterstuetzung. |
| Eine der 99+ Sprachen (Arabisch, Thailaendisch, Russisch usw.) | Whisper Large V3 Turbo | Breiteste Sprachunterstuetzung. Langsamer, aber universell. |
| Geringerer Speicherverbrauch (aeltere Macs) | Whisper Small | 487 MB Speicher. Gut fuer 8-GB-Macs mit anderen Apps. |
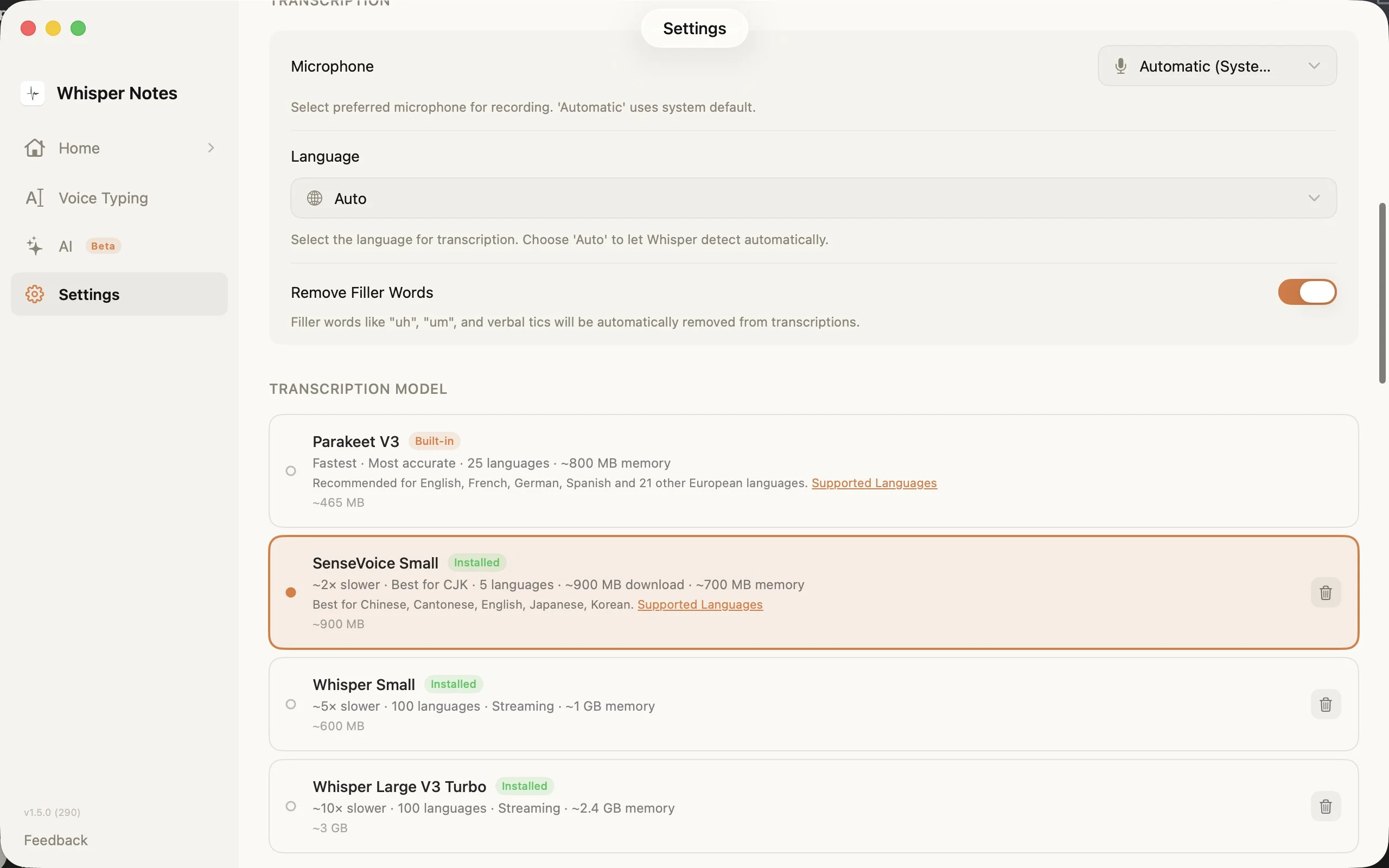
Einstellungen → Transkriptionsmodell: Waehlen Sie die richtige Engine fuer Ihre Sprache
Die Modellauswahl in den Einstellungen zeigt alle vier Optionen mit Downloadgroessen, Sprachanzahl und Speicheranforderungen. SenseVoice wird bei der ersten Verwendung heruntergeladen (~827 MB) und bleibt auf Ihrem Geraet.
Die Kompromisse
SenseVoice ist kein universelles Modell. Das kann es nicht:
* Nur 5 Sprachen. Wenn Sie Thailaendisch, Russisch, Arabisch, Hindi oder eine der anderen 90+ Sprachen brauchen, die Whisper unterstuetzt, bleiben Sie bei Whisper.
* Nur Mac. SenseVoice laeuft ueber Apple MLX, das macOS erfordert. Es ist nicht auf dem iPhone verfuegbar. iOS-Nutzer haben Parakeet (fuer europaeische Sprachen) und Whisper.
* Eigenart bei leisem Audio. Bei sehr kurzen oder sehr leisen Segmenten kann SenseVoice manchmal auf chinesische Ausgabe zurueckfallen, unabhaengig von der gewaehlten Sprache. Die Sprache manuell einzustellen (statt "Auto") reduziert dies.
* Kein Streaming. Anders als Whispers Streaming-Modus verarbeitet SenseVoice das gesamte Audio nach der Aufnahme. Bei langen Dateien segmentiert es automatisch an Stille-Punkten und zeigt Ergebnisse progressiv an.
Das sind architektonische Einschraenkungen, keine Bugs. Ein Modell, das auf 5 Sprachen trainiert wurde, beherrscht diese 5 Sprachen ausserordentlich gut. Whispers Unterstuetzung fuer 99+ Sprachen geht mit langsamerer Geschwindigkeit und hoeheren Fehlerraten bei jeder einzelnen Sprache einher.
Ausprobieren
SenseVoice ist in Whisper Notes fuer Mac v1.4.8 und spaeter verfuegbar. Laden Sie es herunter unter Einstellungen → Transkriptionsmodell → SenseVoice Small (~827 MB). Es erfordert einen Apple-Silicon-Mac (M1 oder neuer).
Wenn Sie Parakeet V3 verwenden und hauptsaechlich auf Englisch diktieren, muessen Sie nicht wechseln. SenseVoice ist fuer den Fall, dass Sie Chinesisch, Japanisch, Koreanisch oder Kantonesisch brauchen -- und es schnell haben wollen.
Vollstaendiges Changelog: whispernotes.app/changelog
Fragen oder Feedback: mac@whispernotes.app