TL;DR
| Parakeet V3 | Whisper 對照 | |
|---|---|---|
| 速度 | 10× vs Turbo;約 23× vs V3 | Turbo / Large V3 基準 |
| 支援語種 | 25 | 100+ |
| 英語錯誤率 (WER) | 6.32% | Turbo 7.83%;V3 7.44% |
| 25 種語言平均錯誤率 (WER) | 12.0% | 12.6% |
| 幻覺 | 我們的靜音測試中幾乎為零 | 靜音時可能出現 |
| 適用 | 英語和歐洲語言 | 亞洲、阿拉伯等 100+ 種語言 |
* 速度:35 分鐘音訊,Apple Silicon 實測。英語 WER:Hugging Face Open ASR Leaderboard。25 語言均值:FLEURS 基準測試。靜音表現為我們的產品觀察,並非零錯誤保證。
從 1.3.2 (Direct Download / DMG) 版開始,Mac 版 Whisper Notes 預設使用 NVIDIA Parakeet TDT 0.6B 作為語音引擎。英文轉錄速度比 Whisper Large V3 Turbo 快 10 倍,準確度也更高。如果你需要其他語言,Whisper 模型依然可以使用。
為什麼換掉預設模型
Whisper 很好用,但它本質上是個通用模型——支援 100+ 種語言、能翻譯、能產生時間戳,根本就是把瑞士刀。代價就是速度。對於英文聽寫這種只需要快速出字的情境,它實在太重了。
最讓我受不了的是:用 Fn 鍵啟動全系統語音輸入時,講完大約 1 分鐘的話,要等 3 到 5 秒才看得到轉錄結果。這段等待直接打斷了節奏——你講完了,盯著游標,什麼都沒出來,語音打字的魔力瞬間消失。
Parakeet 徹底改變了這件事。它快到你話音剛落,文字就出現了。說完即得,毫無延遲。一旦體驗過這種感覺——這種絲滑、零等待的流暢——就很難再回去用 Whisper 了。
Parakeet V3 到底有多快?
數字最有說服力。同一台 Mac 上,同一段 35 分鐘的音檔:
| 模型 | 35 分鐘音檔 |
|---|---|
| Whisper Large V3 Turbo | 3 分鐘 |
| Parakeet TDT 0.6B v3 | 18 秒 |
快了 10 倍。而且模型更小(6 億 vs 8 億參數),記憶體和電量消耗也更低。
Parakeet v3 為什麼這麼快
Whisper 處理音訊的方式就像逐字朗讀一本書——一幀一幀,從不跳過。就算是靜音,它也在處理、在猜測下一個詞是什麼。這很嚴謹,但太慢了。
Parakeet 的做法完全不同。它先把音訊訊號壓縮 8 倍,只留下關鍵資訊。接著,它不再逐幀硬磨,而是同時預測兩件事:你說了什麼詞,以及這個詞持續多久——然後直接跳到下一個詞。靜音?直接跳過。一個長母音?一次預測就搞定,不用重複幾十次。
結果就是,模型處理語音的方式更像你的大腦——只關注有意義的詞,忽略中間的空白。這就是為什麼它用更少的參數、更高的準確率,做到了 10 倍的速度。
基準測試:Parakeet v3 vs Whisper
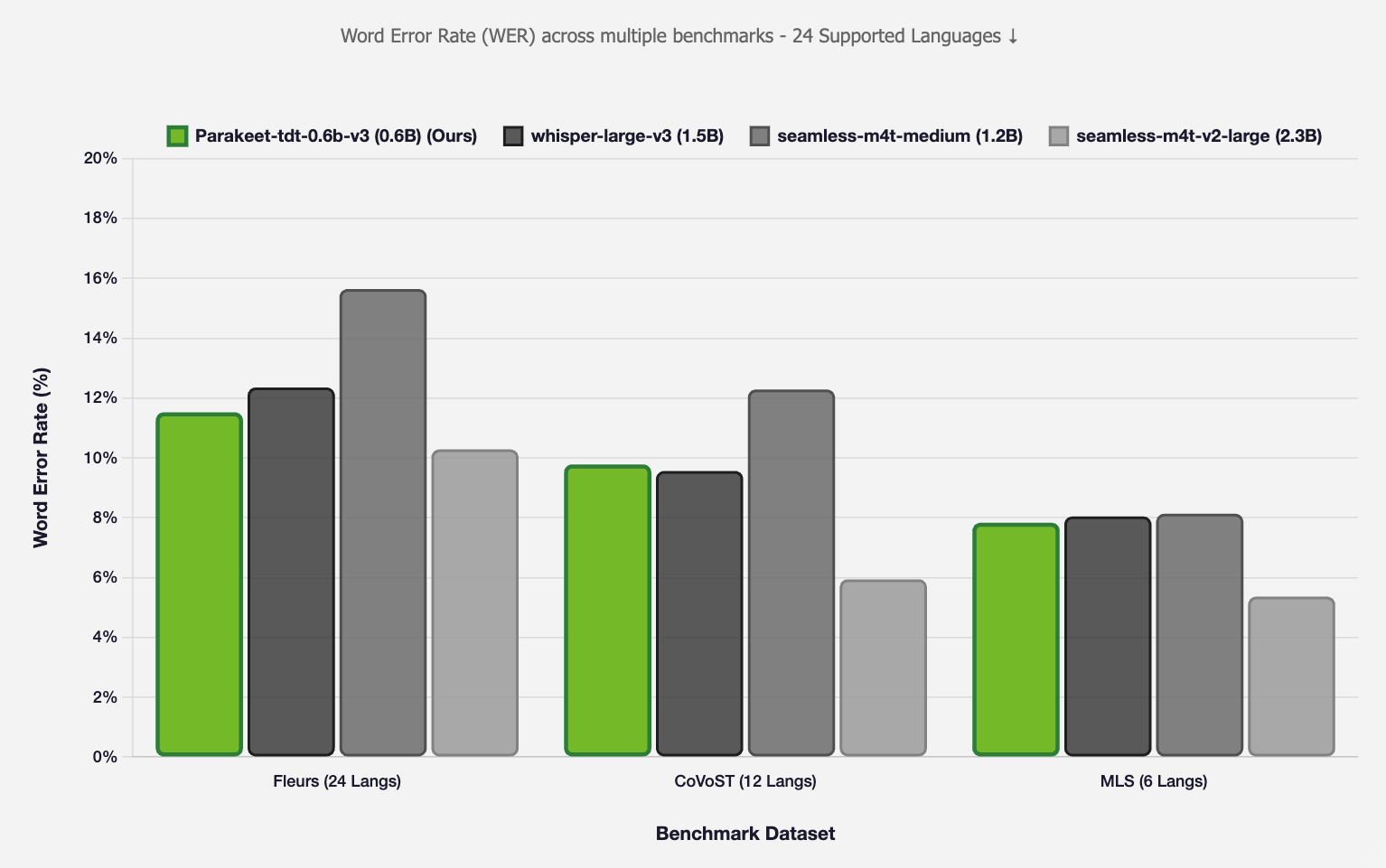
Parakeet v3 在 FLEURS、CoVoST 和 MLS 基準測試中,表現媲美甚至超越參數量 2-4 倍的模型
在 Hugging Face Open ASR 排行榜上,Parakeet v3 僅憑 6 億參數就拿下榜首——不到 Whisper Large V3 的 15.5 億參數的一半:
| 模型 | 參數量 | 平均詞錯率 | 速度 (RTFx) |
|---|---|---|---|
| Parakeet TDT 0.6B v3 | 6 億 | 6.32% | 3,333x |
| Canary 1B v2 | 10 億 | 7.15% | 749x |
| Whisper Large V3 | 15.5 億 | 7.44% | 146x |
| Whisper Large V3 Turbo | 8 億 | 7.83% | 350x |
多語言詞錯率:全部 25 種語言
上面的排行榜只涵蓋英語。接下來是完整面貌——Whisper Notes 中可用的三個模型在 Parakeet 支援的全部 25 種語言上的表現,基於 FLEURS 基準測試。詞錯率越低 = 轉錄錯誤越少。每列中 Large V3 和 Parakeet 的最佳值已高亮顯示:
| 語言 | Whisper Small | Whisper Large V3 | Parakeet V3 |
|---|---|---|---|
| 保加利亞語 | 37.3 | 12.9 | 12.6 |
| 克羅埃西亞語 | 33.4 | 11.1 | 12.5 |
| 捷克語 | 37.6 | 11.3 | 11.0 |
| 丹麥語 | 32.8 | 12.6 | 18.4 |
| 荷蘭語 | 16.4 | 5.6 | 7.5 |
| 英語 | 6.1 | 4.3 | 4.9 |
| 愛沙尼亞語 | 51.3 | 19.1 | 17.7 |
| 芬蘭語 | 24.0 | 7.7 | 13.2 |
| 法語 | 15.0 | 6.3 | 5.2 |
| 德語 | 10.2 | 4.3 | 5.0 |
| 希臘語 | 30.8 | 27.0 | 20.7 |
| 匈牙利語 | 38.9 | 14.1 | 15.7 |
| 義大利語 | 9.8 | 2.3 | 3.0 |
| 拉脫維亞語 | 53.2 | 18.3 | 22.8 |
| 立陶宛語 | 65.6 | 22.3 | 20.4 |
| 馬爾他語 | 92.2 | 68.9 | 20.5 |
| 波蘭語 | 14.7 | 4.7 | 7.3 |
| 葡萄牙語 | 7.3 | 3.7 | 4.8 |
| 羅馬尼亞語 | 29.8 | 8.2 | 12.4 |
| 俄語 | 11.4 | 4.2 | 5.5 |
| 斯洛伐克語 | 33.3 | 8.4 | 8.8 |
| 斯洛維尼亞語 | 49.3 | 19.9 | 24.0 |
| 西班牙語 | 5.6 | 3.1 | 3.5 |
| 瑞典語 | 20.8 | 7.9 | 15.1 |
| 烏克蘭語 | 19.3 | 6.5 | 6.8 |
| 平均 | 29.8 | 12.6 | 12.0 |
詞錯率(%)基於 FLEURS 測試集。Whisper Small 資料來自 Radford 等人;Large V3 和 Parakeet V3 資料來自 NVIDIA Canary-1B-v2 論文。
Whisper Large V3 在多數個別語言上略勝一籌,但 Parakeet V3 的平均值緊追在後(12.0% vs 12.6%),在希臘語、法語、愛沙尼亞語和馬爾他語上反而領先,還把 Whisper Small 的平均錯誤率砍掉約 60%。真正的實用優勢在於整體組合:接近 Large V3 等級的多語言準確率、大約 23 倍的速度、更小的執行時佔用,以及在我們的聽寫測試中可靠得多的靜音處理。
為什麼它在靜音時幻覺較少
如果你用 Whisper 做過聽寫,大概遇過它在靜音時產生幻覺——重複句子、憑空造詞,甚至突然冒出「Subtitles by Amara.org」這種莫名其妙的文字。這是因為 Whisper 的自迴歸解碼器總是預期要產生文字,就算根本沒有內容可轉錄。
Parakeet 的 transducer 架構可以輸出空白,而不是硬擠出一個文字 token。在我們的系統級聽寫測試中,這讓它遠比 Whisper 更不容易把停頓填成重複或不相干的文字。它終究還是語音模型,所以準確的說法是「比較不容易」,而不是「絕對不會」。
Parakeet 支援的語言
Parakeet v3 支援 25 種語言:保加利亞語、克羅埃西亞語、捷克語、丹麥語、荷蘭語、英語、愛沙尼亞語、芬蘭語、法語、德語、希臘語、匈牙利語、義大利語、拉脫維亞語、立陶宛語、馬爾他語、波蘭語、葡萄牙語、羅馬尼亞語、俄語、斯洛伐克語、斯洛維尼亞語、西班牙語、瑞典語和烏克蘭語。
基本上涵蓋了整個歐洲,但不包括中文、日文、韓文、阿拉伯語和印地語。中文、日文、韓文和粵語,請選 SenseVoice;阿拉伯語、印地語等 Parakeet 未涵蓋的語言,就用 Whisper Large V3 Turbo。
模型選擇器:Parakeet V3(預設)、SenseVoice Small、Whisper Small 和 Whisper Large V3 Turbo — 全部在本機運行
Whisper Notes 中的模型選擇器
打開設定即可切換模型:
- Parakeet V3(預設)— 最快,最適合英語和歐洲語言
- SenseVoice Small — 中文、日文、韓文和粵語的最快選擇
- Whisper Small — 輕量級,支援 100+ 種語言
- Whisper Large V3 Turbo — 廣泛覆蓋 100+ 種語言
所有模型都在你的 Mac 上 100% 本機運行。不需要網路,不經過雲端,資料不會離開你的裝置。
Parakeet V2 呢?
如果你之前用過 V2,可能想知道它和 V3 有什麼不同。V2 是純英語模型,英語準確率其實比 V3 略高(WER 6.05% vs 6.32%)。V3 用這一點差距換來了 25 種語言的支援。不過兩者都比 Whisper 準確得多。
| Parakeet V2 | Parakeet V3 | Whisper Large V3 | |
|---|---|---|---|
| 英語 WER | 6.05% | 6.32% | 7.44% |
| 支援語種 | 僅英語 | 25 | 100+ |
簡單來說:如果你只需要英語,V2 和 V3 都很優秀。Whisper Notes 預設使用 V3,因為多語言支援對大多數使用者更有價值——英語準確率的差異幾乎可以忽略。
那 WhisperKit 呢?
WhisperKit 是 Argmax 開發的開源 Swift 框架,用來在 Apple 裝置上執行 Whisper 模型。它是給開發者用的工具包,不是給一般使用者的應用程式——而且它跑的是 Whisper,不是 Parakeet(那是 NVIDIA 的模型系列)。如果你想要 WhisperKit 這種裝置端語音辨識,又不想自己寫 Swift,Whisper Notes 把同樣的概念做成了現成的 App:Parakeet V3、Whisper Large V3 Turbo 和 SenseVoice,全部在 Mac 和 iPhone 上本機運行。
想比較所有本機方案?每一個裝置端語音轉文字模型——Whisper 各版本、Parakeet V3、SenseVoice 和 Voxtral——都在我們的 Whisper 模型比較頁面上並排比較。還不熟悉 Whisper 本身?可以先讀 Whisper 逐字稿指南——這個模型是什麼、有哪些執行方式、各要花多少錢。
常見問題
Parakeet V3 比 Whisper 好嗎?
對英語和歐洲語言來說,通常是的。在我們 35 分鐘的實測中,Parakeet 比 Whisper Turbo 快 10 倍;Open ASR Leaderboard 上 Parakeet 的英語 WER 是 6.32%,Turbo 則是 7.83%。不過 Whisper 涵蓋的語言遠多得多:100+ 種對上 Parakeet 的 25 種。
Parakeet V3 支援哪些語言?
Parakeet V3 支援 25 種語言:保加利亞語、克羅埃西亞語、捷克語、丹麥語、荷蘭語、英語、愛沙尼亞語、芬蘭語、法語、德語、希臘語、匈牙利語、義大利語、拉脫維亞語、立陶宛語、馬爾他語、波蘭語、葡萄牙語、羅馬尼亞語、俄語、斯洛伐克語、斯洛維尼亞語、西班牙語、瑞典語和烏克蘭語。
可以在 Mac 上執行 Parakeet V3 嗎?
可以。Whisper Notes Mac 版將 Parakeet V3 內建為預設引擎,在 Apple Silicon 上 100% 本機運行——不需要網路、不經過雲端,資料不會離開你的裝置。下載免費試用版 DMG 就能體驗。
Parakeet V3 會像 Whisper 一樣產生幻覺嗎?
在我們的靜音測試中頻率低得多,但沒有任何語音模型配得上「絕對不會」的說法。Parakeet 在停頓時可以輸出空白,而 Whisper 的自迴歸解碼器在輸入是靜音時,更容易生出重複句子或不相干的文字。
Parakeet V2 和 V3 該用哪個?
Parakeet V2 是純英語模型,英語準確率略高(WER 6.05% vs 6.32%)。V3 用這一點差距換來 25 種歐洲語言支援,也是 Whisper Notes 的預設模型。除非你只做英語逐字稿、又非得計較那零點幾個百分點,否則用 V3 就對了。
Parakeet V3 支援日文、中文或韓文嗎?
不支援——它的 25 種語言全是歐洲語言。中文、日文、韓文或粵語,可以用 Whisper Notes 內建的 SenseVoice(處理中日韓語音比 Whisper 快 52 倍)和 Whisper 模型。全部都能在 Mac 和 iPhone 上離線運行。
Parakeet V3 有多大?
6 億參數——下載檔案 465 MB,轉錄時約佔用 800 MB 記憶體。相較之下,Whisper Large V3 Turbo 下載約 1.6 GB,記憶體佔用約 1.6 GB。
來試試看
Parakeet v3 已經在 Mac 版中可以使用了——直接下載最新的 DMG 就能體驗。(更新:最新版 iOS 已支援 Parakeet。)
有問題或建議?歡迎寄信到 support@whispernotes.app。