TL;DR — 三款 Mac 模型比較
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 分鐘英語 | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| 27 分鐘中文 | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| 支援語言 | 25(歐洲語言) | 5(zh, en, ja, ko, yue) | 99+ |
| 下載大小 | 465 MB | 827 MB | 1.5 GB |
| 記憶體 | ~800 MB | ~700 MB | ~1.6 GB |
| 最適合 | 英語與歐洲語言 | 中文、日語、韓語、粵語 | 其他所有語言(99+) |
* 速度測試基於 Apple M4 Pro, 32 GB。5 分鐘英語 Podcast 和 27 分鐘中文 Podcast。即時倍率 = 音訊時長 ÷ 處理時間(越高越快)。SenseVoice 僅限 macOS。iOS 使用 Parakeet(透過 ANE)和 Whisper。
從 1.4.8 版本起,Mac 版 Whisper Notes 搭載 SenseVoice Small 作為中文、日語、韓語和粵語的專用轉寫引擎。它取代了 Qwen3-ASR,透過 MLX 在 Apple GPU 上運行,而非 CPU——27 分鐘的中文 Podcast 從 3 分 44 秒縮短到 13.83 秒。
為什麼替換 Qwen3-ASR
Qwen3-ASR 是一個不錯的模型,支援 30 種語言和 22 種中文方言,中文準確率接近頂尖水準。但它有一個隨音訊時長惡化的問題:速度。
Qwen3 採用自回歸架構——和 Whisper 一樣,逐幀處理音訊,永遠無法跳過。27 分鐘的中文 Podcast 需要 73 秒。堪用,但遠不是 Parakeet V3 在英語上提供的即時體驗。
更深層的問題在基礎架構。我們的 Qwen3 整合使用 sherpa-onnx,一個帶有 2,249 行 Swift 封裝的 C 函式庫,所有運算都走 CPU。GPU 完全閒置。
SenseVoice 同時解決了這兩個問題:非自回歸架構實現速度提升,Apple MLX 實現 GPU 加速。結果:同樣的硬體上 16.2 倍速度提升,程式碼從 2,249 行減少到 288 行。
效能測試
三個模型在同一台 Apple M4 Pro 上、同樣的音訊檔案、同樣的條件下運行。無雲端,無網路,純靠晶片。
| 模型 | 5 分鐘英語 | 27 分鐘中文 | 速度 (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103–161× |
| SenseVoice Small | 5.8s | 13.83s | 52–118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13–14× |
| Qwen3-ASR(已移除) | — | 73s | 4.7× |
SenseVoice 大約是 Parakeet V3 速度的一半——但依然快得驚人。27 分鐘的 Podcast 在 14 秒內完成。按下轉寫,等一次呼吸,文字就出來了。
對比 Whisper 的 2 分 4 秒或舊版 Qwen3 的 73 秒。架構比參數量更重要。
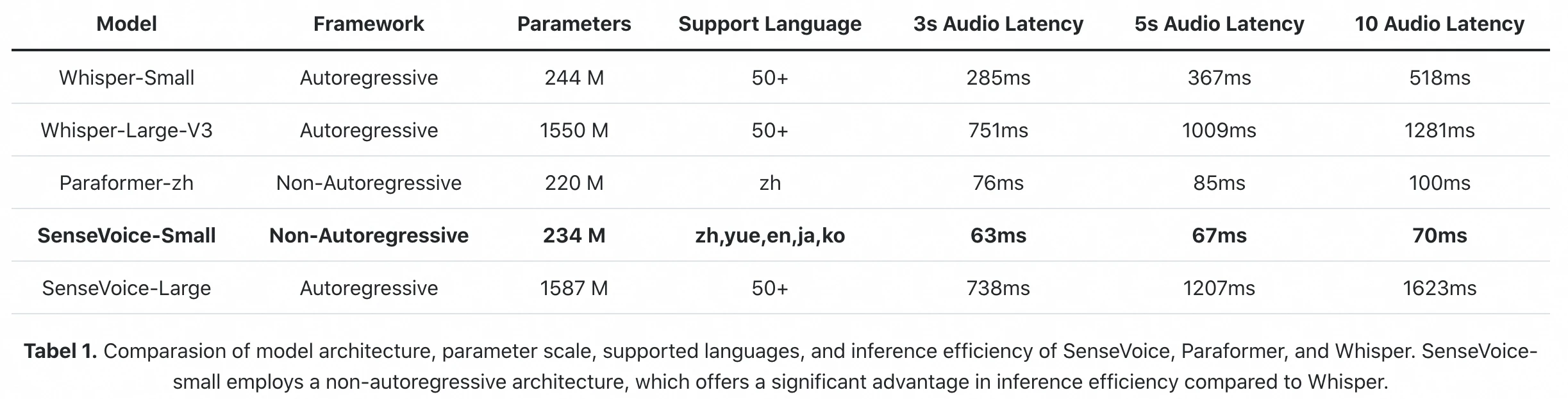
FunAudioLLM 論文官方推理效能測試:SenseVoice-Small 處理 10 秒音訊僅需 70ms(A800 GPU)。Whisper-Large-V3 需要 1,281ms。原始推理延遲相差 18 倍。
| 模型 | 載入時間 | 記憶體 | 下載大小 |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* 載入時間和記憶體基於 Apple M4 Pro, 32 GB 測量。
SenseVoice 在一秒內載入完畢,記憶體佔用比 Parakeet 還少。在 8 GB 的 Mac 上也能和其他應用程式一起順暢運行。
SenseVoice 為什麼更快:架構 + 執行環境
Qwen3-ASR 和 SenseVoice 之間的速度差距來自兩個獨立因素。
因素一:模型架構。 Qwen3-ASR 是自回歸的——逐個產生 token,每個都依賴前一個。SenseVoice 使用非自回歸(NAR)編碼器,平行處理整段音訊。僅憑這一架構差異,無論運行在什麼硬體上,SenseVoice 都從根本上更快。
因素二:執行環境。 我們的 Qwen3-ASR 整合使用 sherpa-onnx,在 CPU 上運行。SenseVoice 透過 Apple MLX 運行,將運算路由到 GPU。Qwen3 也能用 MLX 運行嗎?能——但它仍然會比 SenseVoice 慢,因為自回歸瓶頸在架構而非執行環境。
| Qwen3-ASR(舊) | SenseVoice(新) | |
|---|---|---|
| 架構 | 自回歸(逐 token) | 非自回歸(平行處理) |
| 執行環境 | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 分鐘中文 | 224 秒 | 13.83 秒 |
| 綜合加速 | 基準值 | 快 16.2 倍 |
| 程式碼量 | 168 MB C 框架 + 2,249 行 Swift | 288 行 Swift Actor |
* 同一段 27 分鐘中文 Podcast,Apple M4 Pro。16.2 倍加速同時包含架構(NAR vs AR)和執行環境(GPU vs CPU)的改進。
程式碼也變簡單了。新的 SenseVoice 實作是一個 288 行的 Swift Actor,直接與 MLX 通訊,取代了 168 MB 的 C 框架。程式碼更少,bug 更少,應用程式更小。
五種語言,做到極致
SenseVoice 不追求面面俱到。它專注於五種語言:
| 語言 | SenseVoice-Small | Whisper-Large-V3 | 勝者 |
|---|---|---|---|
| 中文 (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| 粵語 (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| 日語 (ja) | 11.96% CER | 10.34% CER | Whisper(略優) |
| 韓語 (ko) | 8.28% CER | 5.59% CER | Whisper |
| 英語 (en) | 14.71% WER | 9.39% WER | Whisper(建議用 Parakeet) |
* CommonVoice 效能測試,CER = 字元錯誤率,WER = 單詞錯誤率。越低越好。來源:FunAudioLLM 論文 (2024)。SenseVoice-Small 推理延遲:10 秒音訊 70ms(A800 GPU),比 Whisper-Large-V3 快 15 倍以上。
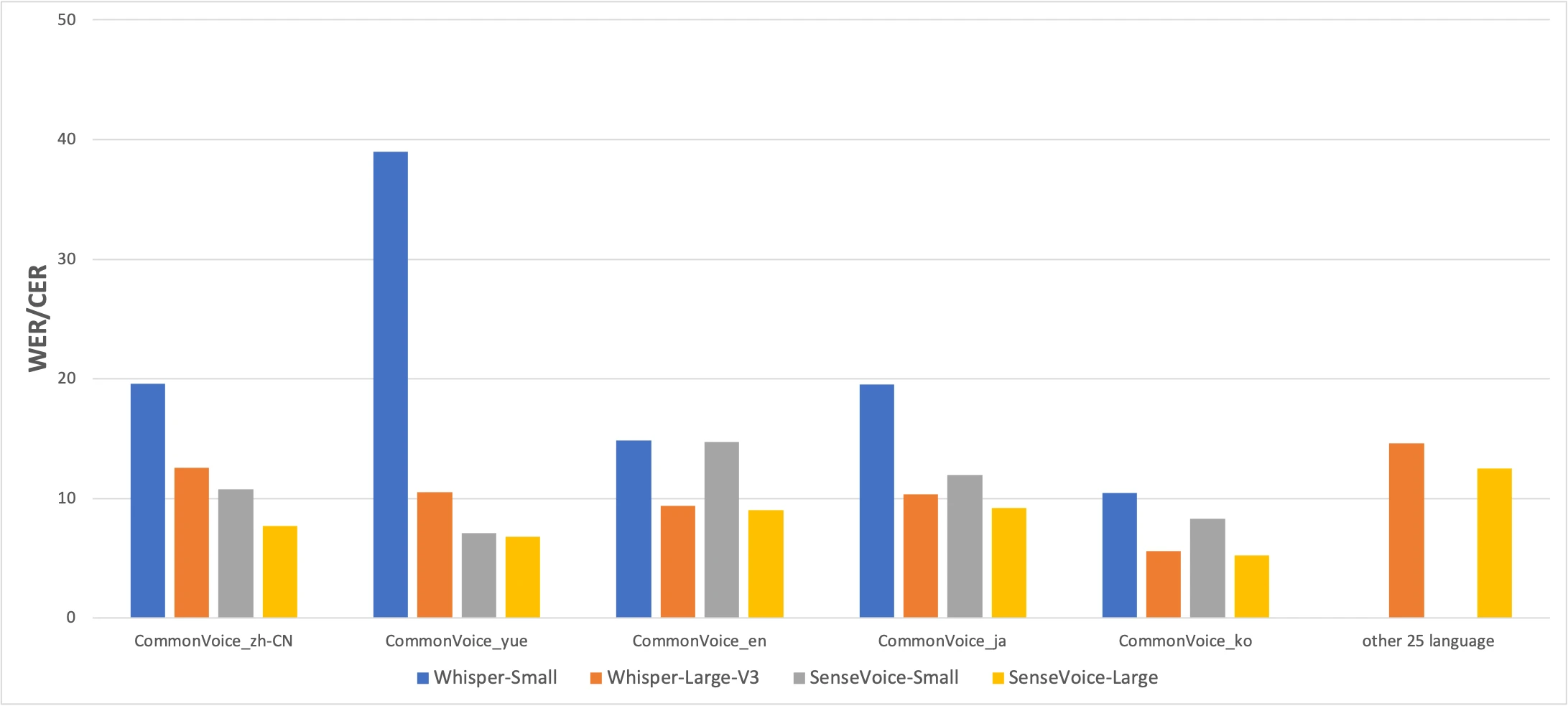
CommonVoice 效能測試:SenseVoice-Small(黃色)vs Whisper-Small(藍色)vs Whisper-Large-V3(橘色)。越低越好。來源:FunAudioLLM 論文
數據說明了一切。SenseVoice 在中文和粵語準確率上大幅領先 Whisper,而 Whisper 在日語、韓語和英語上更準確。但 SenseVoice 比 Whisper-Large-V3 快 15 倍以上。在實際使用中,速度差異往往比幾個百分點的準確率更重要。
粵語的結果值得特別一提。Whisper-Small 在粵語上的 CER 高達 38.97%——幾乎無法使用。即便是 Whisper-Large-V3 也只做到 10.41%。SenseVoice 達到了 7.09%。在 SenseVoice 之前,沒有好的方法在 Mac 上本地轉寫粵語。如果你講粵語,這個模型就是為你而生的。
SenseVoice 韓語轉寫:帶時間戳字幕的影片匯入
實測:27 分鐘中文 Podcast
我們用 SenseVoice 和 Whisper Large V3 Turbo 在同一台 M4 Pro 上轉寫了一集 27 分鐘的《十三邀》(Thirteen Invitations),一檔中文訪談 Podcast。以 ElevenLabs Scribe(雲端)作為參考。兩個本地模型的錯誤數量大致相當,但類型不同:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| 耗時 | 13.83s | 2 min 4s |
| 錯誤數(5 分鐘樣本) | ~15–20 | ~12–15 |
| 最嚴重錯誤 | 时差→食堂 | 西昌→西藏(Xīchāng→Xīzàng,相差 4,000 公里) |
| 錯誤模式 | 同音字混淆 | 地理/事實性錯誤 |
* 與 ElevenLabs Scribe(雲端參考,也並非完美)手動比較。兩個本地模型都正確寫出了「根深蒂固」,而 Scribe 寫錯了。
準確率相當。速度快 9 倍。在實際中文轉寫場景中,Whisper 還沒載入完,SenseVoice 已經給你一份可用的文稿了。
什麼時候用哪個模型
Mac 版 Whisper Notes 現已搭載四個語音模型,各自針對不同場景最佳化:
| 你的需求 | 推薦模型 | 原因 |
|---|---|---|
| 英語或歐洲語言,追求極致速度 | Parakeet V3 | 103× 即時,最低錯誤率。預設選擇。 |
| 中文、日語、韓語或粵語 | SenseVoice Small | 52–118× 即時。唯一支援粵語的模型。 |
| 99+ 語言中的任何一種(阿拉伯語、泰語、俄語等) | Whisper Large V3 Turbo | 語言覆蓋最廣。速度較慢但通用性強。 |
| 低記憶體需求(舊款 Mac) | Whisper Small | 487 MB 記憶體。適合 8 GB Mac。 |
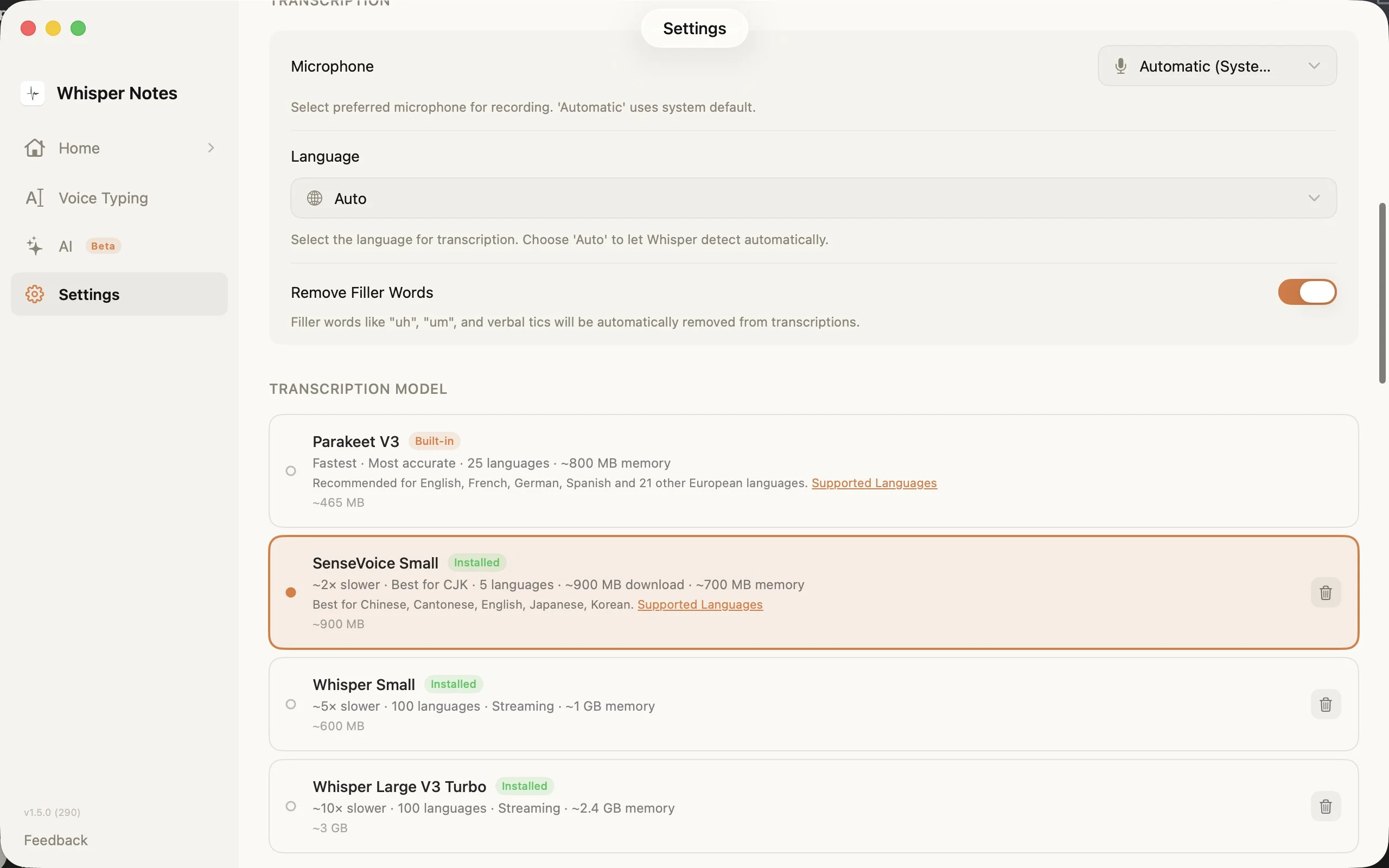
設定 → 轉寫模型:為你的語言選擇合適的引擎
設定中的模型選擇器展示了全部四個選項,包含下載大小、支援語言數和記憶體需求。SenseVoice 在首次使用時下載(約 827 MB),之後儲存在本地。
取捨
SenseVoice 不是萬能模型。以下是它做不到的事:
• 僅支援 5 種語言。 如果你需要泰語、俄語、阿拉伯語、印地語或 Whisper 支援的其他 90 多種語言,請繼續使用 Whisper。
• 僅限 Mac。 SenseVoice 透過 Apple MLX 運行,需要 macOS。iPhone 上無法使用。iOS 使用者可使用 Parakeet(歐洲語言)和 Whisper。
• 低音量音訊特性。 在非常短或非常安靜的片段中,SenseVoice 有時會無視所選語言而輸出中文。手動設定語言(而非「自動」)可以減少這種情況。
• 不支援串流處理。 與 Whisper 的串流模式不同,SenseVoice 在錄音結束後處理完整音訊。對於長檔案,它會在靜音處自動分段,逐步顯示結果。
這些是架構層面的限制,不是 bug。一個用 5 種語言訓練的模型,把這 5 種語言做到了極致。Whisper 的 99+ 語言支援意味著更慢的速度和更高的單語言錯誤率。
試試看
SenseVoice 已在 Mac 版 Whisper Notes v1.4.8 及更高版本中提供。前往 設定 → 轉寫模型 → SenseVoice Small(約 827 MB)下載。需要 Apple Silicon Mac(M1 或更新)。
如果你正在使用 Parakeet V3 且主要用英語聽寫,無需切換。SenseVoice 適用於當你需要中文、日語、韓語或粵語——並且希望快速完成。
完整更新日誌:whispernotes.app/changelog
問題或回饋:mac@whispernotes.app