TL;DR -- Tres models de Mac comparats
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min angles | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| 27 min xines | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| Idiomes | 25 (europeus) | 5 (zh, en, ja, ko, yue) | 99+ |
| Descàrrega | 465 MB | 827 MB | 1.5 GB |
| Memòria | ~800 MB | ~700 MB | ~1.6 GB |
| Millor per a | Anglès & europeus | Xinès, japonès, coreà, cantonès | Tot la resta (99+ idiomes) |
* Proves de velocitat a Apple M4 Pro, 32 GB. Podcast de 5 minuts en anglès i podcast de 27 minuts en xinès. Factor de temps real = durada de l'àudio / temps de processament (més alt = més ràpid). SenseVoice és només per a macOS. iOS utilitza Parakeet (via ANE) i Whisper.
A partir de la versió 1.4.8, Whisper Notes per a Mac inclou SenseVoice Small com a motor dedicat per a la transcripció en xinès, japonès, coreà i cantonès. Substitueix Qwen3-ASR i funciona a la GPU d'Apple via MLX en lloc de la CPU -- processant un podcast xinès de 27 minuts en 13,83 segons en lloc de 3 minuts i 44 segons.
Per què hem substituït Qwen3-ASR
Qwen3-ASR era un model sòlid. Suportava 30 idiomes més 22 dialectes xinesos, i la seva precisió per al xinès era propera a l'estat de l'art. Però tenia un problema que empitjorava com més llarg era l'àudio: la velocitat.
Qwen3 utilitzava una arquitectura autoregressiva -- el mateix enfocament que Whisper, processant l'àudio fotograma a fotograma, sense saltar mai endavant. En un podcast xinès de 27 minuts, trigava 73 segons. Utilitzable, però no l'experiència de resultat instantani que Parakeet V3 ofereix per a l'anglès.
El problema més profund era la nostra infraestructura. La nostra integració de Qwen3 utilitzava sherpa-onnx, una biblioteca en C amb un wrapper de Swift de 2.249 línies que dirigia tot a través dels nuclis de la CPU. La GPU estava ociosa mentre la CPU del teu Mac feia tota la feina.
SenseVoice va resoldre ambdós problemes. Arquitectura no autoregressiva per a la velocitat. Apple MLX per a l'acceleració de GPU. El resultat: una millora de velocitat de 16,2× al mateix maquinari, amb una base de codi reduïda de 2.249 línies a 288.
El benchmark
Els tres models funcionant al mateix Apple M4 Pro, els mateixos fitxers d'àudio, les mateixes condicions. Sense núvol. Sense internet. Només silici.
| Model | 5 min anglès | 27 min xinès | Velocitat (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103--161× |
| SenseVoice Small | 5.8s | 13.83s | 52--118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13--14× |
| Qwen3-ASR (eliminat) | -- | 73s | 4.7× |
SenseVoice és aproximadament la meitat de ràpid que Parakeet V3 -- tot i així extraordinàriament ràpid. Un podcast de 27 minuts es completa en menys de 14 segons. Prems transcriure, esperes un alè, i el text ja hi és.
Compara-ho amb Whisper a 2 minuts i 4 segons, o l'antic Qwen3 a 73 segons. L'arquitectura importa més que el nombre de paràmetres.
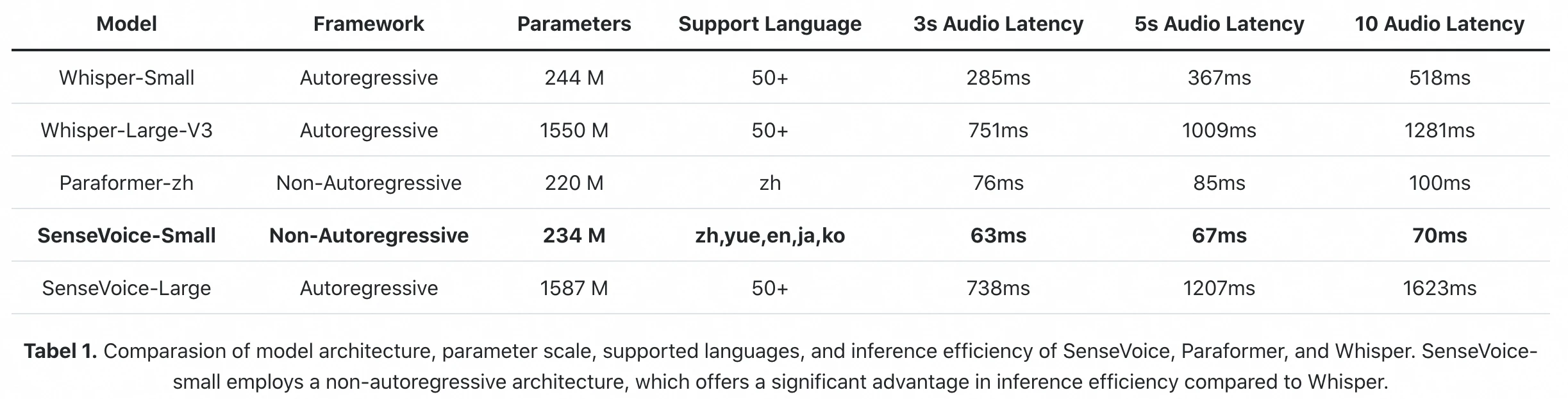
Benchmark oficial d'inferència de l'article FunAudioLLM: SenseVoice-Small processa 10s d'àudio en 70ms (A800 GPU). Whisper-Large-V3 triga 1.281ms. Això és una diferència de 18× en latència bruta d'inferència.
| Model | Temps de càrrega | Memòria | Mida de descàrrega |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* Temps de càrrega i memòria mesurats a Apple M4 Pro, 32 GB.
SenseVoice es carrega en menys d'un segon i utilitza menys memòria que Parakeet. En un Mac de 8 GB, funciona còmodament juntament amb les teves altres aplicacions.
Per què SenseVoice és més ràpid: Arquitectura + Entorn d'execució
La diferència de velocitat entre Qwen3-ASR i SenseVoice prové de dos factors independents.
Factor 1: Arquitectura del model. Qwen3-ASR és autoregressiu -- genera text token a token, cada un dependent de l'anterior. SenseVoice utilitza un codificador no autoregressiu (NAR) que processa tot l'àudio en paral·lel. Aquesta diferència arquitectònica sola fa que SenseVoice sigui fonamentalment més ràpid, independentment del maquinari que utilitzis.
Factor 2: Entorn d'execució. La nostra integració de Qwen3-ASR utilitzava sherpa-onnx, que funcionava a la CPU. SenseVoice funciona a través d'Apple MLX, dirigint els càlculs a la GPU. Podria Qwen3 també funcionar amb MLX? Sí -- però seguiria sent més lent que SenseVoice perquè el coll d'ampolla autoregressiu és a l'arquitectura, no a l'entorn d'execució.
| Qwen3-ASR (antic) | SenseVoice (nou) | |
|---|---|---|
| Arquitectura | Autoregressiva (token a token) | No autoregressiva (paral·lela) |
| Entorn d'execució | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min xinès | 224 segons | 13,83 segons |
| Acceleració combinada | línia base | 16,2× més ràpid |
| Base de codi | 168 MB framework C + 2.249 línies Swift | 288 línies Swift Actor |
* Mateix podcast xinès de 27 minuts, Apple M4 Pro. L'acceleració de 16,2× combina millores tant arquitectòniques (NAR vs AR) com d'entorn d'execució (GPU vs CPU).
El codi també es va simplificar. La nova implementació de SenseVoice és un únic Swift Actor de 288 línies que es comunica directament amb MLX, substituint un framework C de 168 MB. Menys codi, menys errors, aplicació més petita.
Cinc idiomes, ben fets
SenseVoice no intenta fer-ho tot. Gestiona cinc idiomes:
| Idioma | SenseVoice-Small | Whisper-Large-V3 | Guanyador |
|---|---|---|---|
| Xinès (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| Cantonès (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| Japonès (ja) | 11.96% CER | 10.34% CER | Whisper (lleuger) |
| Coreà (ko) | 8.28% CER | 5.59% CER | Whisper |
| Anglès (en) | 14.71% WER | 9.39% WER | Whisper (utilitza Parakeet) |
* Benchmark CommonVoice, CER = Character Error Rate, WER = Word Error Rate. Més baix és millor. Font: article FunAudioLLM (2024). Latència d'inferència de SenseVoice-Small: 70ms per 10s d'àudio (A800 GPU), més de 15× més ràpid que Whisper-Large-V3.
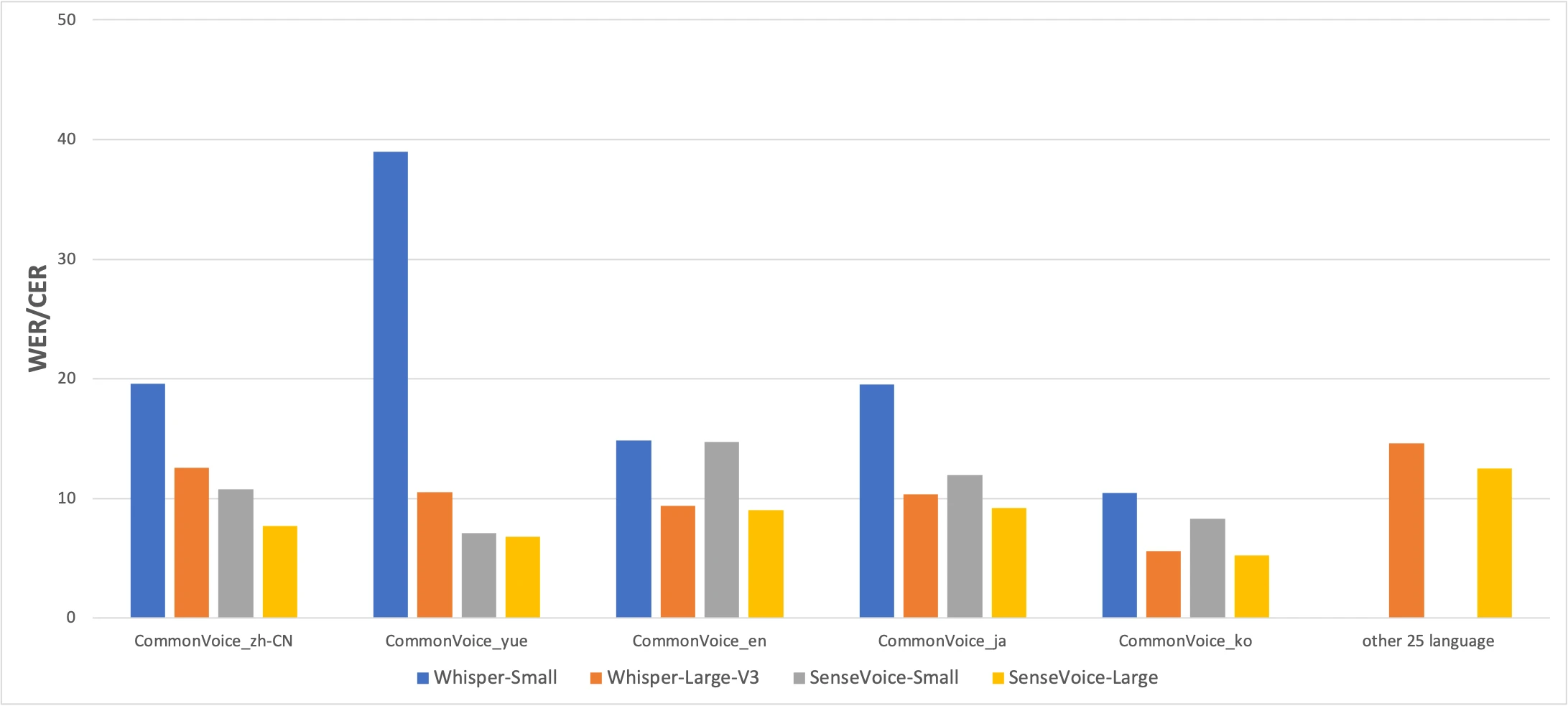
Benchmark CommonVoice: SenseVoice-Small (groc) vs Whisper-Small (blau) vs Whisper-Large-V3 (taronja). Més baix és millor. Font: article FunAudioLLM
Els números expliquen una història honesta. SenseVoice supera Whisper en precisió per al xinès i cantonès amb un marge significatiu, mentre que Whisper és més precís per al japonès, coreà i anglès. Però SenseVoice és més de 15× més ràpid que Whisper-Large-V3. Per a la majoria d'usos reals, la diferència de velocitat importa més que uns quants punts percentuals de precisió.
El resultat del cantonès mereix ser destacat per separat. Whisper-Small obté un 38,97% de CER en cantonès -- gairebé inutilitzable. Fins i tot Whisper-Large-V3 només aconsegueix un 10,41%. SenseVoice arriba al 7,09%. Abans de SenseVoice, no hi havia una bona manera de transcriure cantonès localment en un Mac. Si parles cantonès, aquest model existeix per a tu.
Transcripció coreana amb SenseVoice: importació de vídeo amb subtítols amb marques de temps
Prova real: podcast xinès de 27 minuts
Vam transcriure un episodi de 27 minuts de Thirteen Invitations (十三邀), un podcast d'entrevistes xinès, amb SenseVoice i Whisper Large V3 Turbo al mateix M4 Pro. ElevenLabs Scribe (núvol) va servir com a referència. Ambdós models locals fan aproximadament el mateix nombre d'errors, però de tipus diferents:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Temps | 13.83s | 2 min 4s |
| Errors (mostra de 5 min) | ~15--20 | ~12--15 |
| Pitjor error | 时差→食堂 (zona horària→menjador) | 西昌→西藏 (ciutat de Xichang→Tibet, 4.000 km de diferència) |
| Patró d'errors | Intercanvis d'homòfons | Errors geogràfics/factuals |
* Comparació manual contra ElevenLabs Scribe (referència al núvol, també imperfecta). Ambdós models locals van escriure correctament "根深蒂固" on Scribe es va equivocar.
Precisió comparable. 9× més ràpid. Per a la transcripció de xinès al món real, SenseVoice et dóna un transcrit utilitzable abans que Whisper acabi de carregar.
Quan utilitzar quin model
Whisper Notes per a Mac ara inclou quatre models de veu. Cadascun està optimitzat per a escenaris diferents:
| Necessites... | Utilitza aquest model | Per què |
|---|---|---|
| Anglès o idiomes europeus, velocitat màxima | Parakeet V3 | 103× temps real, menor taxa d'error. Per defecte. |
| Xinès, japonès, coreà o cantonès | SenseVoice Small | 52--118× temps real. Únic model amb suport per a cantonès. |
| Qualsevol dels 99+ idiomes (àrab, tailandès, rus, etc.) | Whisper Large V3 Turbo | Suport d'idiomes més ampli. Més lent però universal. |
| Menor ús de memòria (Macs més antics) | Whisper Small | 487 MB de memòria. Bo per a Macs de 8 GB amb altres aplicacions. |
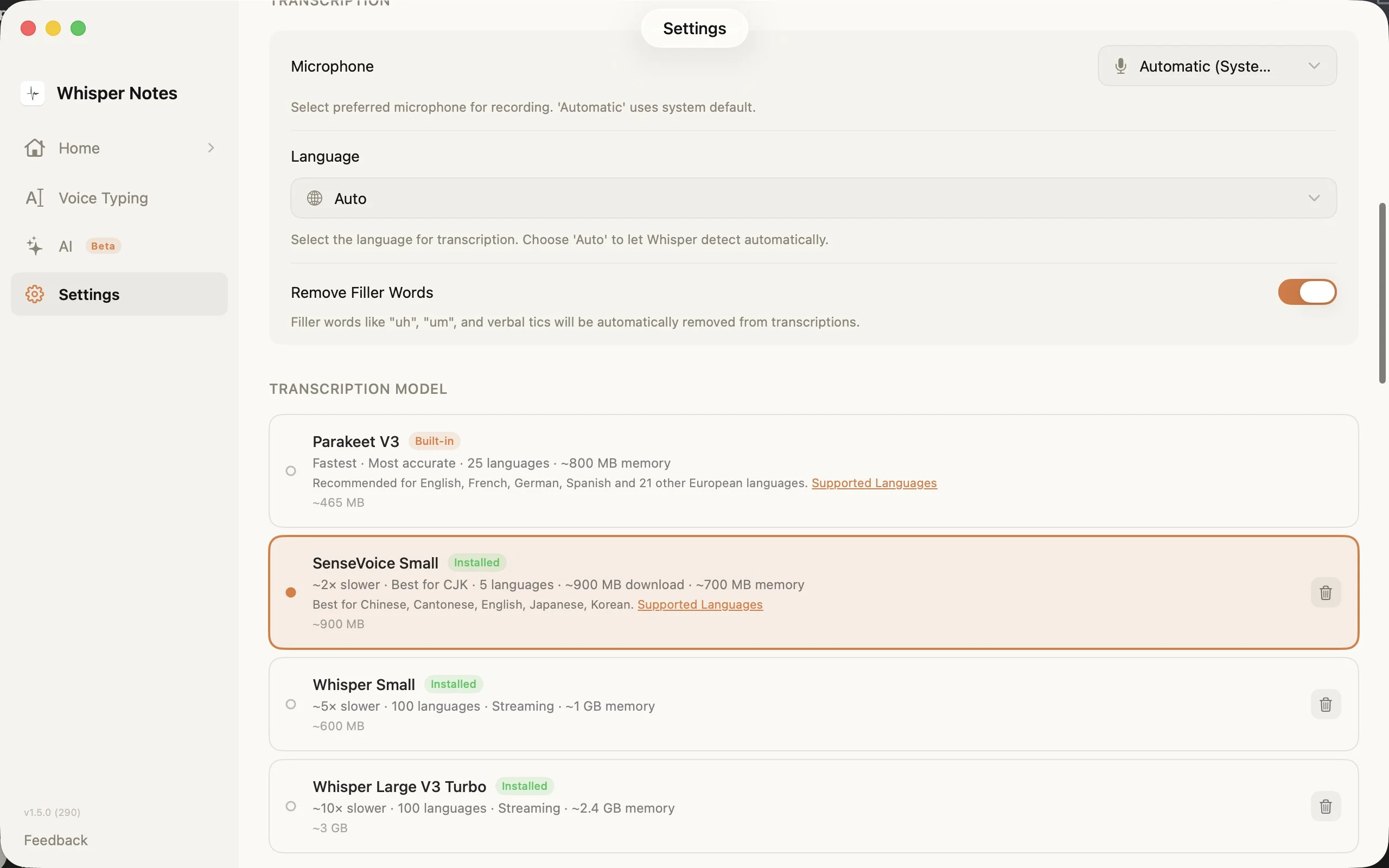
Configuració → Model de transcripció: tria el motor adequat per al teu idioma
El selector de models a Configuració mostra les quatre opcions amb mides de descàrrega, nombre d'idiomes i requisits de memòria. SenseVoice es descarrega al primer ús (~827 MB) i es queda al teu dispositiu.
Els compromisos
SenseVoice no és un model universal. Això és el que no pot fer:
* Només 5 idiomes. Si necessites tailandès, rus, àrab, hindi o qualsevol dels altres 90+ idiomes que suporta Whisper, queda't amb Whisper.
* Només Mac. SenseVoice funciona via Apple MLX, que requereix macOS. No està disponible a l'iPhone. Els usuaris d'iOS tenen Parakeet (per a idiomes europeus) i Whisper.
* Peculiaritat amb àudio silenciós. Durant segments molt curts o molt silenciosos, SenseVoice pot tornar a sortida en xinès independentment de l'idioma seleccionat. Establir l'idioma manualment (en lloc d'"Auto") redueix això.
* Sense streaming. A diferència del mode de streaming de Whisper, SenseVoice processa l'àudio complet després de la gravació. Per a fitxers llargs, segmenta automàticament als punts de silenci i mostra resultats progressivament.
Aquestes són restriccions arquitectòniques, no errors. Un model entrenat en 5 idiomes fa aquests 5 idiomes extremadament bé. El suport de 99+ idiomes de Whisper ve amb velocitat més lenta i taxes d'error més altes per a cada idioma individual.
Prova'l
SenseVoice està disponible a Whisper Notes per a Mac v1.4.8 i posteriors. Descarrega'l des de Configuració → Model de transcripció → SenseVoice Small (~827 MB). Requereix un Mac amb Apple Silicon (M1 o posterior).
Si estàs amb Parakeet V3 i dictes principalment en anglès, no cal canviar. SenseVoice és per quan necessites xinès, japonès, coreà o cantonès -- i el vols ràpid.
Registre de canvis complet: whispernotes.app/changelog
Preguntes o comentaris: mac@whispernotes.app