TL;DR -- Trois modeles Mac compares
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min anglais | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 min chinois | 10,10s (161×) | 13,83s (118×) | 2 min 4s (13,1×) |
| Langues | 25 (europeennes) | 5 (zh, en, ja, ko, yue) | 99+ |
| Telechargement | 465 MB | 827 MB | 1,5 GB |
| Memoire | ~800 MB | ~700 MB | ~1,6 GB |
| Ideal pour | Anglais & europeens | Chinois, japonais, coreen, cantonais | Tout le reste (99+ langues) |
* Benchmarks de vitesse sur Apple M4 Pro, 32 Go. Podcast de 5 minutes en anglais et podcast de 27 minutes en chinois. Facteur temps reel = duree audio / temps de traitement (plus eleve = plus rapide). SenseVoice est uniquement pour macOS. iOS utilise Parakeet (via ANE) et Whisper.
A partir de la version 1.4.8, Whisper Notes pour Mac integre SenseVoice Small comme moteur dedie a la transcription en chinois, japonais, coreen et cantonais. Il remplace Qwen3-ASR et tourne sur le GPU d'Apple via MLX au lieu du CPU -- traitant un podcast chinois de 27 minutes en 13,83 secondes au lieu de 3 minutes et 44 secondes.
Pourquoi nous avons remplace Qwen3-ASR
Qwen3-ASR etait un modele solide. Il prenait en charge 30 langues plus 22 dialectes chinois, et sa precision pour le chinois etait proche de l'etat de l'art. Mais il avait un probleme qui empirait avec la duree de l'audio : la vitesse.
Qwen3 utilisait une architecture autoregressive -- la meme approche que Whisper, traitant l'audio image par image, sans jamais sauter en avant. Sur un podcast chinois de 27 minutes, cela prenait 73 secondes. Utilisable, mais pas l'experience de resultat instantane que Parakeet V3 offre pour l'anglais.
Le probleme plus profond etait notre infrastructure. Notre integration de Qwen3 utilisait sherpa-onnx, une bibliotheque C avec un wrapper Swift de 2 249 lignes qui acheminait tout via les coeurs du CPU. Le GPU restait inactif pendant que le CPU de votre Mac faisait tout le travail.
SenseVoice a resolu les deux problemes. Architecture non autoregressive pour la vitesse. Apple MLX pour l'acceleration GPU. Le resultat : une amelioration de vitesse de 16,2× sur le meme materiel, avec une base de code reduite de 2 249 lignes a 288.
Le benchmark
Les trois modeles tournant sur le meme Apple M4 Pro, les memes fichiers audio, les memes conditions. Pas de cloud. Pas d'internet. Juste du silicium.
| Modele | 5 min anglais | 27 min chinois | Vitesse (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103--161× |
| SenseVoice Small | 5,8s | 13,83s | 52--118× |
| Whisper Large V3 Turbo | 20,92s | 2 min 4s | 13--14× |
| Qwen3-ASR (supprime) | -- | 73s | 4,7× |
SenseVoice est environ deux fois moins rapide que Parakeet V3 -- mais reste extraordinairement rapide. Un podcast de 27 minutes est termine en moins de 14 secondes. Vous appuyez sur transcrire, vous prenez une respiration, et le texte est la.
Comparez cela a Whisper a 2 minutes et 4 secondes, ou l'ancien Qwen3 a 73 secondes. L'architecture compte plus que le nombre de parametres.
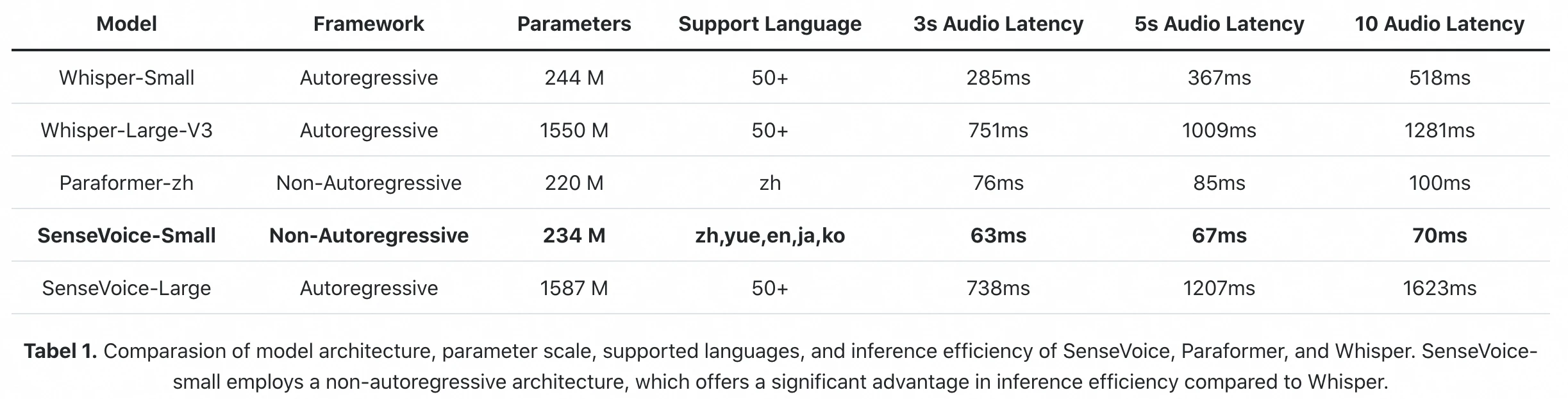
Benchmark officiel d'inference du papier FunAudioLLM : SenseVoice-Small traite 10s d'audio en 70ms (A800 GPU). Whisper-Large-V3 prend 1 281ms. C'est une difference de 18× en latence brute d'inference.
| Modele | Temps de chargement | Memoire | Taille de telechargement |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81s | ~700 MB | 827 MB |
| Whisper Small | 1,03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18s | ~1,6 Go | 3 Go |
* Temps de chargement et memoire mesures sur Apple M4 Pro, 32 Go.
SenseVoice se charge en moins d'une seconde et utilise moins de memoire que Parakeet. Sur un Mac 8 Go, il tourne confortablement a cote de vos autres applications.
Pourquoi SenseVoice est plus rapide : Architecture + Runtime
L'ecart de vitesse entre Qwen3-ASR et SenseVoice provient de deux facteurs independants.
Facteur 1 : Architecture du modele. Qwen3-ASR est autoregressif -- il genere du texte jeton par jeton, chacun dependant du precedent. SenseVoice utilise un encodeur non autoregressif (NAR) qui traite l'ensemble de l'audio en parallele. Cette difference architecturale seule rend SenseVoice fondamentalement plus rapide, quel que soit le materiel utilise.
Facteur 2 : Runtime. Notre integration de Qwen3-ASR utilisait sherpa-onnx, qui tournait sur le CPU. SenseVoice tourne via Apple MLX, dirigeant le calcul vers le GPU. Qwen3 pourrait-il aussi tourner sur MLX ? Oui -- mais il serait toujours plus lent que SenseVoice parce que le goulot d'etranglement autoregressif est dans l'architecture, pas dans le runtime.
| Qwen3-ASR (ancien) | SenseVoice (nouveau) | |
|---|---|---|
| Architecture | Autoregressive (jeton par jeton) | Non autoregressive (parallele) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min chinois | 224 secondes | 13,83 secondes |
| Acceleration combinee | ligne de base | 16,2× plus rapide |
| Base de code | Framework C de 168 Mo + 2 249 lignes Swift | 288 lignes Swift Actor |
* Meme podcast chinois de 27 minutes, Apple M4 Pro. L'acceleration de 16,2× combine les ameliorations architecturales (NAR vs AR) et de runtime (GPU vs CPU).
Le code est devenu plus simple aussi. La nouvelle implementation de SenseVoice est un seul Swift Actor de 288 lignes qui communique directement avec MLX, remplacant un framework C de 168 Mo. Moins de code, moins de bugs, application plus petite.
Cinq langues, bien faites
SenseVoice n'essaie pas de tout faire. Il gere cinq langues :
| Langue | SenseVoice-Small | Whisper-Large-V3 | Gagnant |
|---|---|---|---|
| Chinois (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Cantonais (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japonais (ja) | 11,96% CER | 10,34% CER | Whisper (leger) |
| Coreen (ko) | 8,28% CER | 5,59% CER | Whisper |
| Anglais (en) | 14,71% WER | 9,39% WER | Whisper (utilisez Parakeet) |
* Benchmark CommonVoice, CER = Character Error Rate, WER = Word Error Rate. Plus bas est mieux. Source : papier FunAudioLLM (2024). Latence d'inference de SenseVoice-Small : 70ms pour 10s d'audio (A800 GPU), plus de 15× plus rapide que Whisper-Large-V3.
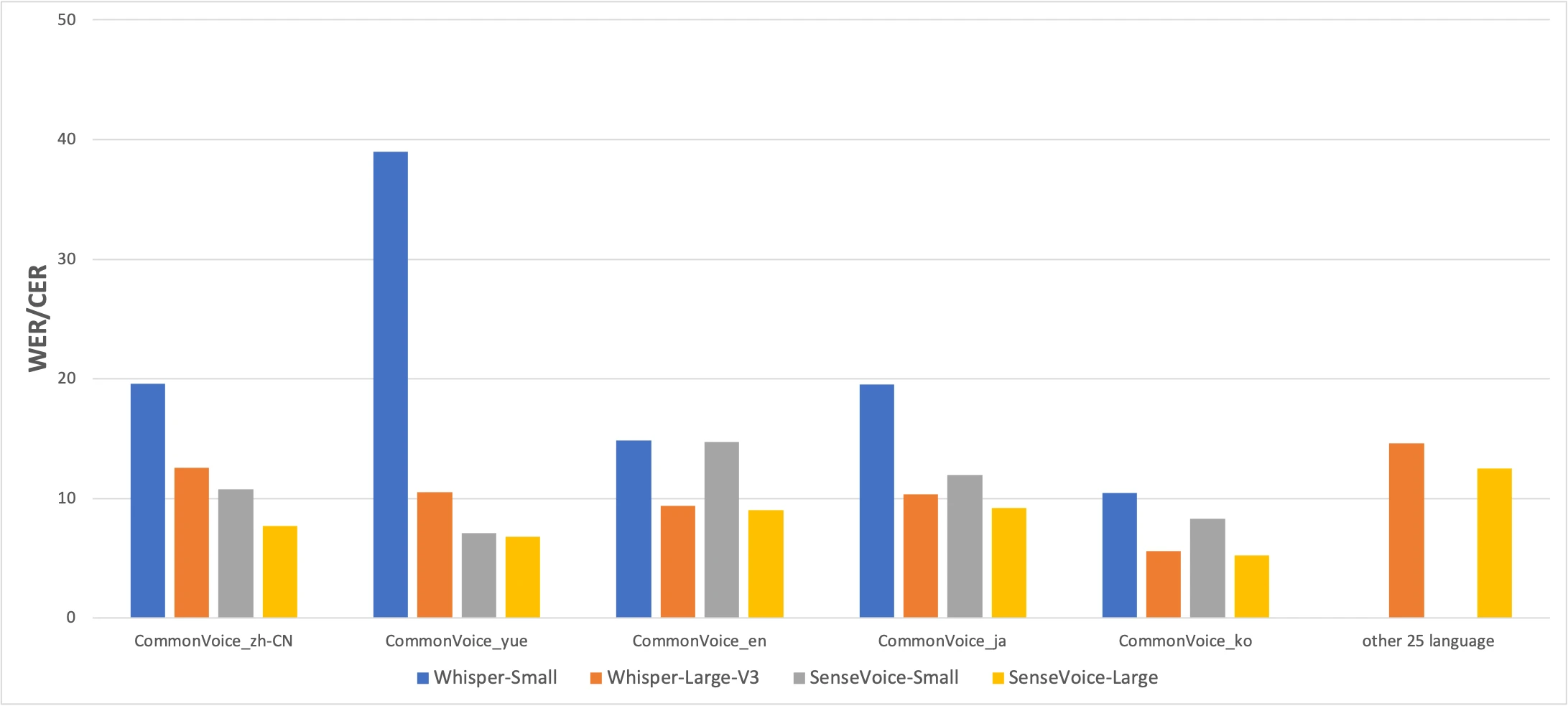
Benchmark CommonVoice : SenseVoice-Small (jaune) vs Whisper-Small (bleu) vs Whisper-Large-V3 (orange). Plus bas est mieux. Source : papier FunAudioLLM
Les chiffres racontent une histoire honnete. SenseVoice bat Whisper en precision pour le chinois et le cantonais avec une marge significative, tandis que Whisper est plus precis pour le japonais, le coreen et l'anglais. Mais SenseVoice est plus de 15× plus rapide que Whisper-Large-V3. Pour la plupart des usages reels, la difference de vitesse compte plus que quelques points de pourcentage de precision.
Le resultat pour le cantonais merite d'etre souligne separement. Whisper-Small obtient 38,97% de CER en cantonais -- quasiment inutilisable. Meme Whisper-Large-V3 n'atteint que 10,41%. SenseVoice atteint 7,09%. Avant SenseVoice, il n'existait pas de bonne facon de transcrire le cantonais localement sur un Mac. Si vous parlez cantonais, ce modele existe pour vous.
Transcription coreenne avec SenseVoice : importation de video avec sous-titres horodates
Test reel : podcast chinois de 27 minutes
Nous avons transcrit un episode de 27 minutes de Thirteen Invitations (十三邀), un podcast d'interviews chinois, avec SenseVoice et Whisper Large V3 Turbo sur le meme M4 Pro. ElevenLabs Scribe (cloud) a servi de reference. Les deux modeles locaux font a peu pres le meme nombre d'erreurs, mais de types differents :
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Temps | 13,83s | 2 min 4s |
| Erreurs (echantillon 5 min) | ~15--20 | ~12--15 |
| Pire erreur | 时差→食堂 (fuseau horaire→cantine) | 西昌→西藏 (ville de Xichang→Tibet, 4 000 km d'ecart) |
| Type d'erreurs | Substitutions d'homophones | Erreurs geographiques/factuelles |
* Comparaison manuelle contre ElevenLabs Scribe (reference cloud, egalement imparfaite). Les deux modeles locaux ont correctement ecrit "根深蒂固" la ou Scribe s'est trompe.
Precision comparable. 9× plus rapide. Pour la transcription de chinois dans le monde reel, SenseVoice vous donne un transcrit utilisable avant que Whisper ait fini de charger.
Quand utiliser quel modele
Whisper Notes pour Mac integre desormais quatre modeles vocaux. Chacun est optimise pour des scenarios differents :
| Vous avez besoin de... | Utilisez ce modele | Pourquoi |
|---|---|---|
| Anglais ou langues europeennes, vitesse maximale | Parakeet V3 | 103× temps reel, taux d'erreur le plus bas. Par defaut. |
| Chinois, japonais, coreen ou cantonais | SenseVoice Small | 52--118× temps reel. Seul modele avec support du cantonais. |
| N'importe laquelle des 99+ langues (arabe, thai, russe, etc.) | Whisper Large V3 Turbo | Support linguistique le plus large. Plus lent mais universel. |
| Utilisation memoire reduite (anciens Mac) | Whisper Small | 487 Mo de memoire. Bon pour les Mac 8 Go avec d'autres apps. |
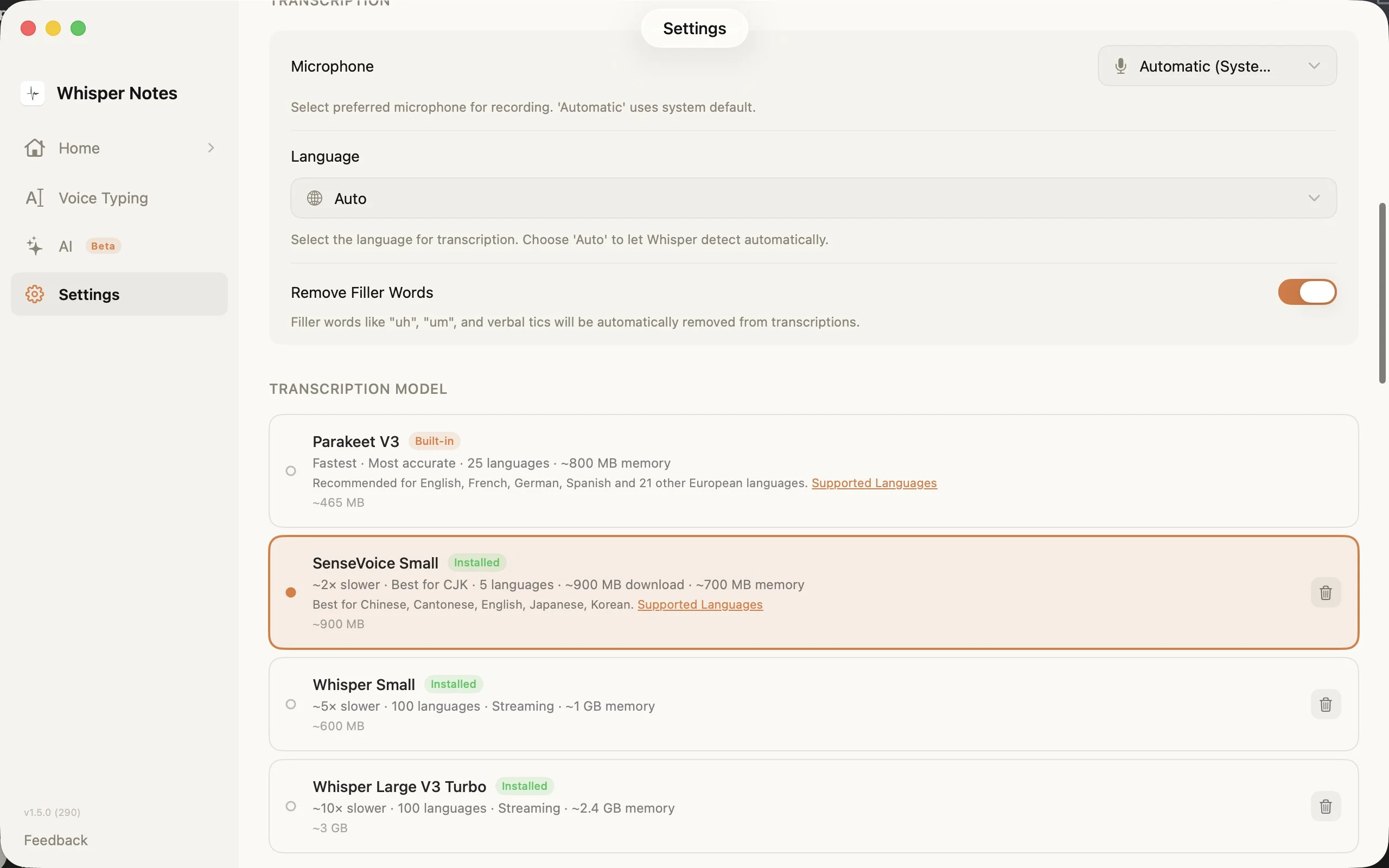
Reglages → Modele de transcription : choisissez le bon moteur pour votre langue
Le selecteur de modeles dans les Reglages affiche les quatre options avec les tailles de telechargement, le nombre de langues et les exigences en memoire. SenseVoice se telecharge a la premiere utilisation (~827 Mo) et reste sur votre appareil.
Les compromis
SenseVoice n'est pas un modele universel. Voici ce qu'il ne peut pas faire :
* Seulement 5 langues. Si vous avez besoin du thai, du russe, de l'arabe, de l'hindi ou de l'une des 90+ autres langues que Whisper prend en charge, restez avec Whisper.
* Mac uniquement. SenseVoice fonctionne via Apple MLX, qui necessite macOS. Il n'est pas disponible sur iPhone. Les utilisateurs iOS disposent de Parakeet (pour les langues europeennes) et Whisper.
* Particularite avec l'audio silencieux. Pendant les segments tres courts ou tres silencieux, SenseVoice peut parfois revenir a une sortie en chinois quelle que soit la langue selectionnee. Definir la langue manuellement (au lieu de "Auto") reduit ce comportement.
* Pas de streaming. Contrairement au mode streaming de Whisper, SenseVoice traite l'audio complet apres l'enregistrement. Pour les fichiers longs, il segmente automatiquement aux points de silence et affiche les resultats progressivement.
Ce sont des contraintes architecturales, pas des bugs. Un modele entraine sur 5 langues fait ces 5 langues extremement bien. Le support de 99+ langues de Whisper s'accompagne d'une vitesse plus lente et de taux d'erreur plus eleves pour chaque langue individuelle.
Essayez-le
SenseVoice est disponible dans Whisper Notes pour Mac v1.4.8 et ulterieur. Telechargez-le depuis Reglages → Modele de transcription → SenseVoice Small (~827 Mo). Un Mac Apple Silicon (M1 ou ulterieur) est requis.
Si vous utilisez Parakeet V3 et dictez principalement en anglais, il n'est pas necessaire de changer. SenseVoice est pour quand vous avez besoin du chinois, japonais, coreen ou cantonais -- et que vous le voulez rapidement.
Journal des modifications complet : whispernotes.app/changelog
Questions ou commentaires : mac@whispernotes.app