TL;DR — Three Mac Models Compared
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min English | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| 27 min Chinese | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| Languages | 25 (European) | 5 (zh, en, ja, ko, yue) | 99+ |
| Download | 465 MB | 827 MB | 1.5 GB |
| Memory | ~800 MB | ~700 MB | ~1.6 GB |
| Best for | English & European | Chinese, Japanese, Korean, Cantonese | Everything else (99+ languages) |
* Speed benchmarks on Apple M4 Pro, 32 GB. 5-minute English podcast and 27-minute Chinese podcast. Realtime factor = audio duration ÷ processing time (higher = faster). SenseVoice is macOS only. iOS uses Parakeet (via ANE) and Whisper.
Starting with version 1.4.8, Whisper Notes for Mac ships SenseVoice Small as the dedicated engine for Chinese, Japanese, Korean, and Cantonese transcription. It replaces Qwen3-ASR and runs on Apple's GPU via MLX instead of CPU — processing a 27-minute Chinese podcast in 13.83 seconds instead of 3 minutes and 44 seconds.
Why We Replaced Qwen3-ASR
Qwen3-ASR was a solid model. It supported 30 languages plus 22 Chinese dialects, and its Chinese accuracy was near state-of-the-art. But it had a problem that got worse the longer the audio: speed.
Qwen3 used an autoregressive architecture — same approach as Whisper, processing audio frame by frame, never skipping ahead. On a 27-minute Chinese podcast, it took 73 seconds. Usable, but not the instant-result experience that Parakeet V3 delivers for English.
The deeper issue was our infrastructure. Our Qwen3 integration used sherpa-onnx, a C library with a 2,249-line Swift wrapper that routed everything through CPU cores. The GPU sat idle while your Mac's CPU did all the work.
SenseVoice fixed both problems. Non-autoregressive architecture for speed. Apple MLX for GPU acceleration. The result: a 16.2× speed improvement on the same hardware, with a codebase reduced from 2,249 lines to 288.
The Benchmark
All three models running on the same Apple M4 Pro, same audio files, same conditions. No cloud. No internet. Just silicon.
| Model | 5 min English | 27 min Chinese | Speed (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103–161× |
| SenseVoice Small | 5.8s | 13.83s | 52–118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13–14× |
| Qwen3-ASR (removed) | — | 73s | 4.7× |
SenseVoice is roughly half the speed of Parakeet V3 — still extraordinarily fast. A 27-minute podcast finishes in under 14 seconds. You press transcribe, you wait one breath, and the text is there.
Compare that to Whisper at 2 minutes and 4 seconds, or the old Qwen3 at 73 seconds. The architecture matters more than the parameter count.
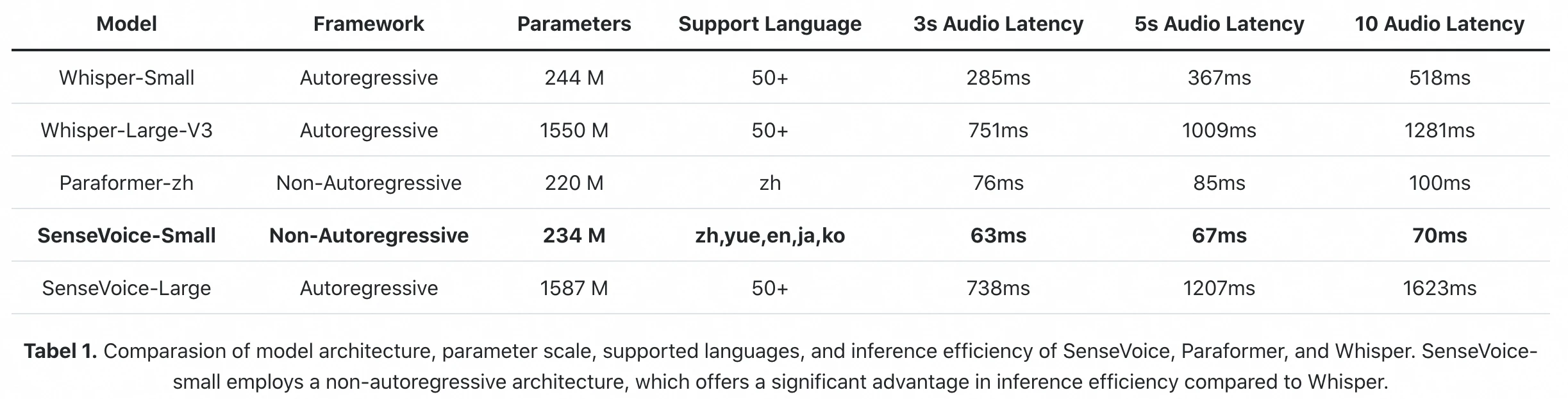
Official inference benchmark from the FunAudioLLM paper: SenseVoice-Small processes 10s of audio in 70ms (A800 GPU). Whisper-Large-V3 takes 1,281ms. That's an 18× difference in raw inference latency.
| Model | Load Time | Memory | Download Size |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* Load time and memory measured on Apple M4 Pro, 32 GB.
SenseVoice loads in under a second and uses less memory than Parakeet. On an 8 GB Mac, it runs comfortably alongside your other applications.
Why SenseVoice Is Faster: Architecture + Runtime
The speed gap between Qwen3-ASR and SenseVoice comes from two independent factors.
Factor 1: Model architecture. Qwen3-ASR is autoregressive — it generates text token by token, each depending on the previous one. SenseVoice uses a non-autoregressive (NAR) encoder that processes the entire audio in parallel. This architectural difference alone makes SenseVoice fundamentally faster, regardless of what hardware you run it on.
Factor 2: Runtime. Our Qwen3-ASR integration used sherpa-onnx, which ran on CPU. SenseVoice runs through Apple MLX, routing computation to the GPU. Could Qwen3 also run on MLX? Yes — but it would still be slower than SenseVoice because the autoregressive bottleneck is in the architecture, not the runtime.
| Qwen3-ASR (old) | SenseVoice (new) | |
|---|---|---|
| Architecture | Autoregressive (token by token) | Non-autoregressive (parallel) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min Chinese | 224 seconds | 13.83 seconds |
| Combined speedup | baseline | 16.2× faster |
| Codebase | 168 MB C framework + 2,249 lines Swift | 288 lines Swift Actor |
* Same 27-minute Chinese podcast, Apple M4 Pro. The 16.2× speedup combines both architectural (NAR vs AR) and runtime (GPU vs CPU) improvements.
The code got simpler too. The new SenseVoice implementation is a single 288-line Swift Actor that talks directly to MLX, replacing a 168 MB C framework. Less code, fewer bugs, smaller app.
Five Languages, Done Well
SenseVoice doesn't try to do everything. It handles five languages:
| Language | SenseVoice-Small | Whisper-Large-V3 | Winner |
|---|---|---|---|
| Chinese (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| Cantonese (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| Japanese (ja) | 11.96% CER | 10.34% CER | Whisper (slight) |
| Korean (ko) | 8.28% CER | 5.59% CER | Whisper |
| English (en) | 14.71% WER | 9.39% WER | Whisper (use Parakeet) |
* CommonVoice benchmark, CER = Character Error Rate, WER = Word Error Rate. Lower is better. Source: FunAudioLLM paper (2024). SenseVoice-Small inference latency: 70ms per 10s audio (A800 GPU), more than 15× faster than Whisper-Large-V3.
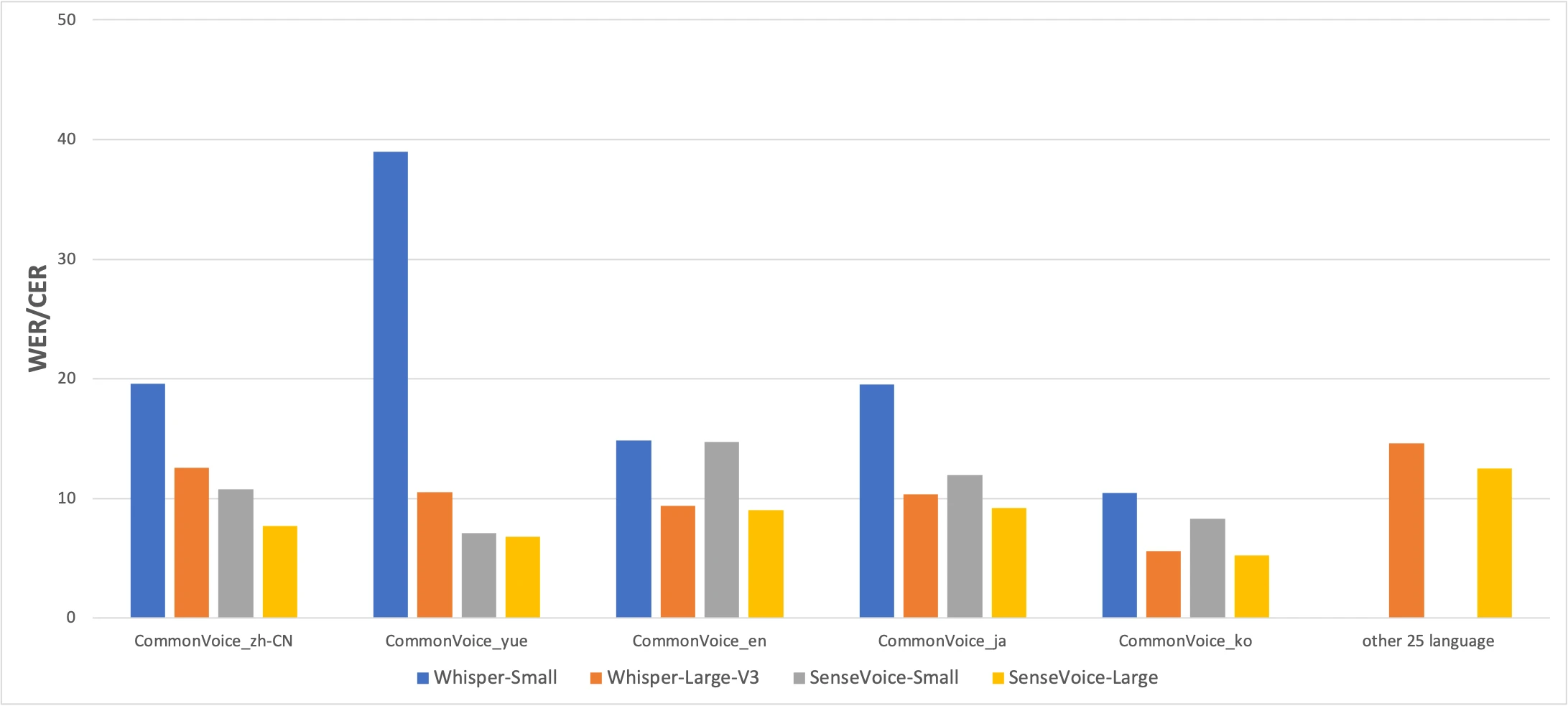
CommonVoice benchmark: SenseVoice-Small (yellow) vs Whisper-Small (blue) vs Whisper-Large-V3 (orange). Lower is better. Source: FunAudioLLM paper
The numbers tell an honest story. SenseVoice beats Whisper on Chinese and Cantonese accuracy by a significant margin, while Whisper is more accurate for Japanese, Korean, and English. But SenseVoice is more than 15× faster than Whisper-Large-V3. For most real-world use, the speed difference matters more than a few percentage points of accuracy.
The Cantonese result is worth highlighting separately. Whisper-Small scores 38.97% CER on Cantonese — nearly unusable. Even Whisper-Large-V3 only manages 10.41%. SenseVoice hits 7.09%. Before SenseVoice, there was no good way to transcribe Cantonese locally on a Mac. If you speak Cantonese, this model exists for you.
Korean transcription with SenseVoice: video import with timestamped subtitles
Real-World Test: 27-Minute Chinese Podcast
We transcribed a 27-minute episode of Thirteen Invitations (十三邀), a Chinese interview podcast, with both SenseVoice and Whisper Large V3 Turbo on the same M4 Pro. ElevenLabs Scribe (cloud) served as reference. Both on-device models make roughly the same number of errors, but different kinds:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Time | 13.83s | 2 min 4s |
| Errors (5 min sample) | ~15–20 | ~12–15 |
| Worst error | 时差→食堂 (timezone→cafeteria) | 西昌→西藏 (Xichang city→Tibet, 4,000 km off) |
| Error pattern | Homophone swaps | Geographic/factual errors |
* Manual comparison against ElevenLabs Scribe (cloud reference, also imperfect). Both on-device models correctly wrote "根深蒂固" where Scribe got it wrong.
Comparable accuracy. 9× faster. For real-world Chinese transcription, SenseVoice gets you a usable transcript before Whisper finishes loading.
When to Use Which Model
Whisper Notes for Mac now ships four speech models. Each is optimized for different scenarios:
| You need... | Use this model | Why |
|---|---|---|
| English or European languages, maximum speed | Parakeet V3 | 103× realtime, lowest error rate. The default. |
| Chinese, Japanese, Korean, or Cantonese | SenseVoice Small | 52–118× realtime. Only model with Cantonese support. |
| Any of 99+ languages (Arabic, Thai, Russian, etc.) | Whisper Large V3 Turbo | Broadest language support. Slower but universal. |
| Lower memory usage (older Macs) | Whisper Small | 487 MB memory. Good for 8 GB Macs running other apps. |
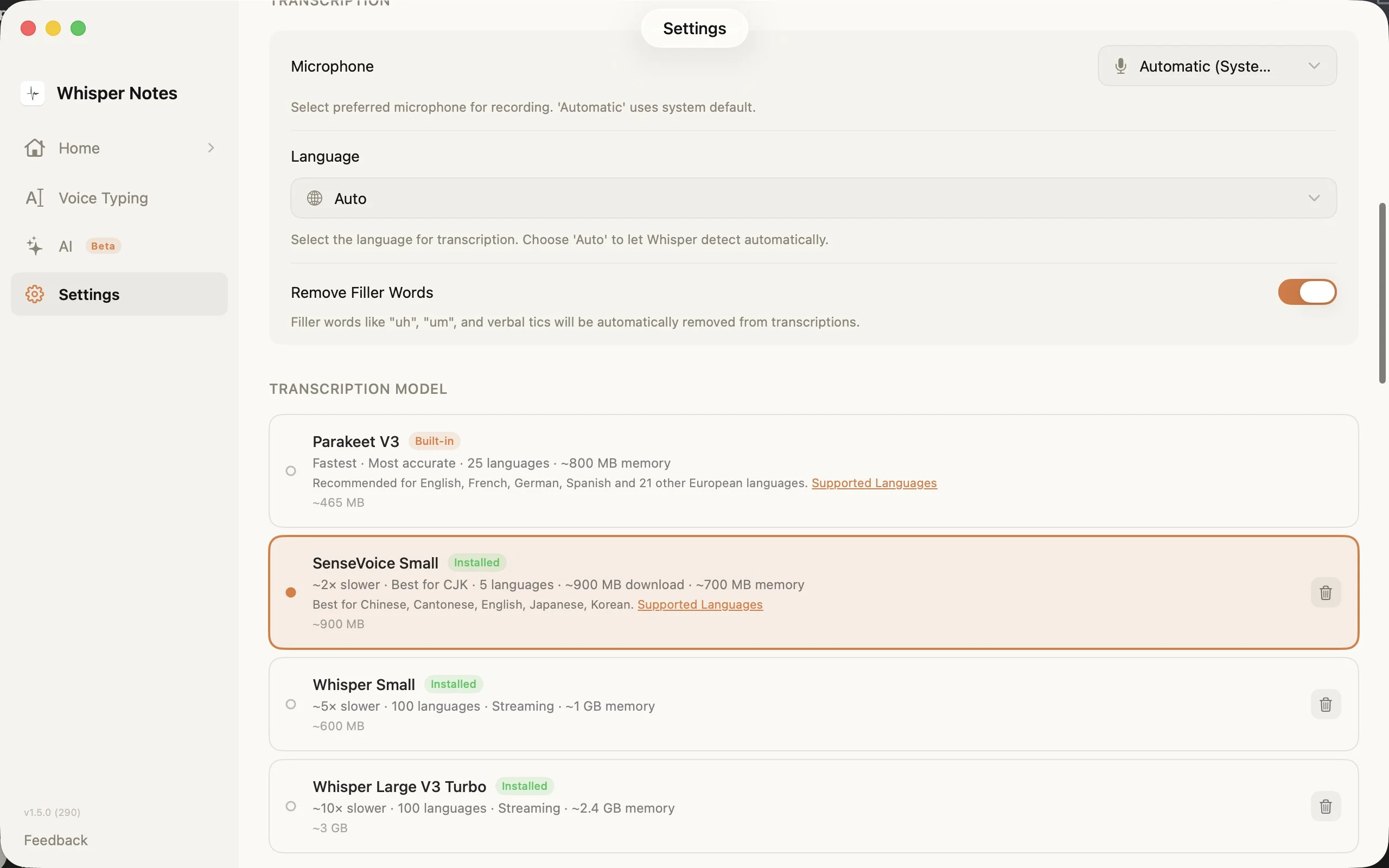
Settings → Transcription Model: choose the right engine for your language
The model picker in Settings shows all four options with download sizes, language counts, and memory requirements. SenseVoice downloads on first use (~827 MB) and stays on your device.
The Trade-offs
SenseVoice is not a universal model. Here's what it can't do:
• Only 5 languages. If you need Thai, Russian, Arabic, Hindi, or any of the other 90+ languages Whisper supports, stick with Whisper.
• Mac only. SenseVoice runs via Apple MLX, which requires macOS. It's not available on iPhone. iOS users have Parakeet (for European languages) and Whisper.
• Quiet audio quirk. During very short or very quiet segments, SenseVoice can sometimes fall back to Chinese output regardless of the selected language. Setting the language manually (instead of "Auto") reduces this.
• No streaming. Unlike Whisper's streaming mode, SenseVoice processes the full audio after recording. For long files, it auto-segments at silence points and shows results progressively.
These are architectural constraints, not bugs. A model trained on 5 languages does those 5 languages extremely well. Whisper's 99+ language support comes with slower speed and higher error rates on any individual language.
Try It
SenseVoice is available in Whisper Notes for Mac v1.4.8 and later. Download it from Settings → Transcription Model → SenseVoice Small (~827 MB). It requires an Apple Silicon Mac (M1 or later).
If you're on Parakeet V3 and dictate mostly in English, there's no need to switch. SenseVoice is for when you need Chinese, Japanese, Korean, or Cantonese — and you want it fast.
Full changelog: whispernotes.app/changelog
Questions or feedback: mac@whispernotes.app