SHRNUTÍ — Srovnání tří modelů pro Mac
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min angličtina | 2,91 s (103×) | 5,8 s (52×) | 20,92 s (14,3×) |
| 27 min čínština | 10,10 s (161×) | 13,83 s (118×) | 2 min 4 s (13,1×) |
| Jazyky | 25 (evropské) | 5 (zh, en, ja, ko, yue) | 99+ |
| Stažení | 465 MB | 827 MB | 1,5 GB |
| Paměť | ~800 MB | ~700 MB | ~1,6 GB |
| Nejlepší pro | Angličtinu & evropské jazyky | Čínštinu, japonštinu, korejštinu, kantonštinu | Vše ostatní (99+ jazyků) |
* Testy rychlosti na Apple M4 Pro, 32 GB. 5minutový anglický podcast a 27minutový čínský podcast. Faktor reálného času = délka audia ÷ doba zpracování (vyšší = rychlejší). SenseVoice je pouze pro macOS. iOS používá Parakeet (přes ANE) a Whisper.
Počínaje verzí 1.4.8 obsahuje Whisper Notes pro Mac model SenseVoice Small jako specializovaný engine pro přepis čínštiny, japonštiny, korejštiny a kantonštiny. Nahrazuje Qwen3-ASR a běží na GPU Apple přes MLX místo CPU — 27minutový čínský podcast zpracuje za 13,83 sekund místo 3 minut a 44 sekund.
Proč jsme nahradili Qwen3-ASR
Qwen3-ASR byl solidní model. Podporoval 30 jazyků plus 22 čínských dialektů a jeho přesnost v čínštině byla téměř na špičkové úrovni. Měl ale problém, který se zhoršoval s délkou audia: rychlost.
Qwen3 používal autoregresivní architekturu — stejný přístup jako Whisper, zpracovával audio snímek po snímku, nikdy nepřeskočil dopředu. Na 27minutovém čínském podcastu trval 73 sekund. Použitelné, ale ne ten zážitek okamžitého výsledku, který Parakeet V3 nabízí pro angličtinu.
Hlubší problém byla naše infrastruktura. Naše integrace Qwen3 používala sherpa-onnx, knihovnu v C s 2 249řádkovým Swift wrapperem, který vše směroval přes jádra CPU. GPU nečinně stálo, zatímco CPU vašeho Macu dělalo veškerou práci.
SenseVoice vyřešil oba problémy. Neautoregresivní architektura pro rychlost. Apple MLX pro akceleraci GPU. Výsledek: 16,2násobné zrychlení na stejném hardwaru, kódová základna se zmenšila z 2 249 řádků na 288.
Benchmark
Všechny tři modely běžely na stejném Apple M4 Pro, stejné audio soubory, stejné podmínky. Žádný cloud. Žádný internet. Jen křemík.
| Model | 5 min angličtina | 27 min čínština | Rychlost (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91 s | 10,10 s | 103–161× |
| SenseVoice Small | 5,8 s | 13,83 s | 52–118× |
| Whisper Large V3 Turbo | 20,92 s | 2 min 4 s | 13–14× |
| Qwen3-ASR (odstraněn) | — | 73 s | 4,7× |
SenseVoice je zhruba poloviční rychlostí oproti Parakeet V3 — přesto mimořádně rychlý. 27minutový podcast se dokončí za méně než 14 sekund. Stisknete přepis, počkáte jeden nádech a text je tam.
Srovnejte to s Whisperem za 2 minuty a 4 sekundy nebo starým Qwen3 za 73 sekund. Na architektuře záleží víc než na počtu parametrů.
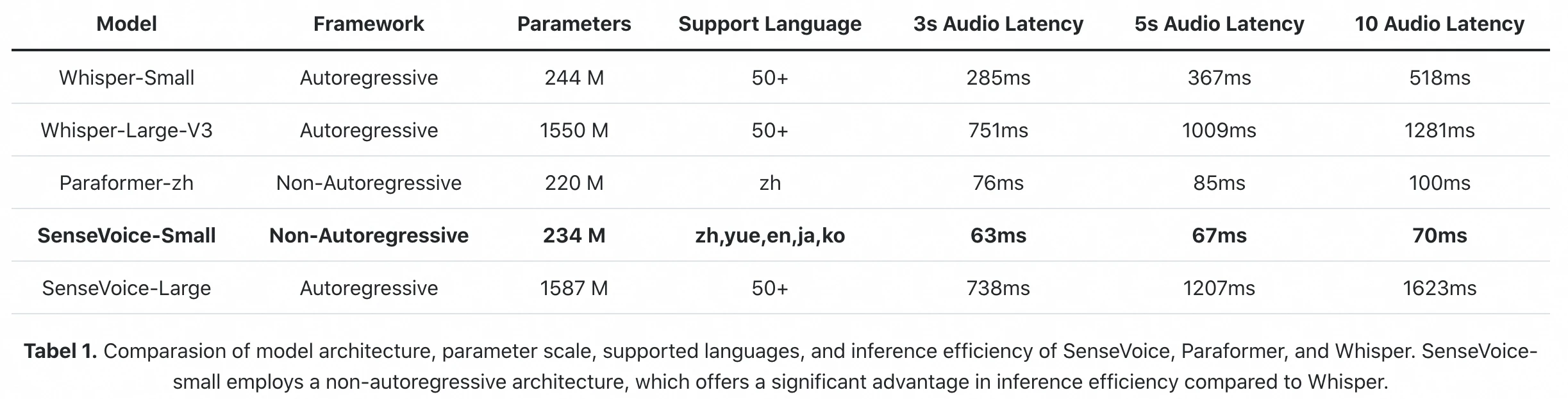
Oficiální benchmark inference z článku FunAudioLLM: SenseVoice-Small zpracuje 10 s audia za 70 ms (A800 GPU). Whisper-Large-V3 potřebuje 1 281 ms. To je 18násobný rozdíl v surové latenci inference.
| Model | Doba načtení | Paměť | Velikost stažení |
|---|---|---|---|
| Parakeet V3 | 0,77 s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81 s | ~700 MB | 827 MB |
| Whisper Small | 1,03 s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18 s | ~1,6 GB | 3 GB |
* Doba načtení a paměť měřeny na Apple M4 Pro, 32 GB.
SenseVoice se načte za méně než sekundu a používá méně paměti než Parakeet. Na 8GB Macu běží pohodlně vedle vašich dalších aplikací.
Proč je SenseVoice rychlejší: Architektura + Runtime
Rozdíl v rychlosti mezi Qwen3-ASR a SenseVoice pochází ze dvou nezávislých faktorů.
Faktor 1: Architektura modelu. Qwen3-ASR je autoregresivní — generuje textové tokeny jeden po druhém, každý závisí na předchozím. SenseVoice používá neautoregresivní (NAR) enkodér, který zpracovává celé audio paralelně. Tento architektonický rozdíl sám o sobě dělá SenseVoice zásadně rychlejším, bez ohledu na hardware.
Faktor 2: Runtime. Naše integrace Qwen3-ASR používala sherpa-onnx, který běžel na CPU. SenseVoice běží přes Apple MLX a směruje výpočty na GPU. Mohl by Qwen3 také běžet na MLX? Ano — ale stále by byl pomalejší než SenseVoice, protože autoregresivní úzké hrdlo je v architektuře, ne v runtime.
| Qwen3-ASR (starý) | SenseVoice (nový) | |
|---|---|---|
| Architektura | Autoregresivní (token po tokenu) | Neautoregresivní (paralelní) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min čínština | 224 sekund | 13,83 sekund |
| Celkové zrychlení | základ | 16,2× rychlejší |
| Kódová základna | 168 MB C framework + 2 249 řádků Swift | 288 řádků Swift Actor |
* Stejný 27minutový čínský podcast, Apple M4 Pro. Zrychlení 16,2× kombinuje architektonické (NAR vs AR) i runtime (GPU vs CPU) vylepšení.
Kód se také zjednodušil. Nová implementace SenseVoice je jediný 288řádkový Swift Actor komunikující přímo s MLX, nahrazující 168MB C framework. Méně kódu, méně chyb, menší aplikace.
Pět jazyků, dobře zvládnutých
SenseVoice se nesnaží dělat vše. Zvládá pět jazyků:
| Jazyk | SenseVoice-Small | Whisper-Large-V3 | Vítěz |
|---|---|---|---|
| Čínština (zh-CN) | 10,78 % CER | 12,55 % CER | SenseVoice (-14 %) |
| Kantonština (yue) | 7,09 % CER | 10,41 % CER | SenseVoice (-32 %) |
| Japonština (ja) | 11,96 % CER | 10,34 % CER | Whisper (mírně) |
| Korejština (ko) | 8,28 % CER | 5,59 % CER | Whisper |
| Angličtina (en) | 14,71 % WER | 9,39 % WER | Whisper (použijte Parakeet) |
* Benchmark CommonVoice, CER = míra chybovosti znaků, WER = míra chybovosti slov. Nižší je lepší. Zdroj: článek FunAudioLLM (2024). Latence inference SenseVoice-Small: 70 ms na 10 s audia (A800 GPU), více než 15× rychlejší než Whisper-Large-V3.
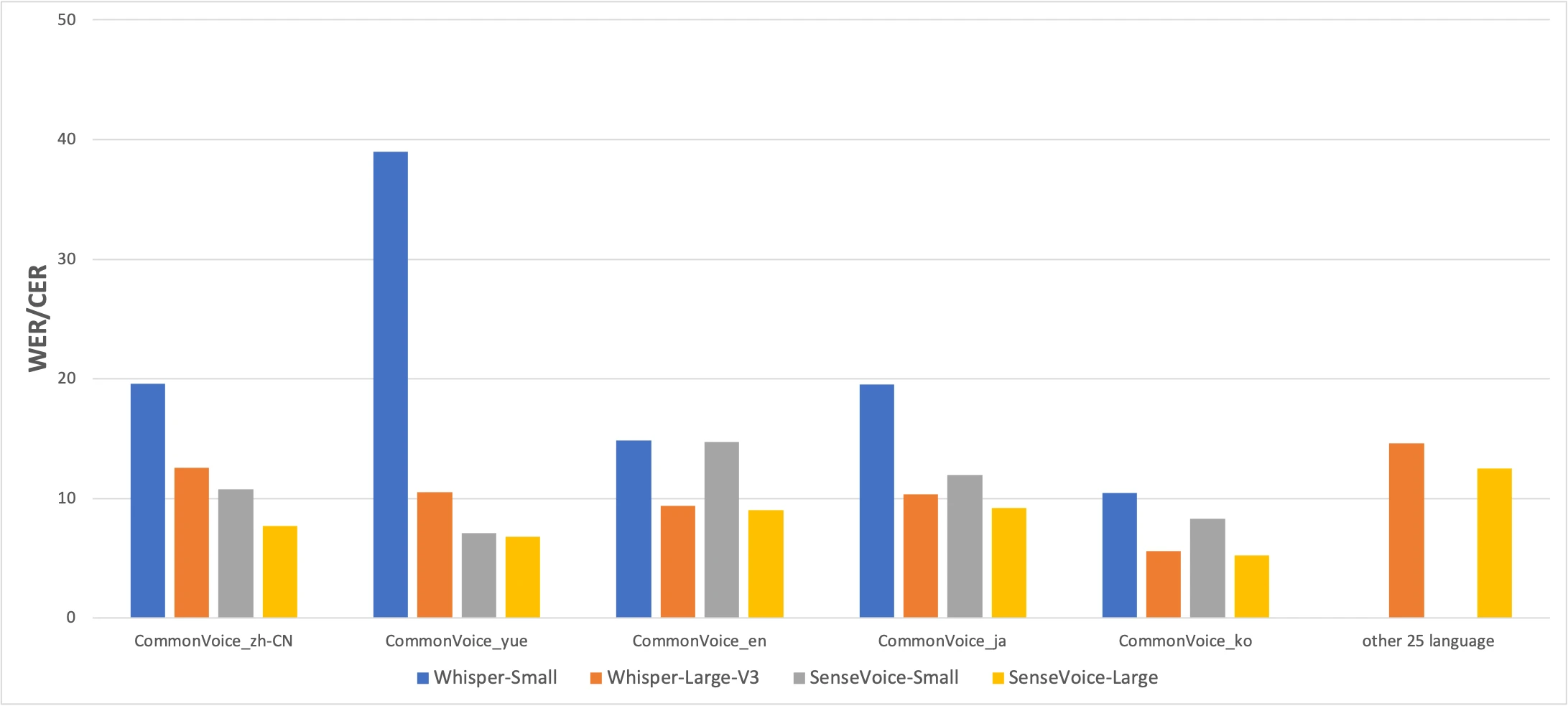
Benchmark CommonVoice: SenseVoice-Small (žlutá) vs Whisper-Small (modrá) vs Whisper-Large-V3 (oranžová). Nižší je lepší. Zdroj: článek FunAudioLLM
Čísla vyprávějí upřímný příběh. SenseVoice překonává Whisper v přesnosti čínštiny a kantonštiny s výrazným náskokem, zatímco Whisper je přesnější pro japonštinu, korejštinu a angličtinu. Ale SenseVoice je více než 15× rychlejší než Whisper-Large-V3. Pro většinu reálného použití záleží na rozdílu v rychlosti víc než na pár procentních bodech přesnosti.
Výsledek kantonštiny stojí za zvláštní zmínku. Whisper-Small dosahuje 38,97 % CER v kantonštině — téměř nepoužitelný. Ani Whisper-Large-V3 zvládne jen 10,41 %. SenseVoice dosahuje 7,09 %. Před SenseVoice neexistoval dobrý způsob, jak lokálně přepisovat kantonštinu na Macu. Pokud mluvíte kantonsky, tento model existuje pro vás.
Přepis korejštiny pomocí SenseVoice: import videa s titulky s časovými značkami
Test v reálném světě: 27minutový čínský podcast
Přepsali jsme 27minutovou epizodu Thirteen Invitations (十三邀), čínského rozhovorového podcastu, pomocí SenseVoice i Whisper Large V3 Turbo na stejném M4 Pro. ElevenLabs Scribe (cloud) sloužil jako reference. Oba modely na zařízení dělají přibližně stejný počet chyb, ale různého druhu:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Čas | 13,83 s | 2 min 4 s |
| Chyby (5min vzorek) | ~15–20 | ~12–15 |
| Nejhorší chyba | 时差→食堂 (časový posun→jídelna) | 西昌→西藏 (město Xichang→Tibet, 4 000 km vedle) |
| Vzor chyb | Záměny homofonů | Geografické/faktické chyby |
* Ruční srovnání s ElevenLabs Scribe (cloudová reference, také ne bezchybná). Oba modely na zařízení správně napsaly „根深蒂固", kde Scribe chyboval.
Srovnatelná přesnost. 9× rychlejší. Pro reálný přepis čínštiny vám SenseVoice dá použitelný přepis dřív, než Whisper dokončí načítání.
Kdy použít který model
Whisper Notes pro Mac nyní obsahuje čtyři řečové modely. Každý je optimalizován pro různé scénáře:
| Potřebujete... | Použijte tento model | Proč |
|---|---|---|
| Angličtinu nebo evropské jazyky, maximální rychlost | Parakeet V3 | 103× reálný čas, nejnižší chybovost. Výchozí. |
| Čínštinu, japonštinu, korejštinu nebo kantonštinu | SenseVoice Small | 52–118× reálný čas. Jediný model s podporou kantonštiny. |
| Kterýkoli z 99+ jazyků (arabština, thajština, ruština atd.) | Whisper Large V3 Turbo | Nejširší jazyková podpora. Pomalejší, ale univerzální. |
| Nižší spotřebu paměti (starší Macy) | Whisper Small | 487 MB paměti. Vhodný pro 8GB Macy s dalšími aplikacemi. |
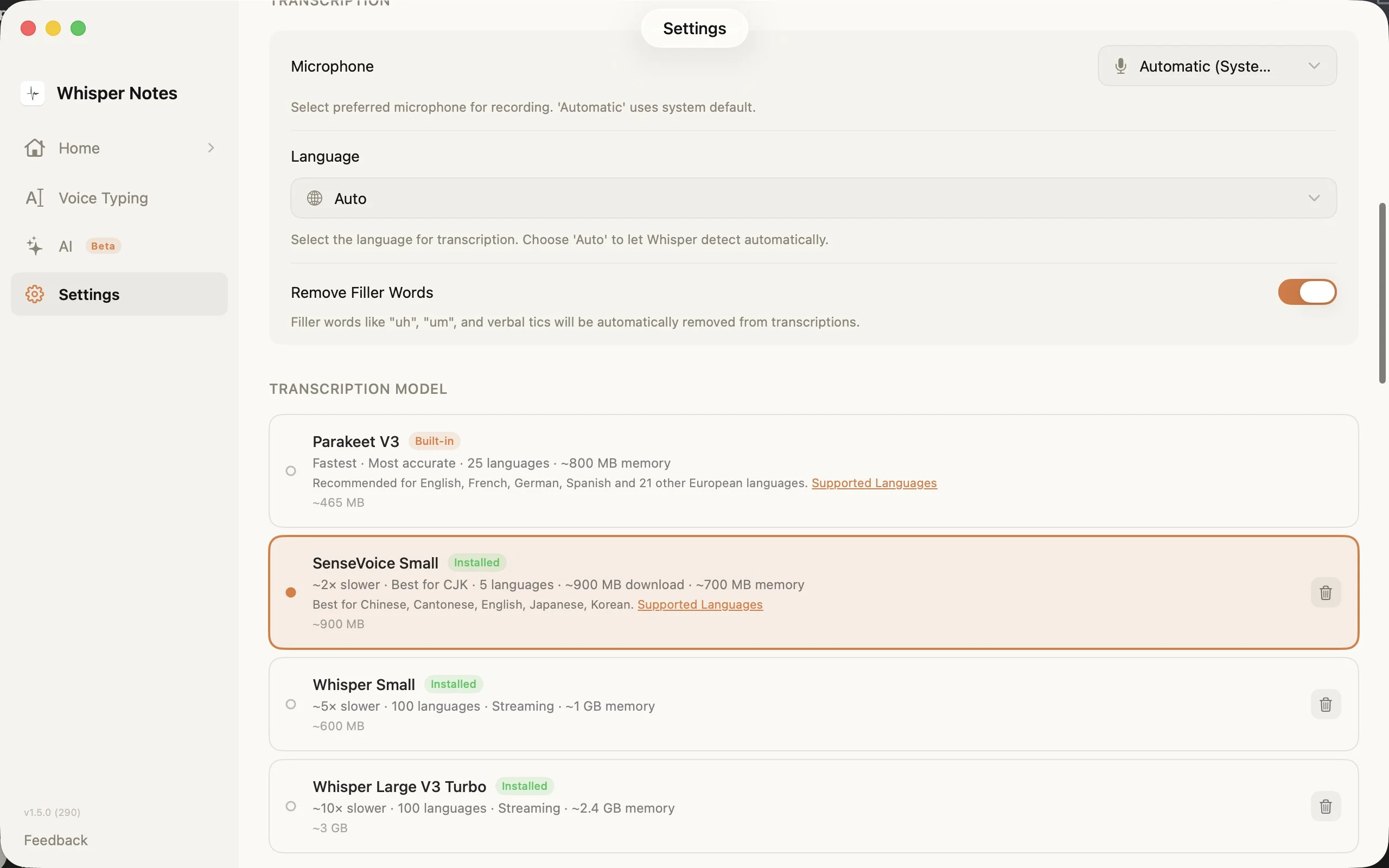
Nastavení → Model přepisu: vyberte správný engine pro svůj jazyk
Výběr modelů v Nastavení zobrazuje všechny čtyři možnosti s velikostmi stažení, počty jazyků a požadavky na paměť. SenseVoice se stáhne při prvním použití (~827 MB) a zůstane na vašem zařízení.
Kompromisy
SenseVoice není univerzální model. Co neumí:
• Pouze 5 jazyků. Pokud potřebujete thajštinu, ruštinu, arabštinu, hindštinu nebo kterýkoli z dalších 90+ jazyků, které Whisper podporuje, zůstaňte u Whisperu.
• Pouze Mac. SenseVoice běží přes Apple MLX, který vyžaduje macOS. Není k dispozici na iPhonu. Uživatelé iOS mají Parakeet (pro evropské jazyky) a Whisper.
• Problém s tichým zvukem. Během velmi krátkých nebo velmi tichých segmentů se SenseVoice může občas vrátit k čínskému výstupu bez ohledu na vybraný jazyk. Ruční nastavení jazyka (místo „Auto") to omezuje.
• Žádné streamování. Na rozdíl od režimu streamování Whisperu zpracovává SenseVoice celé audio po nahrání. U dlouhých souborů automaticky segmentuje v bodech ticha a zobrazuje výsledky postupně.
Jsou to architektonická omezení, ne chyby. Model trénovaný na 5 jazycích zvládá těchto 5 jazyků mimořádně dobře. Podpora 99+ jazyků u Whisperu přichází s pomalejší rychlostí a vyšší chybovostí u každého jednotlivého jazyka.
Vyzkoušejte to
SenseVoice je k dispozici v Whisper Notes pro Mac od verze 1.4.8. Stáhněte ho v Nastavení → Model přepisu → SenseVoice Small (~827 MB). Vyžaduje Mac s Apple Silicon (M1 nebo novější).
Pokud používáte Parakeet V3 a diktujete převážně anglicky, nemusíte přepínat. SenseVoice je pro případy, kdy potřebujete čínštinu, japonštinu, korejštinu nebo kantonštinu — a chcete to rychle.
Kompletní seznam změn: whispernotes.app/changelog
Dotazy nebo zpětná vazba: mac@whispernotes.app