TL;DR — 三款 Mac 模型对比
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 分钟英语 | 2.91s (103×) | 5.8s (52×) | 20.92s (14.3×) |
| 27 分钟中文 | 10.10s (161×) | 13.83s (118×) | 2 min 4s (13.1×) |
| 支持语言 | 25(欧洲语言) | 5(zh, en, ja, ko, yue) | 99+ |
| 下载大小 | 465 MB | 827 MB | 1.5 GB |
| 内存占用 | ~800 MB | ~700 MB | ~1.6 GB |
| 最适用于 | 英语和欧洲语言 | 中文、日语、韩语、粤语 | 其他所有语言(99+) |
* 速度测试基于 Apple M4 Pro, 32 GB。5 分钟英语播客和 27 分钟中文播客。实时倍率 = 音频时长 ÷ 处理时间(越高越快)。SenseVoice 仅限 macOS。iOS 使用 Parakeet(通过 ANE)和 Whisper。
从 1.4.8 版本起,Mac 版 Whisper Notes 搭载 SenseVoice Small 作为中文、日语、韩语和粤语的专用转写引擎。它取代了 Qwen3-ASR,通过 MLX 在 Apple GPU 上运行,而非 CPU——27 分钟的中文播客从 3 分 44 秒缩短到 13.83 秒。
为什么替换 Qwen3-ASR
Qwen3-ASR 是一个不错的模型,支持 30 种语言和 22 种中文方言,中文准确率接近最高水平。但它有一个随音频时长而恶化的问题:速度。
Qwen3 采用自回归架构——和 Whisper 一样,逐帧处理音频,永远无法跳过。27 分钟的中文播客需要 73 秒。能用,但远不是 Parakeet V3 在英语上提供的即时体验。
更深层的问题在基础设施。我们的 Qwen3 集成使用 sherpa-onnx,一个带有 2,249 行 Swift 封装的 C 库,所有计算都走 CPU。GPU 完全闲置。
SenseVoice 同时解决了这两个问题:非自回归架构实现速度提升,Apple MLX 实现 GPU 加速。结果:同样的硬件上 16.2 倍速度提升,代码从 2,249 行减少到 288 行。
基准测试
三个模型在同一台 Apple M4 Pro 上、同样的音频文件、同样的条件下运行。无云端,无网络,纯靠芯片。
| 模型 | 5 分钟英语 | 27 分钟中文 | 速度 (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2.91s | 10.10s | 103–161× |
| SenseVoice Small | 5.8s | 13.83s | 52–118× |
| Whisper Large V3 Turbo | 20.92s | 2 min 4s | 13–14× |
| Qwen3-ASR(已移除) | — | 73s | 4.7× |
SenseVoice 大约是 Parakeet V3 速度的一半——但依然快得惊人。27 分钟的播客在 14 秒内完成。按下转写,等一次呼吸,文字就出来了。
对比 Whisper 的 2 分 4 秒或旧版 Qwen3 的 73 秒。架构比参数量更重要。
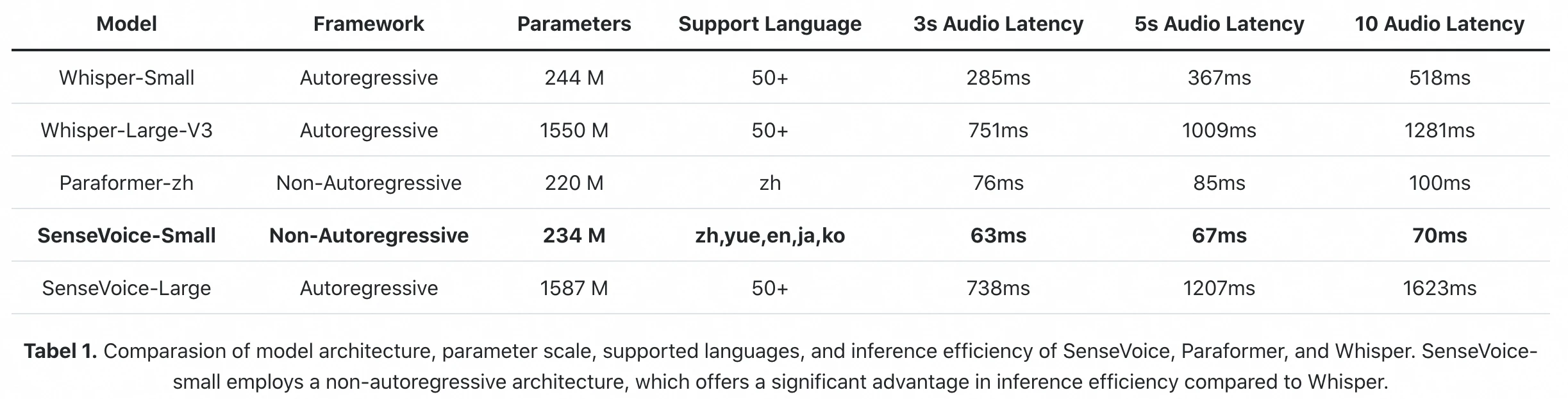
FunAudioLLM 论文官方推理基准测试:SenseVoice-Small 处理 10 秒音频仅需 70ms(A800 GPU)。Whisper-Large-V3 需要 1,281ms。原始推理延迟相差 18 倍。
| 模型 | 加载时间 | 内存占用 | 下载大小 |
|---|---|---|---|
| Parakeet V3 | 0.77s | ~800 MB | 465 MB |
| SenseVoice Small | 0.81s | ~700 MB | 827 MB |
| Whisper Small | 1.03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3.18s | ~1.6 GB | 3 GB |
* 加载时间和内存基于 Apple M4 Pro, 32 GB 测量。
SenseVoice 在一秒内加载完毕,内存占用比 Parakeet 还少。在 8 GB 的 Mac 上也能和其他应用一起流畅运行。
SenseVoice 为什么更快:架构 + 运行时
Qwen3-ASR 和 SenseVoice 之间的速度差距来自两个独立因素。
因素一:模型架构。 Qwen3-ASR 是自回归的——逐个生成 token,每个都依赖前一个。SenseVoice 使用非自回归(NAR)编码器,并行处理整段音频。仅凭这一架构差异,无论运行在什么硬件上,SenseVoice 都从根本上更快。
因素二:运行时。 我们的 Qwen3-ASR 集成使用 sherpa-onnx,在 CPU 上运行。SenseVoice 通过 Apple MLX 运行,将计算路由到 GPU。Qwen3 也能用 MLX 运行吗?能——但它仍然会比 SenseVoice 慢,因为自回归瓶颈在架构而非运行时。
| Qwen3-ASR(旧) | SenseVoice(新) | |
|---|---|---|
| 架构 | 自回归(逐 token) | 非自回归(并行处理) |
| 运行时 | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 分钟中文 | 224 秒 | 13.83 秒 |
| 综合加速 | 基准值 | 快 16.2 倍 |
| 代码量 | 168 MB C 框架 + 2,249 行 Swift | 288 行 Swift Actor |
* 同一段 27 分钟中文播客,Apple M4 Pro。16.2 倍加速同时包含架构(NAR vs AR)和运行时(GPU vs CPU)的改进。
代码也变简单了。新的 SenseVoice 实现是一个 288 行的 Swift Actor,直接与 MLX 通信,替代了 168 MB 的 C 框架。代码更少,bug 更少,应用更小。
五种语言,做到极致
SenseVoice 不追求面面俱到。它专注于五种语言:
| 语言 | SenseVoice-Small | Whisper-Large-V3 | 胜者 |
|---|---|---|---|
| 中文 (zh-CN) | 10.78% CER | 12.55% CER | SenseVoice (-14%) |
| 粤语 (yue) | 7.09% CER | 10.41% CER | SenseVoice (-32%) |
| 日语 (ja) | 11.96% CER | 10.34% CER | Whisper(略优) |
| 韩语 (ko) | 8.28% CER | 5.59% CER | Whisper |
| 英语 (en) | 14.71% WER | 9.39% WER | Whisper(建议用 Parakeet) |
* CommonVoice 基准测试,CER = 字符错误率,WER = 单词错误率。越低越好。来源:FunAudioLLM 论文 (2024)。SenseVoice-Small 推理延迟:10 秒音频 70ms(A800 GPU),比 Whisper-Large-V3 快 15 倍以上。
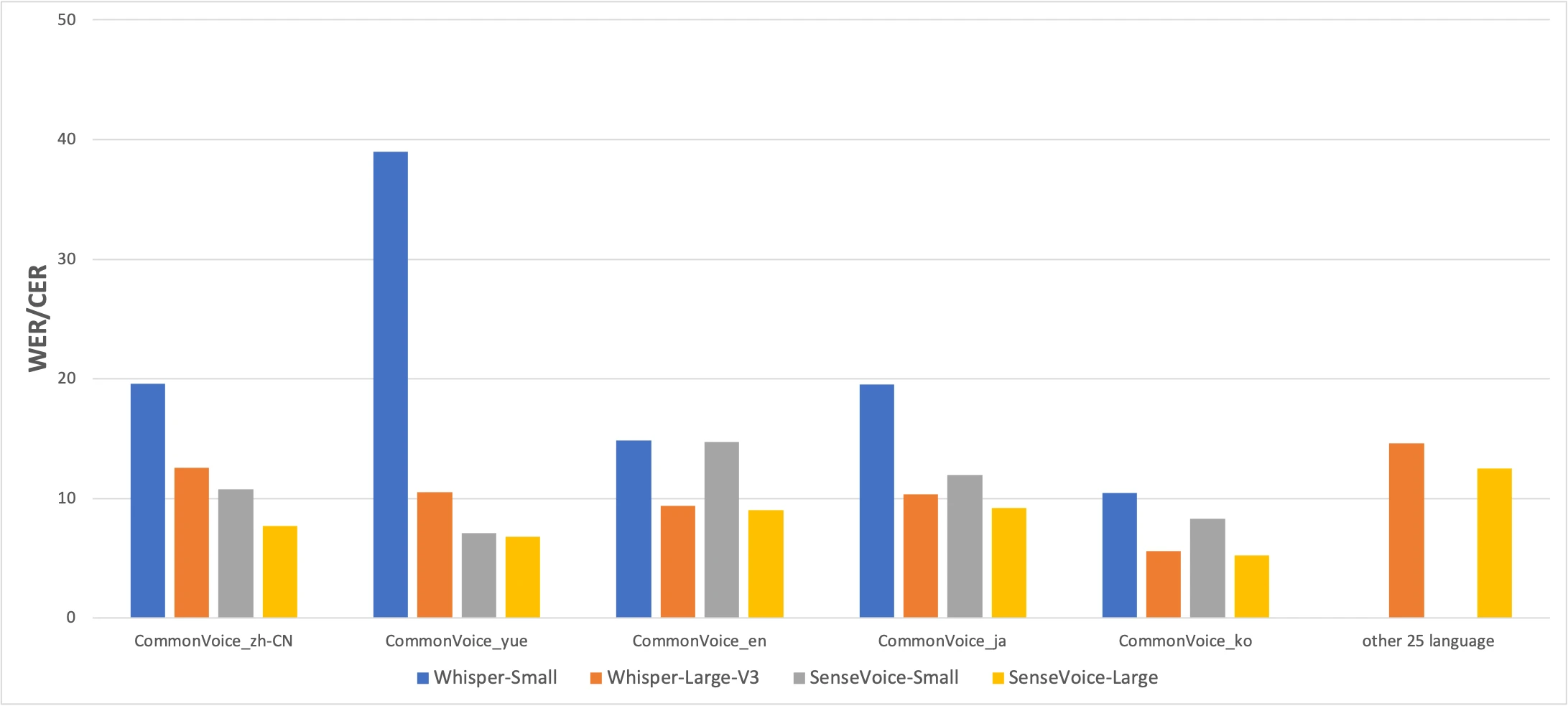
CommonVoice 基准:SenseVoice-Small(黄色)vs Whisper-Small(蓝色)vs Whisper-Large-V3(橙色)。越低越好。来源:FunAudioLLM 论文
数据说明了一切。SenseVoice 在中文和粤语准确率上大幅领先 Whisper,而 Whisper 在日语、韩语和英语上更准确。但 SenseVoice 比 Whisper-Large-V3 快 15 倍以上。在实际使用中,速度差异往往比几个百分点的准确率更重要。
粤语的结果值得单独说一下。Whisper-Small 在粤语上的 CER 高达 38.97%——几乎不能用。即便是 Whisper-Large-V3 也只做到 10.41%。SenseVoice 达到了 7.09%。在 SenseVoice 之前,没有好的方法在 Mac 上本地转写粤语。如果你说粤语,这个模型就是为你而生的。
SenseVoice 韩语转写:带时间戳字幕的视频导入
实测:27 分钟中文播客
我们用 SenseVoice 和 Whisper Large V3 Turbo 在同一台 M4 Pro 上转写了一期 27 分钟的《十三邀》(Thirteen Invitations),一档中文访谈播客。以 ElevenLabs Scribe(云端)作为参考。两个本地模型的错误数量大致相当,但类型不同:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| 耗时 | 13.83s | 2 min 4s |
| 错误数(5 分钟样本) | ~15–20 | ~12–15 |
| 最严重错误 | 时差→食堂 | 西昌→西藏(Xīchāng→Xīzàng,相差 4,000 公里) |
| 错误模式 | 同音字混淆 | 地理/事实性错误 |
* 与 ElevenLabs Scribe(云端参考,也并非完美)手动对比。两个本地模型都正确写出了"根深蒂固",而 Scribe 写错了。
准确率相当。速度快 9 倍。在实际中文转写场景中,Whisper 还没加载完,SenseVoice 已经给你一份可用的文稿了。
什么时候用哪个模型
Mac 版 Whisper Notes 现已搭载四个语音模型,各自针对不同场景优化:
| 你的需求 | 推荐模型 | 原因 |
|---|---|---|
| 英语或欧洲语言,追求极致速度 | Parakeet V3 | 103× 实时,最低错误率。默认选择。 |
| 中文、日语、韩语或粤语 | SenseVoice Small | 52–118× 实时。唯一支持粤语的模型。 |
| 99+ 语言中的任意一种(阿拉伯语、泰语、俄语等) | Whisper Large V3 Turbo | 语言覆盖最广。速度较慢但通用性强。 |
| 低内存需求(老款 Mac) | Whisper Small | 487 MB 内存。适合 8 GB Mac。 |
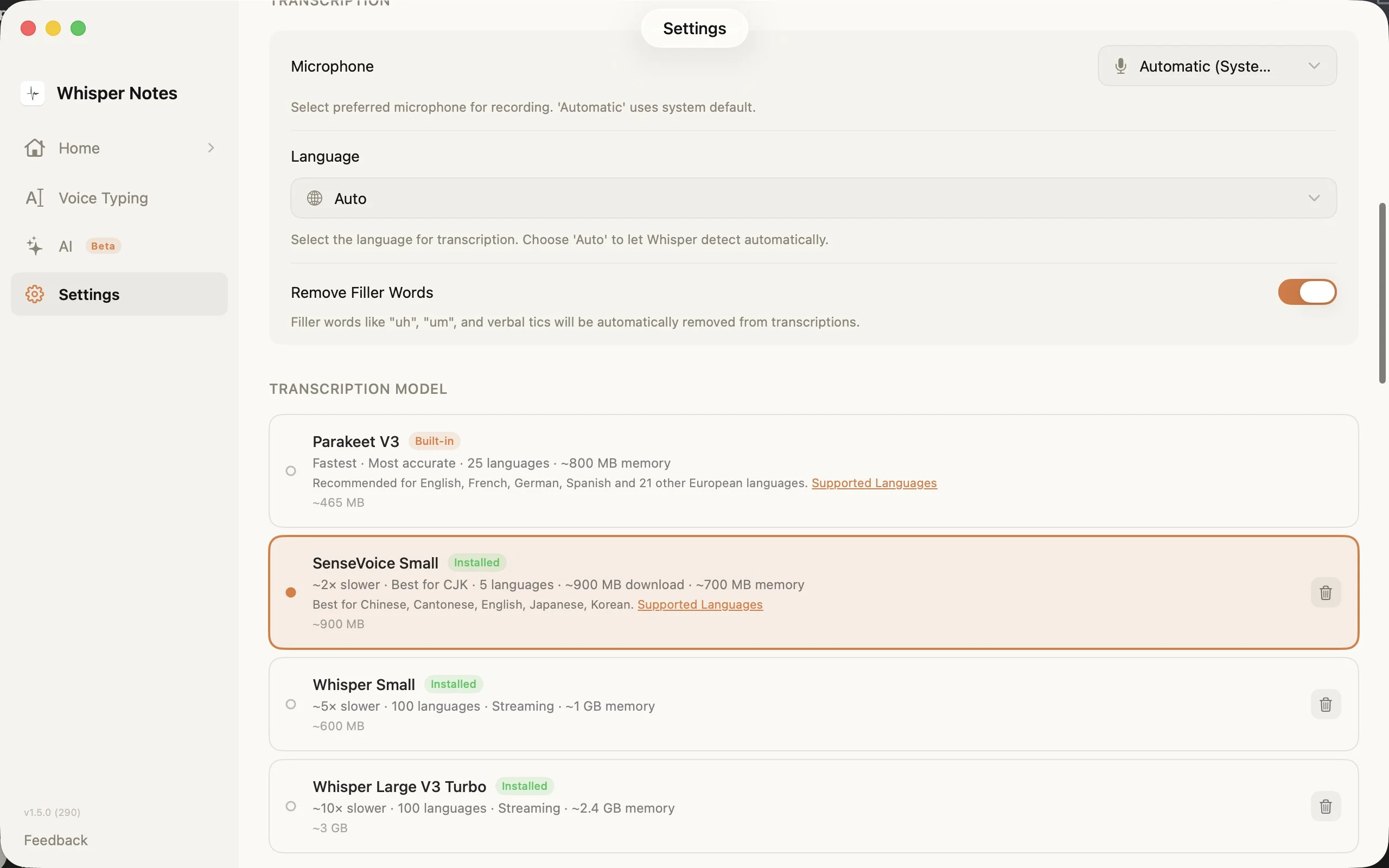
设置 → 转写模型:为你的语言选择合适的引擎
设置中的模型选择器展示了全部四个选项,包含下载大小、支持语言数和内存需求。SenseVoice 在首次使用时下载(约 827 MB),之后保存在本地。
权衡取舍
SenseVoice 不是万能模型。以下是它做不到的事:
• 仅支持 5 种语言。 如果你需要泰语、俄语、阿拉伯语、印地语或 Whisper 支持的其他 90 多种语言,请继续使用 Whisper。
• 仅限 Mac。 SenseVoice 通过 Apple MLX 运行,需要 macOS。iPhone 上不可用。iOS 用户可使用 Parakeet(欧洲语言)和 Whisper。
• 低音量音频特性。 在非常短或非常安静的片段中,SenseVoice 有时会无视所选语言而输出中文。手动设置语言(而非"自动")可以减少这种情况。
• 不支持流式处理。 与 Whisper 的流式模式不同,SenseVoice 在录音结束后处理完整音频。对于长文件,它会在静音处自动分段,逐步显示结果。
这些是架构层面的限制,不是 bug。一个用 5 种语言训练的模型,把这 5 种语言做到了极致。Whisper 的 99+ 语言支持意味着更慢的速度和更高的单语言错误率。
试试看
SenseVoice 已在 Mac 版 Whisper Notes v1.4.8 及更高版本中提供。前往 设置 → 转写模型 → SenseVoice Small(约 827 MB)下载。需要 Apple Silicon Mac(M1 或更新)。
如果你正在使用 Parakeet V3 且主要用英语听写,无需切换。SenseVoice 适用于当你需要中文、日语、韩语或粤语——并且希望快速完成。
完整更新日志:whispernotes.app/changelog
问题或反馈:mac@whispernotes.app