RESUMO — Três modelos Mac comparados
| Parakeet V3 | SenseVoice Small | Whisper Large V3 Turbo | |
|---|---|---|---|
| 5 min inglês | 2,91s (103×) | 5,8s (52×) | 20,92s (14,3×) |
| 27 min chinês | 10,10s (161×) | 13,83s (118×) | 2 min 4s (13,1×) |
| Idiomas | 25 (europeus) | 5 (zh, en, ja, ko, yue) | 99+ |
| Download | 465 MB | 827 MB | 1,5 GB |
| Memória | ~800 MB | ~700 MB | ~1,6 GB |
| Ideal para | Inglês & europeu | Chinês, japonês, coreano, cantonês | Tudo o resto (99+ idiomas) |
* Benchmarks de velocidade no Apple M4 Pro, 32 GB. Podcast em inglês de 5 minutos e podcast em chinês de 27 minutos. Fator de tempo real = duração do áudio ÷ tempo de processamento (maior = mais rápido). SenseVoice é apenas para macOS. O iOS utiliza Parakeet (via ANE) e Whisper.
A partir da versão 1.4.8, o Whisper Notes para Mac inclui o SenseVoice Small como motor dedicado para transcrição de chinês, japonês, coreano e cantonês. Substitui o Qwen3-ASR e funciona na GPU da Apple via MLX em vez da CPU — processando um podcast em chinês de 27 minutos em 13,83 segundos em vez de 3 minutos e 44 segundos.
Por que substituímos o Qwen3-ASR
O Qwen3-ASR era um modelo sólido. Suportava 30 idiomas mais 22 dialetos chineses, e a sua precisão para chinês estava próxima do estado da arte. Mas tinha um problema que piorava com a duração do áudio: velocidade.
O Qwen3 usava uma arquitetura autorregressiva — a mesma abordagem do Whisper, processando áudio frame a frame, sem nunca avançar. Num podcast em chinês de 27 minutos, demorava 73 segundos. Utilizável, mas não a experiência de resultado instantâneo que o Parakeet V3 oferece para inglês.
O problema mais profundo era a nossa infraestrutura. A nossa integração do Qwen3 usava sherpa-onnx, uma biblioteca C com um wrapper Swift de 2.249 linhas que encaminhava tudo pelos núcleos da CPU. A GPU ficava inativa enquanto a CPU do seu Mac fazia todo o trabalho.
O SenseVoice resolveu ambos os problemas. Arquitetura não autorregressiva para velocidade. Apple MLX para aceleração GPU. O resultado: uma melhoria de velocidade de 16,2× no mesmo hardware, com um código reduzido de 2.249 para 288 linhas.
O benchmark
Os três modelos a funcionar no mesmo Apple M4 Pro, mesmos ficheiros de áudio, mesmas condições. Sem cloud. Sem internet. Apenas silício.
| Modelo | 5 min inglês | 27 min chinês | Velocidade (RTFx) |
|---|---|---|---|
| Parakeet V3 | 2,91s | 10,10s | 103–161× |
| SenseVoice Small | 5,8s | 13,83s | 52–118× |
| Whisper Large V3 Turbo | 20,92s | 2 min 4s | 13–14× |
| Qwen3-ASR (removido) | — | 73s | 4,7× |
O SenseVoice é aproximadamente metade da velocidade do Parakeet V3 — mas continua extraordinariamente rápido. Um podcast de 27 minutos fica pronto em menos de 14 segundos. Carrega em transcrever, espera um instante, e o texto está lá.
Compare isso com o Whisper a 2 minutos e 4 segundos, ou o antigo Qwen3 a 73 segundos. A arquitetura importa mais do que a contagem de parâmetros.
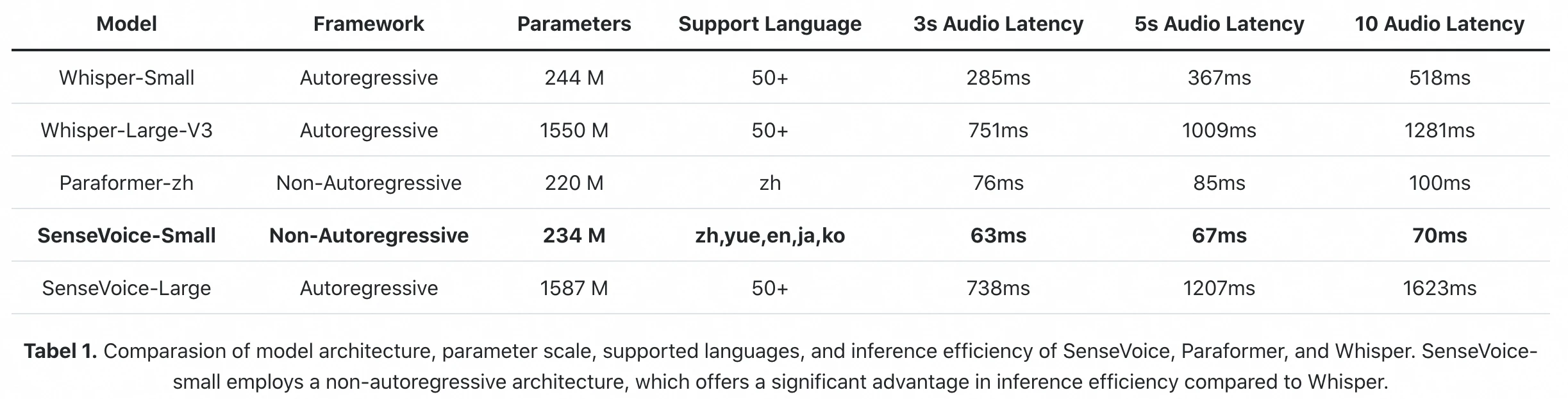
Benchmark oficial de inferência do paper FunAudioLLM: SenseVoice-Small processa 10s de áudio em 70ms (GPU A800). Whisper-Large-V3 demora 1.281ms. É uma diferença de 18× na latência de inferência pura.
| Modelo | Tempo de carregamento | Memória | Tamanho do download |
|---|---|---|---|
| Parakeet V3 | 0,77s | ~800 MB | 465 MB |
| SenseVoice Small | 0,81s | ~700 MB | 827 MB |
| Whisper Small | 1,03s | ~487 MB | 600 MB |
| Whisper Large V3 Turbo | 3,18s | ~1,6 GB | 3 GB |
* Tempo de carregamento e memória medidos no Apple M4 Pro, 32 GB.
O SenseVoice carrega em menos de um segundo e usa menos memória do que o Parakeet. Num Mac de 8 GB, funciona confortavelmente ao lado das suas outras aplicações.
Por que o SenseVoice é mais rápido: arquitetura + runtime
A diferença de velocidade entre o Qwen3-ASR e o SenseVoice provém de dois fatores independentes.
Fator 1: Arquitetura do modelo. O Qwen3-ASR é autorregressivo — gera texto token a token, cada um dependendo do anterior. O SenseVoice usa um codificador não autorregressivo (NAR) que processa todo o áudio em paralelo. Esta diferença arquitetural por si só torna o SenseVoice fundamentalmente mais rápido, independentemente do hardware utilizado.
Fator 2: Runtime. A nossa integração do Qwen3-ASR usava sherpa-onnx, que funcionava na CPU. O SenseVoice funciona através do Apple MLX, encaminhando os cálculos para a GPU. O Qwen3 poderia também funcionar no MLX? Sim — mas continuaria a ser mais lento do que o SenseVoice porque o gargalo autorregressivo está na arquitetura, não no runtime.
| Qwen3-ASR (antigo) | SenseVoice (novo) | |
|---|---|---|
| Arquitetura | Autorregressiva (token a token) | Não autorregressiva (paralela) |
| Runtime | sherpa-onnx (CPU) | Apple MLX (GPU) |
| 27 min chinês | 224 segundos | 13,83 segundos |
| Aceleração combinada | referência | 16,2× mais rápido |
| Código fonte | Framework C de 168 MB + 2.249 linhas Swift | 288 linhas Swift Actor |
* Mesmo podcast chinês de 27 minutos, Apple M4 Pro. A aceleração de 16,2× combina melhorias tanto arquiteturais (NAR vs AR) quanto de runtime (GPU vs CPU).
O código também ficou mais simples. A nova implementação do SenseVoice é um único Swift Actor de 288 linhas que comunica diretamente com o MLX, substituindo um framework C de 168 MB. Menos código, menos bugs, aplicação mais leve.
Cinco idiomas, bem feitos
O SenseVoice não tenta fazer tudo. Suporta cinco idiomas:
| Idioma | SenseVoice-Small | Whisper-Large-V3 | Vencedor |
|---|---|---|---|
| Chinês (zh-CN) | 10,78% CER | 12,55% CER | SenseVoice (-14%) |
| Cantonês (yue) | 7,09% CER | 10,41% CER | SenseVoice (-32%) |
| Japonês (ja) | 11,96% CER | 10,34% CER | Whisper (ligeiro) |
| Coreano (ko) | 8,28% CER | 5,59% CER | Whisper |
| Inglês (en) | 14,71% WER | 9,39% WER | Whisper (use Parakeet) |
* Benchmark CommonVoice, CER = taxa de erro por caractere, WER = taxa de erro por palavra. Menor é melhor. Fonte: paper FunAudioLLM (2024). Latência de inferência do SenseVoice-Small: 70ms por 10s de áudio (GPU A800), mais de 15× mais rápido que o Whisper-Large-V3.
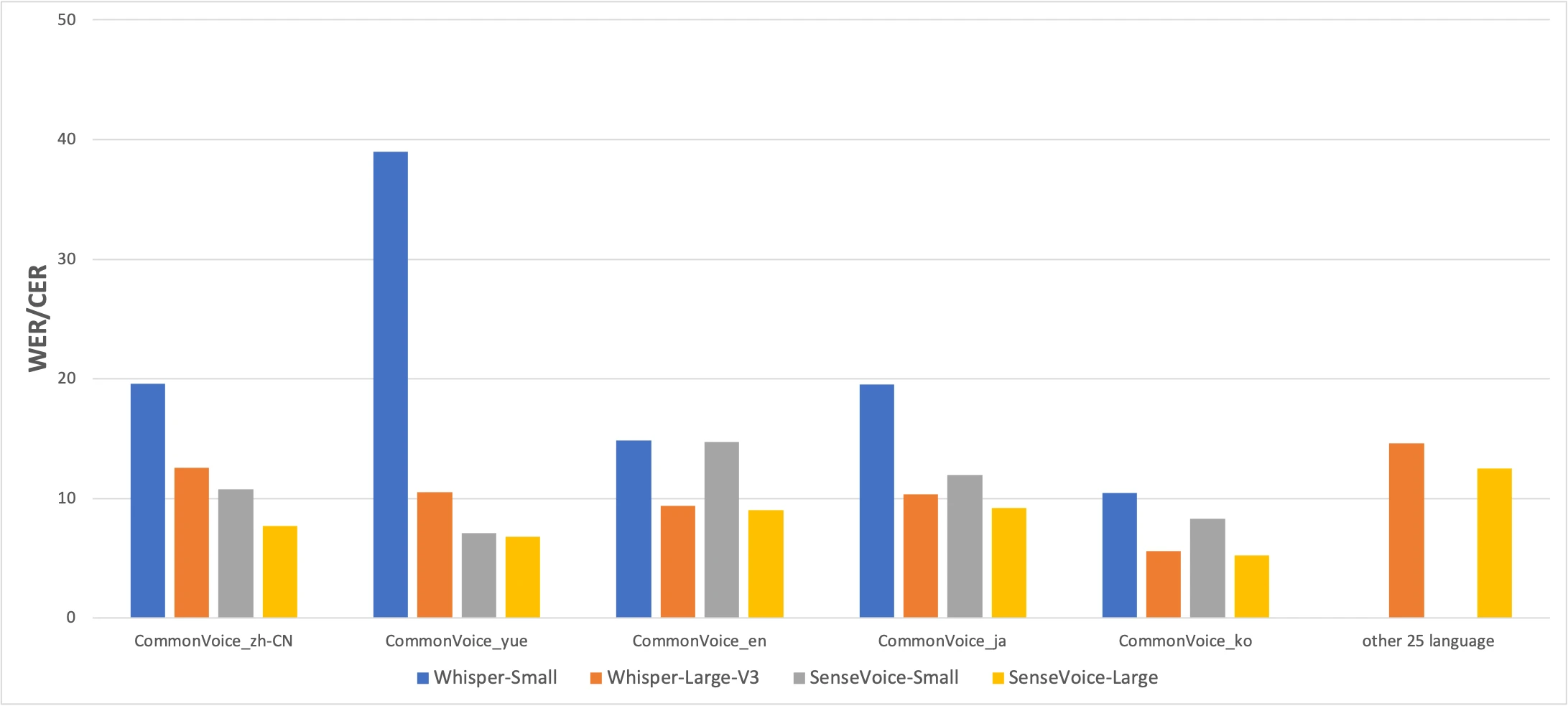
Benchmark CommonVoice: SenseVoice-Small (amarelo) vs Whisper-Small (azul) vs Whisper-Large-V3 (laranja). Menor é melhor. Fonte: paper FunAudioLLM
Os números contam uma história honesta. O SenseVoice supera o Whisper em precisão para chinês e cantonês por uma margem significativa, enquanto o Whisper é mais preciso para japonês, coreano e inglês. Mas o SenseVoice é mais de 15× mais rápido que o Whisper-Large-V3. Para a maioria dos usos reais, a diferença de velocidade importa mais do que alguns pontos percentuais de precisão.
O resultado do cantonês merece destaque especial. O Whisper-Small obtém 38,97% de CER em cantonês — praticamente inutilizável. Mesmo o Whisper-Large-V3 consegue apenas 10,41%. O SenseVoice atinge 7,09%. Antes do SenseVoice, não existia uma boa forma de transcrever cantonês localmente num Mac. Se fala cantonês, este modelo foi criado para si.
Transcrição coreana com SenseVoice: importação de vídeo com legendas temporizadas
Teste no mundo real: podcast chinês de 27 minutos
Transcrevemos um episódio de 27 minutos de Thirteen Invitations (十三邀), um podcast chinês de entrevistas, com SenseVoice e Whisper Large V3 Turbo no mesmo M4 Pro. O ElevenLabs Scribe (cloud) serviu como referência. Ambos os modelos no dispositivo cometem aproximadamente o mesmo número de erros, mas de tipos diferentes:
| SenseVoice | Whisper Large V3 | |
|---|---|---|
| Tempo | 13,83s | 2 min 4s |
| Erros (amostra de 5 min) | ~15–20 | ~12–15 |
| Pior erro | 时差→食堂 (fuso horário→cantina) | 西昌→西藏 (cidade de Xichang→Tibete, 4.000 km de diferença) |
| Padrão de erros | Trocas de homófonos | Erros geográficos/factuais |
* Comparação manual com ElevenLabs Scribe (referência cloud, também imperfeita). Ambos os modelos no dispositivo escreveram corretamente «根深蒂固» onde o Scribe errou.
Precisão comparável. 9× mais rápido. Para transcrição de chinês no mundo real, o SenseVoice entrega-lhe uma transcrição utilizável antes do Whisper acabar de carregar.
Quando usar qual modelo
O Whisper Notes para Mac agora inclui quatro modelos de voz. Cada um é otimizado para cenários diferentes:
| Precisa de... | Use este modelo | Porquê |
|---|---|---|
| Inglês ou idiomas europeus, velocidade máxima | Parakeet V3 | 103× tempo real, menor taxa de erro. O predefinido. |
| Chinês, japonês, coreano ou cantonês | SenseVoice Small | 52–118× tempo real. Único modelo com suporte a cantonês. |
| Qualquer um dos 99+ idiomas (árabe, tailandês, russo, etc.) | Whisper Large V3 Turbo | Maior suporte de idiomas. Mais lento mas universal. |
| Menor uso de memória (Macs mais antigos) | Whisper Small | 487 MB de memória. Bom para Macs de 8 GB com outras apps abertas. |
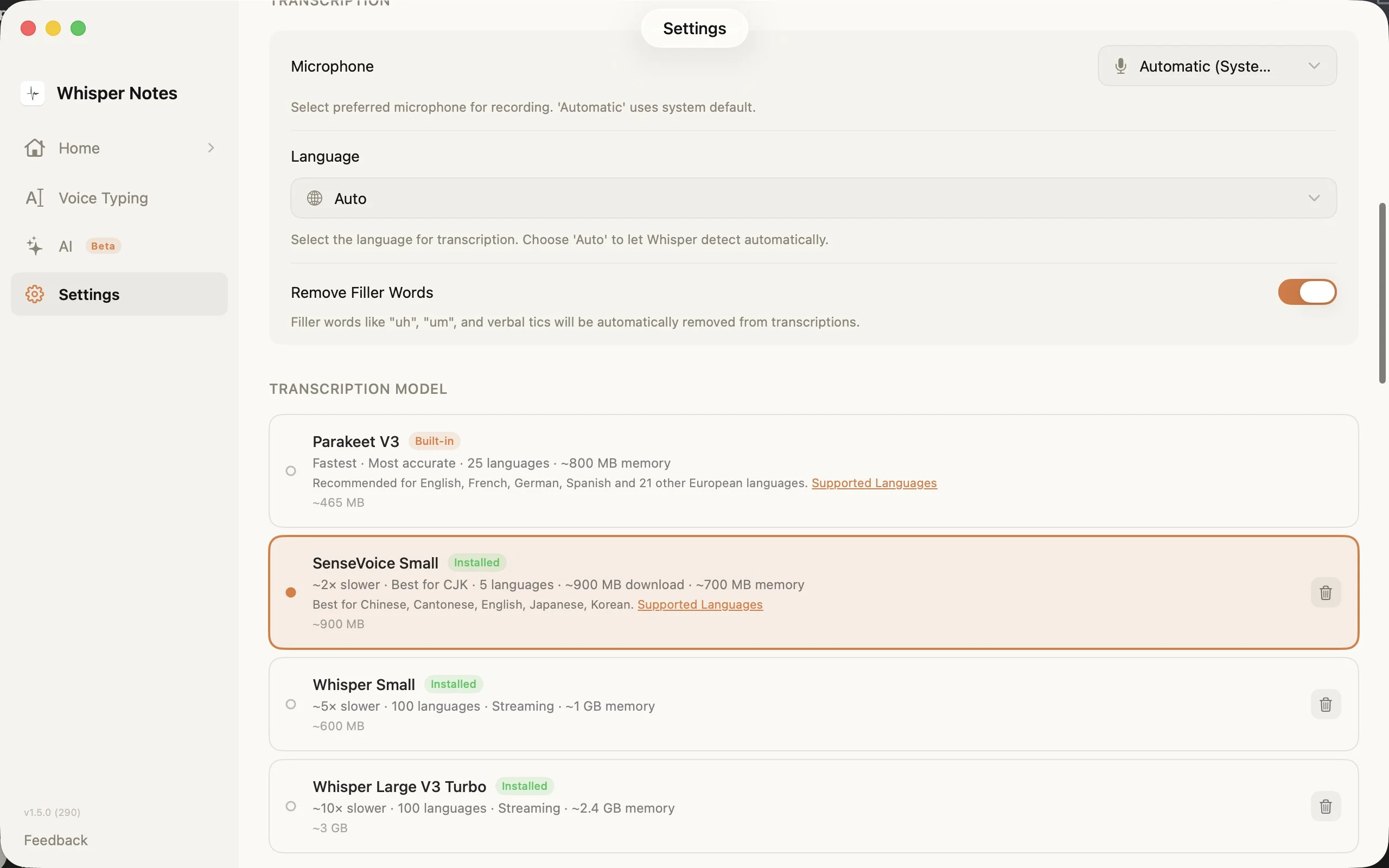
Definições → Modelo de transcrição: escolha o motor certo para o seu idioma
O seletor de modelos nas Definições mostra as quatro opções com tamanhos de download, número de idiomas e requisitos de memória. O SenseVoice é descarregado na primeira utilização (~827 MB) e permanece no seu dispositivo.
As limitações
O SenseVoice não é um modelo universal. Eis o que não consegue fazer:
• Apenas 5 idiomas. Se precisa de tailandês, russo, árabe, hindi ou qualquer dos outros 90+ idiomas suportados pelo Whisper, fique com o Whisper.
• Apenas Mac. O SenseVoice funciona via Apple MLX, que requer macOS. Não está disponível no iPhone. Os utilizadores de iOS têm o Parakeet (para idiomas europeus) e o Whisper.
• Particularidade com áudio silencioso. Durante segmentos muito curtos ou muito silenciosos, o SenseVoice pode por vezes reverter para saída em chinês independentemente do idioma selecionado. Definir o idioma manualmente (em vez de «Auto») reduz este comportamento.
• Sem streaming. Ao contrário do modo streaming do Whisper, o SenseVoice processa o áudio completo após a gravação. Para ficheiros longos, segmenta automaticamente nos pontos de silêncio e mostra resultados progressivamente.
Estas são restrições arquiteturais, não bugs. Um modelo treinado em 5 idiomas domina esses 5 idiomas excecionalmente bem. O suporte de 99+ idiomas do Whisper acarreta menor velocidade e taxas de erro mais elevadas em cada idioma individual.
Experimente
O SenseVoice está disponível no Whisper Notes para Mac v1.4.8 e posteriores. Descarregue-o em Definições → Modelo de transcrição → SenseVoice Small (~827 MB). Requer um Mac com Apple Silicon (M1 ou posterior).
Se usa o Parakeet V3 e dita principalmente em inglês, não precisa de mudar. O SenseVoice é para quando precisa de chinês, japonês, coreano ou cantonês — e quer que seja rápido.
Registo de alterações completo: whispernotes.app/changelog
Questões ou feedback: mac@whispernotes.app